
PythonでeBayにおいて販売されている商品(オークション・競売)の価格を自動で取得してみます。
なお、今回はrequestsモジュール、bs4(BeautifulSoup4)モジュール、Pandasモジュールを使います。これらはPythonの標準ライブラリではないので、事前にインストールしておく必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■実際にeBay(USA)で販売されている商品の価格を調べてみる
まずは、eBay(USA)(https://www.ebay.com/)にアクセスし、検索バーで商品を入力します。今回は「Canon m50」というカメラ商品の価格を表示してみます。

検索バーに入力後、「Search」ボタンをクリックすると、上記のような商品の検索結果が表示されます。
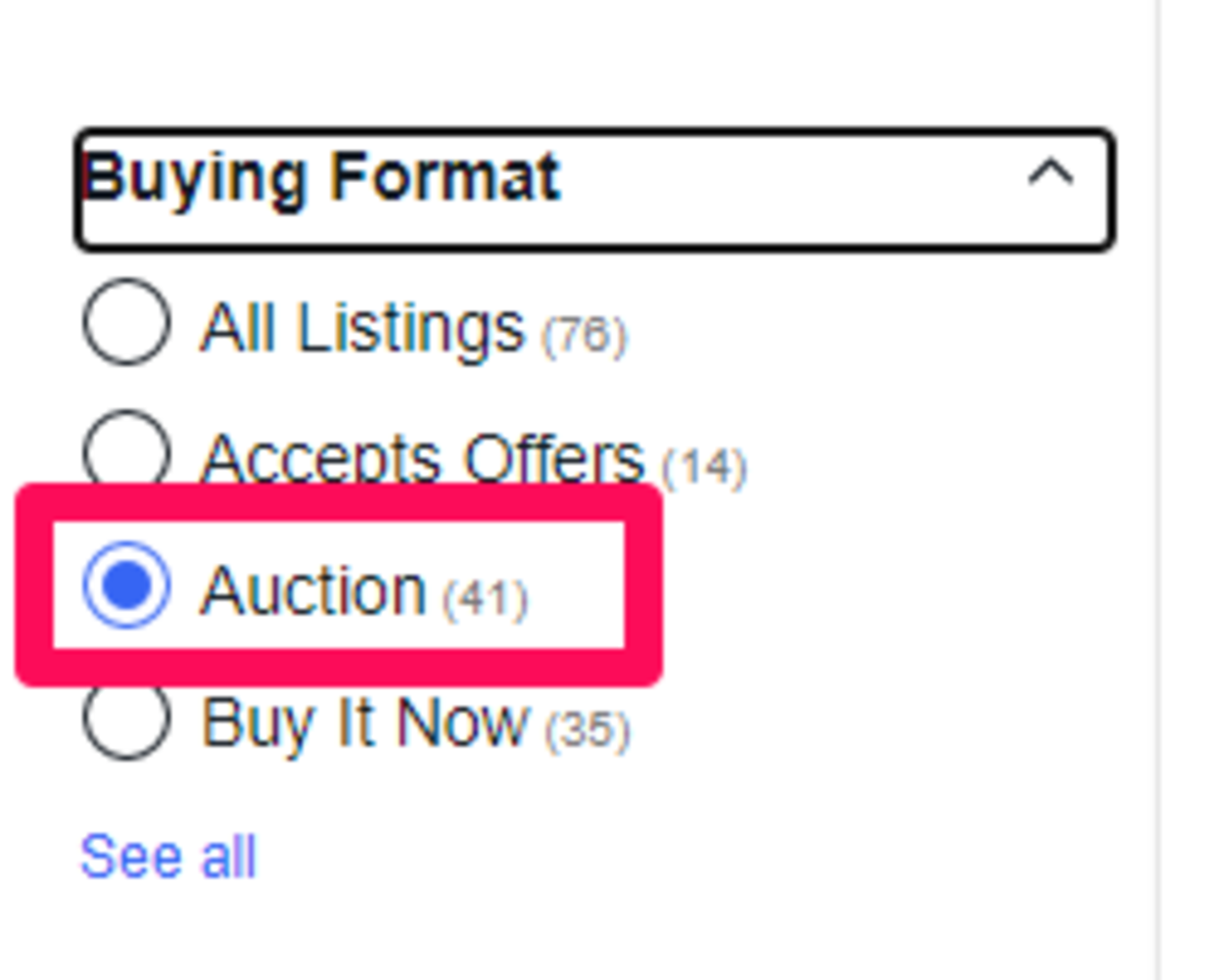
検索結果の左側メニューに「Buying Format(購入フォーマット)」という項目がありますので、項目内から「Auction(オークション・競売)」を選択します。
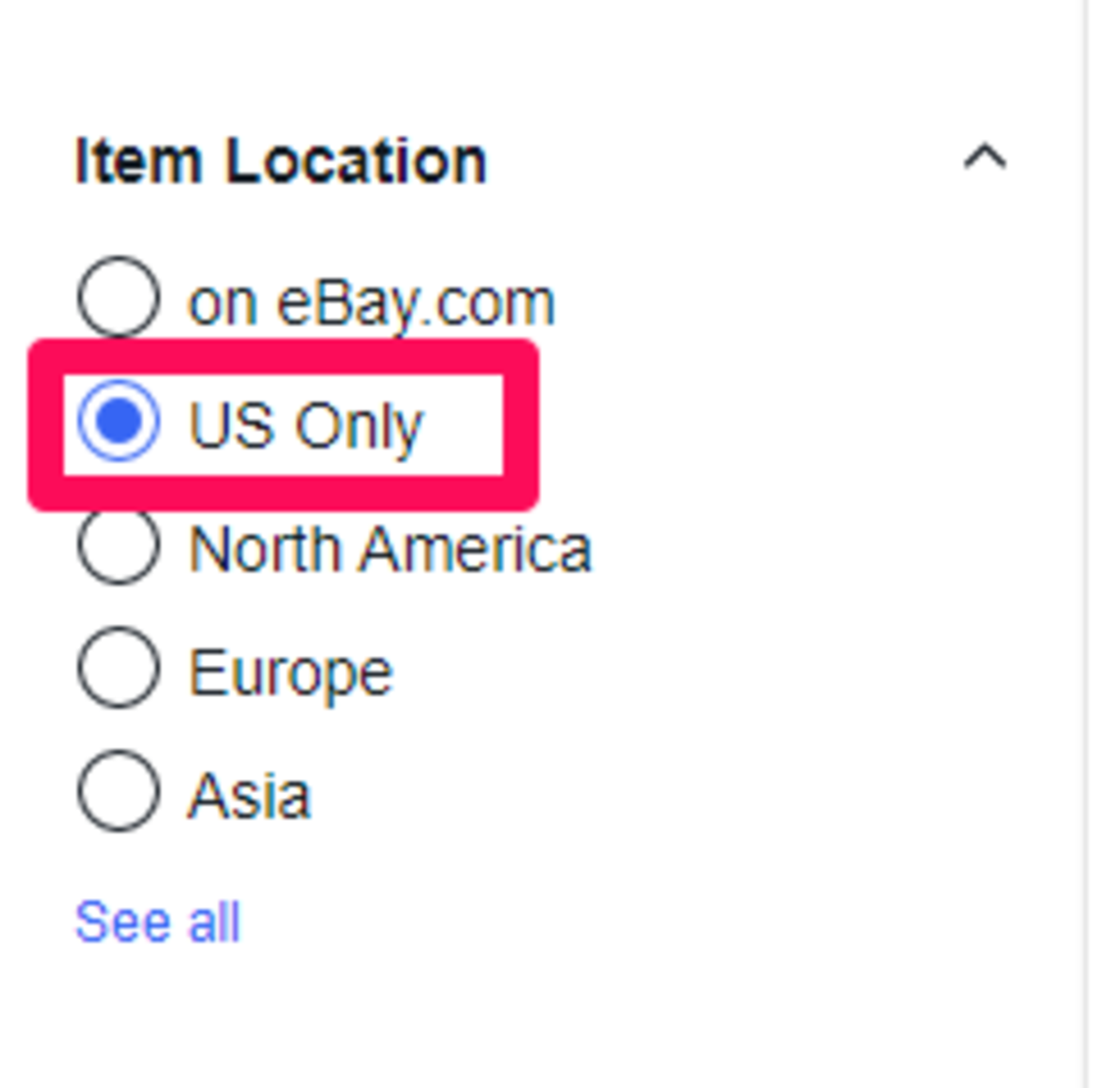
選択後、左側メニューから「ltem Location(アイテム・商品の場所」という項目がありますので、今回は「US Only」で”アメリカのみ”に限定した商品の価格を調べてみます。
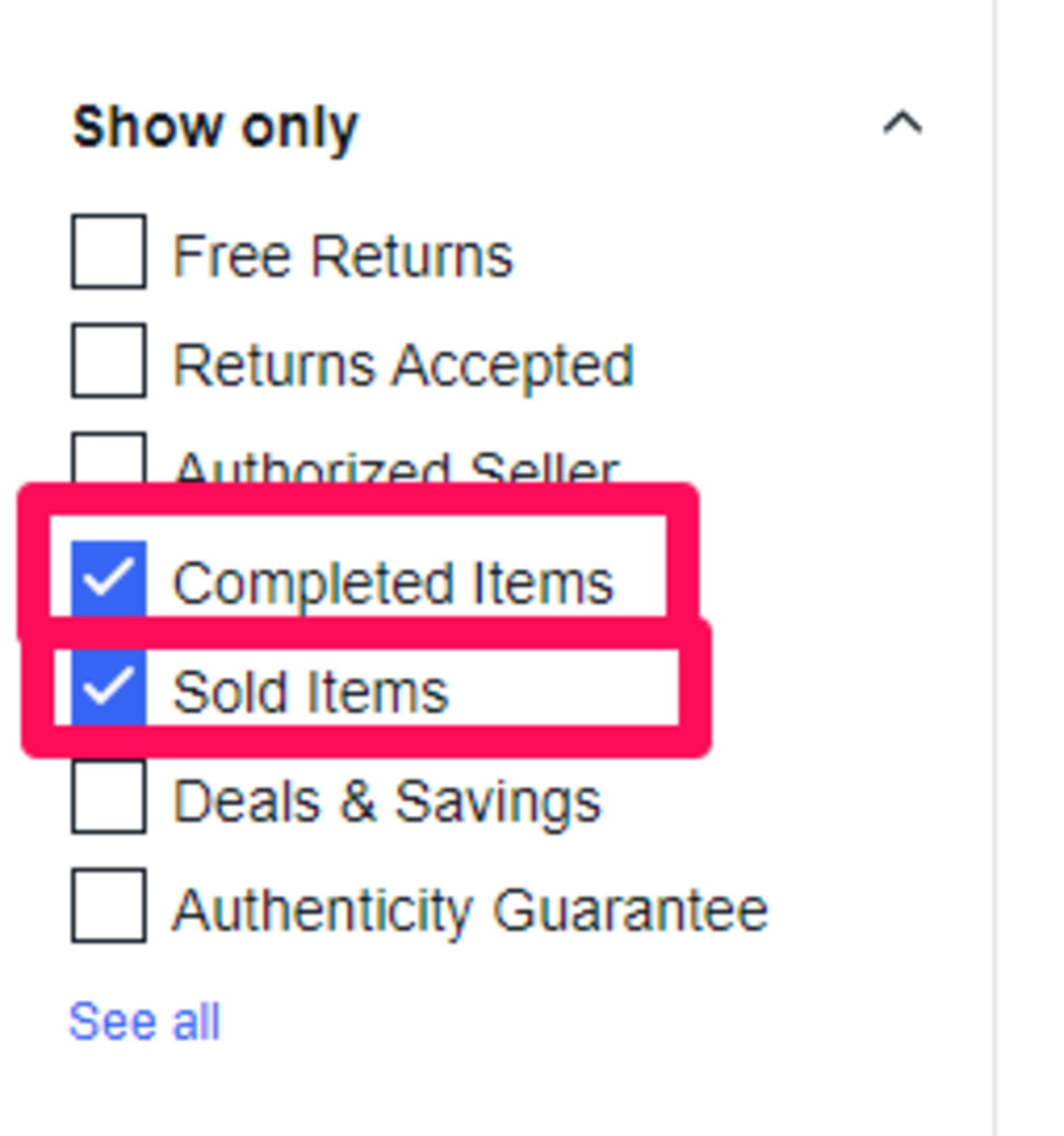
次に左側メニューから「Show only(表示のみ)」という項目がありますので、項目内の「Completed Items(入札が完了(終了)した商品・アイテム)」と、「Sold Items(売れた商品)」を選択して、この2つのみを表示させてみます。
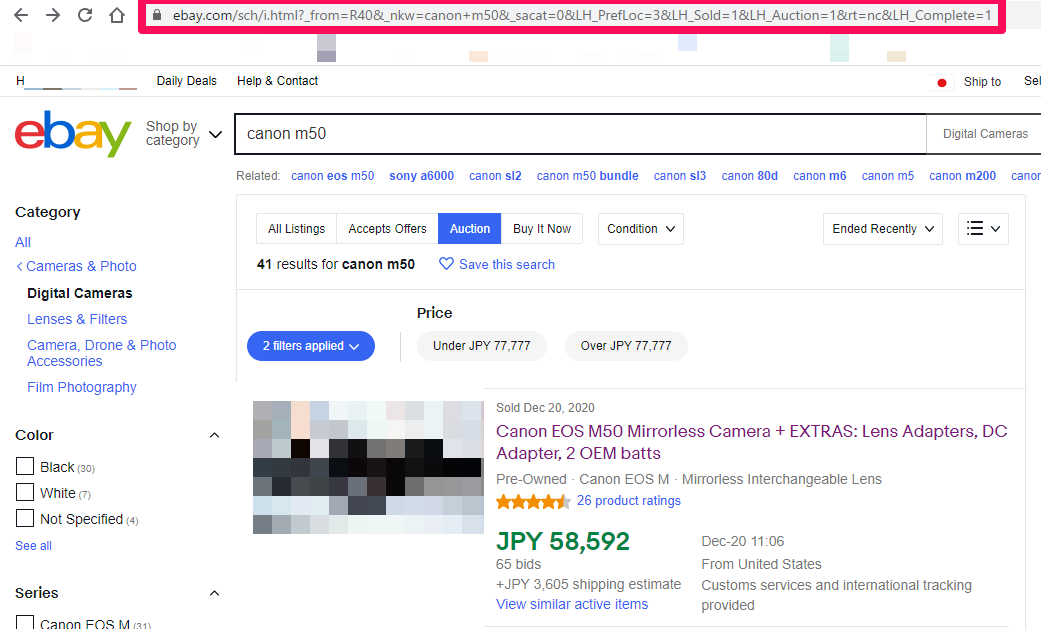
これらの全てにチェックを入れると、「US(アメリカ)」内で「入札が完了(終了)した商品」と「Sold Items(売れた商品)」のみが検索結果ページが表示されます。表示されたページ内に価格が表示されています。これで価格調査が行えます。
なお、この時にWebブラウザ上のアドレスバーで表示されているURLが大切になってきますので、URLを保存しておきます。
■PythonでeBayにおいて販売されている商品の価格を取得する
保存後、Pythonを使用し、eBayにおいて販売されている商品の価格を取得するスクリプトを書いていきます。
■コード
import requests
from bs4 import BeautifulSoup
import pandas as pd
url ='検索結果ページのURL'
#WEBページの解析
def get_data(url):
r = requests.get(url) #URLのデータを取得
soup = BeautifulSoup(r.text, 'html.parser') #要素を抽出
return soup
#解析後特定の情報を抜き出しリスト化する
def parse(soup):
productslist = [] #空のリストを用意する
results = soup.find_all('div',{'class': 's-item__info clearfix'}) #URL内の個別商品の情報を抽出
for item in results: #個別商品の情報からさらに情報を抽出
product = {
'タイトル': item.find('h3',{'class': 's-item__title'}).text, #findでタイトル部分を抽出
'販売価格':float(item.find('span',{'class':'s-item__price'}).text.replace('JPY','').replace(',','').strip()), #findで価格を抽出し、floatで浮動小数点数に変換
'販売日':item.find('span',{'class': 's-item__title--tagblock__COMPLETED'}).find('span',{'class':'POSITIVE'}).text, #findで販売日を抽出
'入札数':item.find('span',{'class':'s-item__bids'}).text, #findで入札数を抽出
'リンクURL':item.find('a',{'class':'s-item__link'})['href'], #findでリンクを抽出
}
productslist.append(product) #空のリストに個別商品の情報を追加する
return productslist
#CSVファイルに書き込み
def output(productslist):
productsdf = pd.DataFrame(productslist) #DataFrameの作成
productsdf.to_csv('output.csv', index=False) #DataFrameをCSVファイルに書き込み
print('CSVファイルへの保存が完了しました')
return
soup = get_data(url)
productslist = parse(soup)
output(productslist)requestsモジュール、bs4(BeautifulSoup4)モジュール、Pandasモジュールを呼び出して、requests.get()で検索結果ページの情報を取得します。取得した情報をBeautifulSoup(r.text, ‘html.parser’)で解析を行います。
解析後、解析したものの中から、「soup.find_all(‘div’,{‘class’: ‘s-item__info clearfix’})」で、個別商品の情報を抽出します。
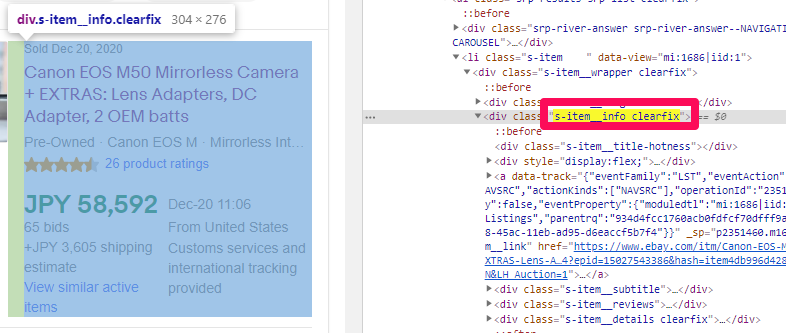
GoogleChromeのデベロッパーツールで確認すると「<div class=”s-item__info clearfix”></div>」の部分が、個別商品の情報のブロック要素だということが確認できます。
個別商品の情報を抽出した後は、さらにブロック要素を抽出していき商品のタイトル、販売価格、販売日、入札数などを抽出していきます。
細かく抽出した情報を空のリストに追加します。
追加後、Pandasモジュールを使い、DataFrameの作成し、細かく抽出した情報を作成したDataFrameの中に格納します。格納後、to_csv()で今回はCSVファイルへ書き込みを行い、保存します。
■実行
今回書いたスクリプトを「ebay_Item.py」という名前で保存し、コマンドプロンプトから実行してみます。
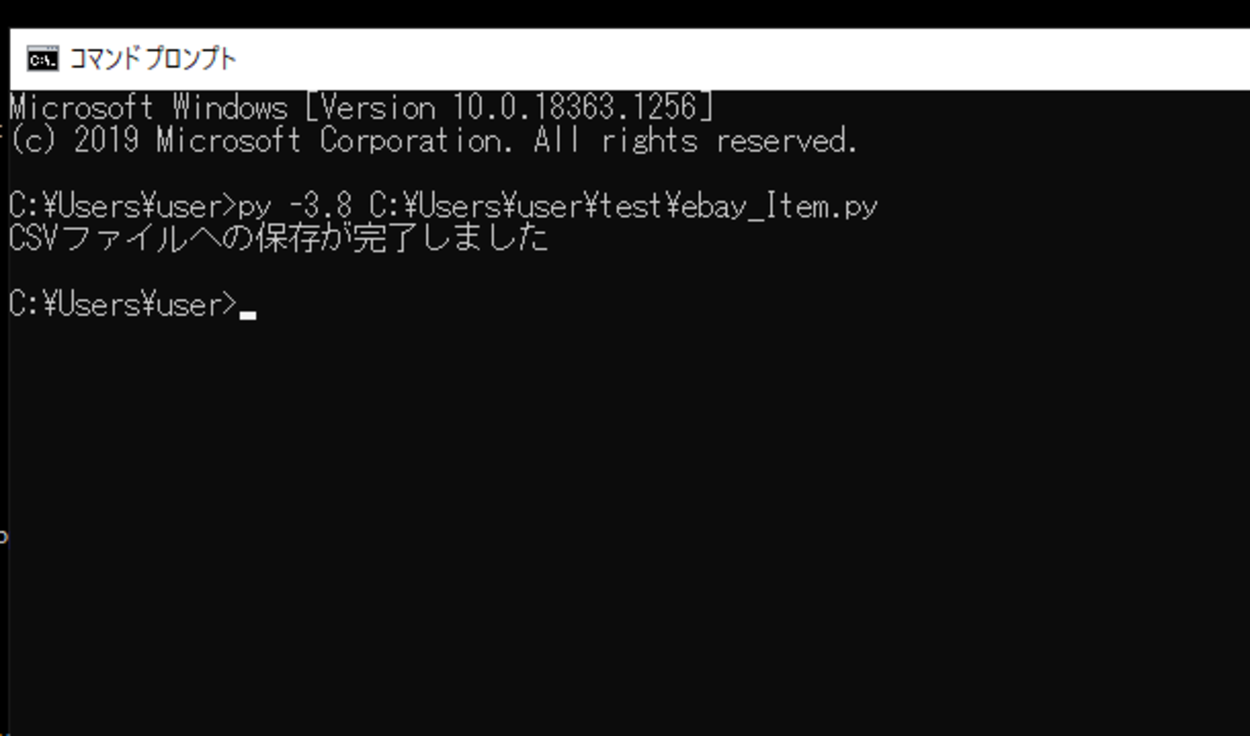
実行してみると、print関数で「CSVファイルへの保存が完了しました」と出力されます。
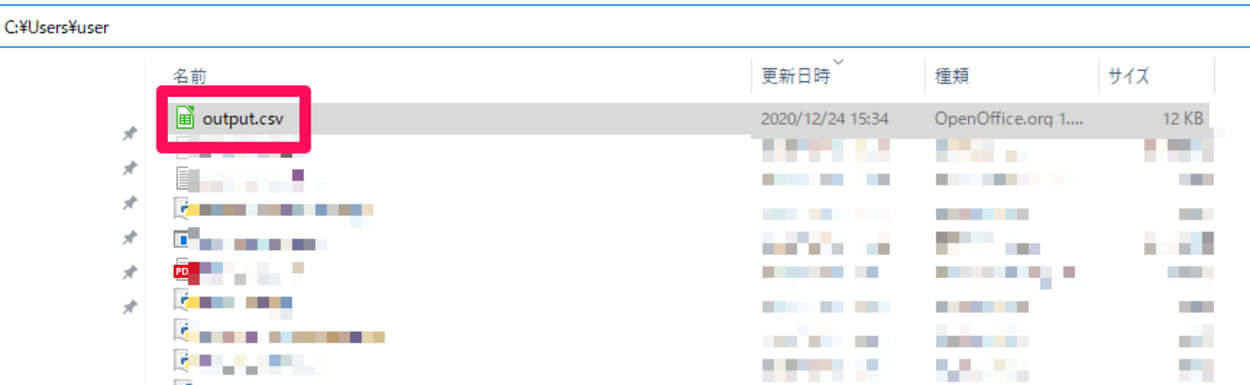
出力された後に、Pythonのカレントディレクトリ(作業ディレクトリ)を確認すると、CSVファイルが保存されていることが確認できました。
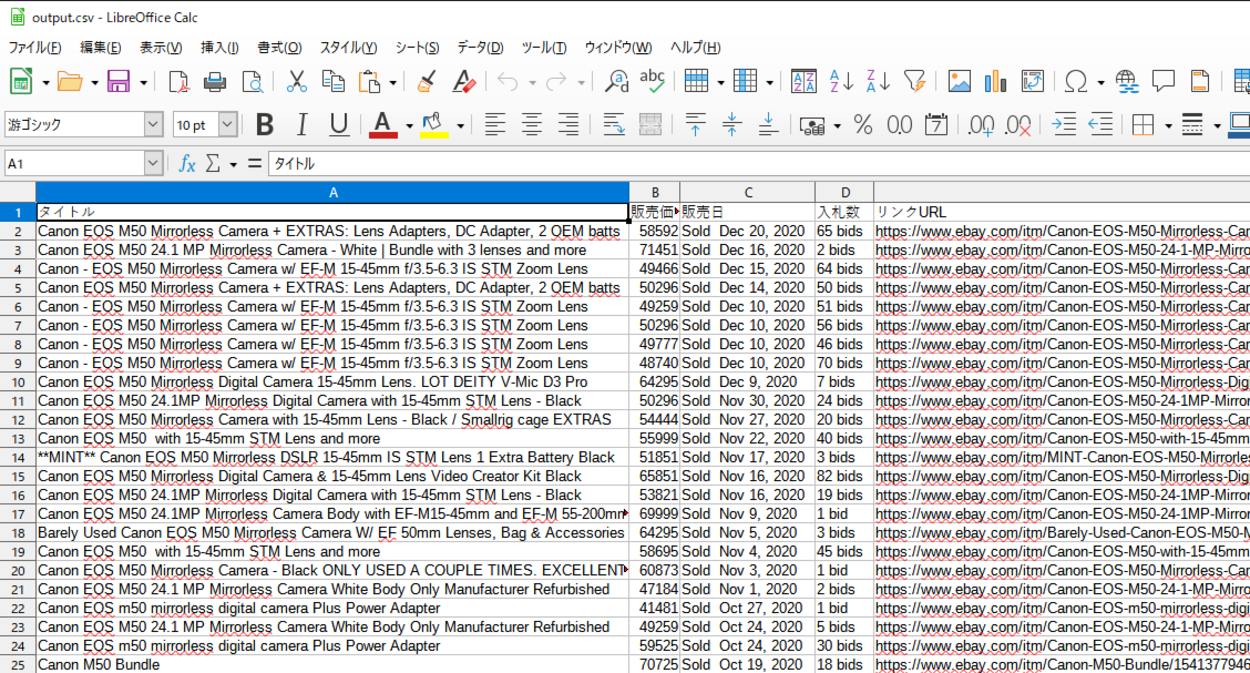
確認後、CSVファイルの中身を開いてみると、商品タイトルや価格などが抽出されてファイルに書き込みされていることが確認できました。

コメント