
Python初心者がpandasを使いCSVファイル読み込みや追加などをやってみます。(Windows10上)
■参考したページ
URL:https://myafu-python.com/pandas/
■Python
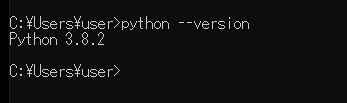
今回のPythonのバージョンは、「3.8.2」を使用しています。
■pandasとは何か。
pandasとはPythonのライブラリである。データを読み取り、追加、修正、削除などの処理ができる。このような処理が効率的に行えるので、データ分析(データサイエンス)や機械学習向き。
■pandasをインストール(インポート)してみる。
Windows10上からコマンドプロンプトが起動する。
pip install pandas
上記のコマンドコマンドを入力します。

入力後、インストールが開始され、インストールが完了する。
WARNING: The script f2py.exe is installed in ‘C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\Scripts’ which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use –no-warn-script-location.
上記のWARNINGが表示されたが、こちらのページを参考(https://teratail.com/questions/210778)にすると、とりあえずプログラムを実行できるようなので、先にすすめる。
■CSVファイルをテストで読み込んでみる
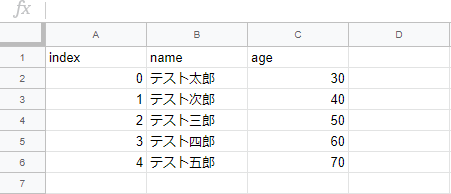
Googleスプレッドシートで上記のような表を作成し、「test.csv」というCSVファイルで保存します。このファイルをpandasを使って読み込みます。
■コード
import pandas as pd
data = pd.read_csv("test.csv",index_col = 0)
print(data)「import … as …」で、pandasを「pd」という別名に設定し、pdでtest.csvをread(読み取る)してみます。このコードを、「pandas-test.py」というファイルで保存。test.csvは、カレントディレクトリに置きます。
■実行
コマンドプロンプトからプログラムを実行してみます。
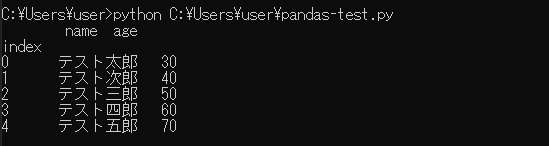
実行すると上記のように、test.csvの中身を読み込むことができました。
■読み込んだCSVファイルのデータに列を追加する
test.csvの中身を読み込むことができましたので、次は読み込んだCSVファイルのデータに”列”を追加してみます。
■コード
import pandas as pd
data = pd.read_csv("test.csv",index_col = 0)
list = [165, 166, 167, 170, 175]
series = pd.Series(list)
data["height"] = series.values
print(data)今回はtest.csvに、SeriesというDataFrameの構成要素となっているものを使い、構成要素の1つである値(values)にはdata「height(身長)」を設定、追加する。、構成要素の1つである値(values)、「height(身長)」には、listが存在し、それぞれの身長がデータとして記入されている。(参考:https://note.nkmk.me/python-pandas-dataframe-values-columns-index/、https://ai-inter1.com/python-series/)
このコードを、「pandas-test.py」というファイルで保存。test.csvは、カレントディレクトリに置いておきます。
■実行
コマンドプロンプトからプログラムを実行してみます。
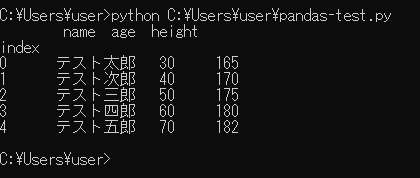
実行してみると、「height(身長)」の列が追加され、それぞれの身長が追加されています。
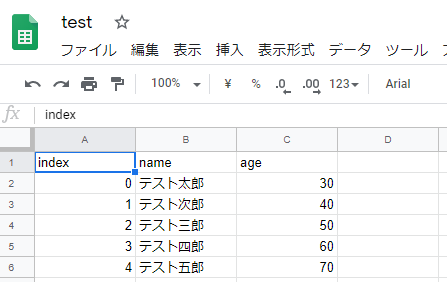
追加されましたが、Googleスプレッドシートで、test.csvの中身を確認してみましたが、「height(身長)」の列が追加されていません。
■「height(身長)」の列を追加した状態で、新しいCSVファイルを出力する
「height(身長)」の列を追加した状態で、CSVファイルを出力してみます。
■コード
import pandas as pd
data = pd.read_csv("test.csv",index_col = 0)
list = [165, 170, 175, 180, 182]
series = pd.Series(list)
data["height"] = series.values
data.to_csv("output.csv")
print('CSVファイルが出力されました。')CSVファイルで出力したいので「to_csv」と記述し、「output.csv」というファイルで出力してみます。最後に「CSVファイルが出力されました。」という文章を表示させてみることにしました。
このコードを、「pandas-test.py」というファイルで保存。test.csvは、カレントディレクトリに置いておきます。
なお、CSVファイルで出力したいので、「to_csv」と記述していますが、「to_excel」と記述するとExcelファイルの出力も可能です。
■実行
コマンドプロンプトからプログラムを実行してみます。

実行してみると、プログラムを実行され「CSVファイルが出力されました。」と表示されました。
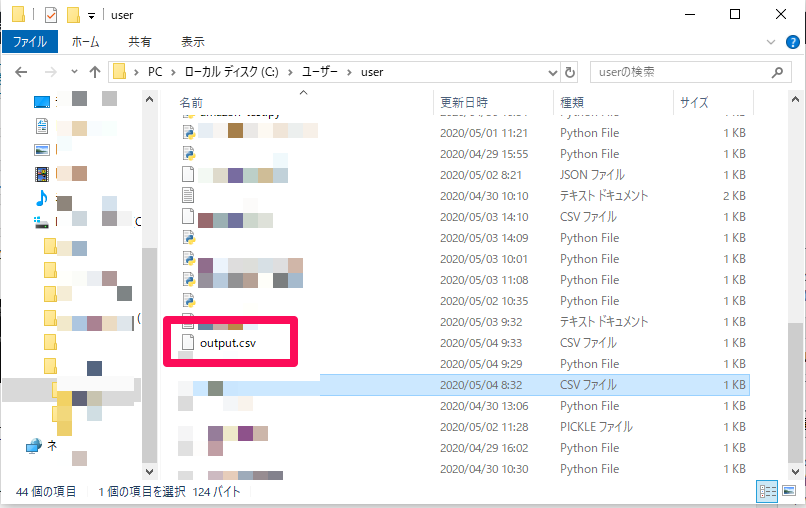
カレントディレクトリを確認してみると、output.csvが出力されていました。
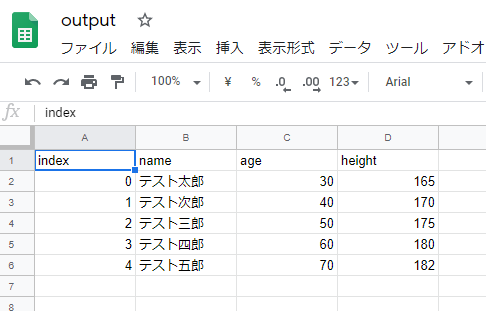
出力されたoutput.csvをGoogleスプレッドシートで確認してみると、「height(身長)」の列を追加した状態で出力されていることが確認できました。
■読み込んだ既存のCSVファイルに新しいデータを追加する(書き込み)
今回、読み込んだCSVファイル(test.csv)に「height(身長)」の列を追加、書き込みすることはできるのかやってみました。
■コード
import pandas as pd
data = pd.read_csv("test.csv",index_col = 0)
list = [165, 170, 175, 180, 182]
series = pd.Series(list)
data["height"] = series.values
data.to_csv("test.csv")
print('CSVファイルが出力されました。')「output.csv」という記述のところを、既存ファイルである「test.csv」に変更して、「pandas-test.py」のファイルを保存。
■実行
プログラムを実行してみる。
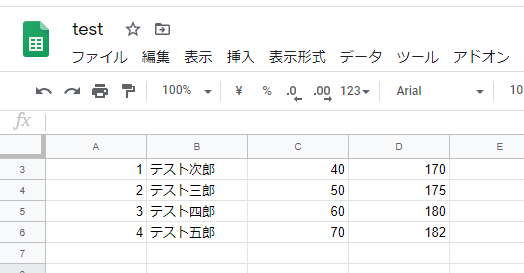
実行し、Googleスプレッドシートで確認してみると、既存ファイルである「test.csv」に、「height(身長)」の列を追加、書き込みすることができました。

コメント