
PythonでHTTPXを使用し、Webページ(テキストを含む)を取得してみます。
なお、今回はHTTPクライアントライブラリ「HTTPX」を使用しますので、事前にインストールしておく必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■HTTPXを使用しWebページ(テキストを含む)を取得する
では、HTTPXを使用しWebページ(テキストを含む)を取得するスクリプトを書いていきます。
■コード
import httpx
r = httpx.get('https://www.yahoo.co.jp/')
print(r.status_code)
print("\n")
print(r.headers)
print("\n")
print(r.text)インポートで、HTTPXモジュールを呼び出します。呼び出した後に、rという変数を作成し、その中でhttpx.get()を使用します。括弧内には取得したWebページのURLを指定します。今回はYahoo!JapanのURLを指定しています。指定後、格納。
格納後、print関数でWebページから取得した情報を出力します。今回はstatus_code(ステータスコード)と、headers(ヘッダー)と、text(テキスト)の情報を出力してみます。
■実行
このスクリプトを「get_url_http.py」という名前で保存し、コマンドプロンプトから実行してみます。
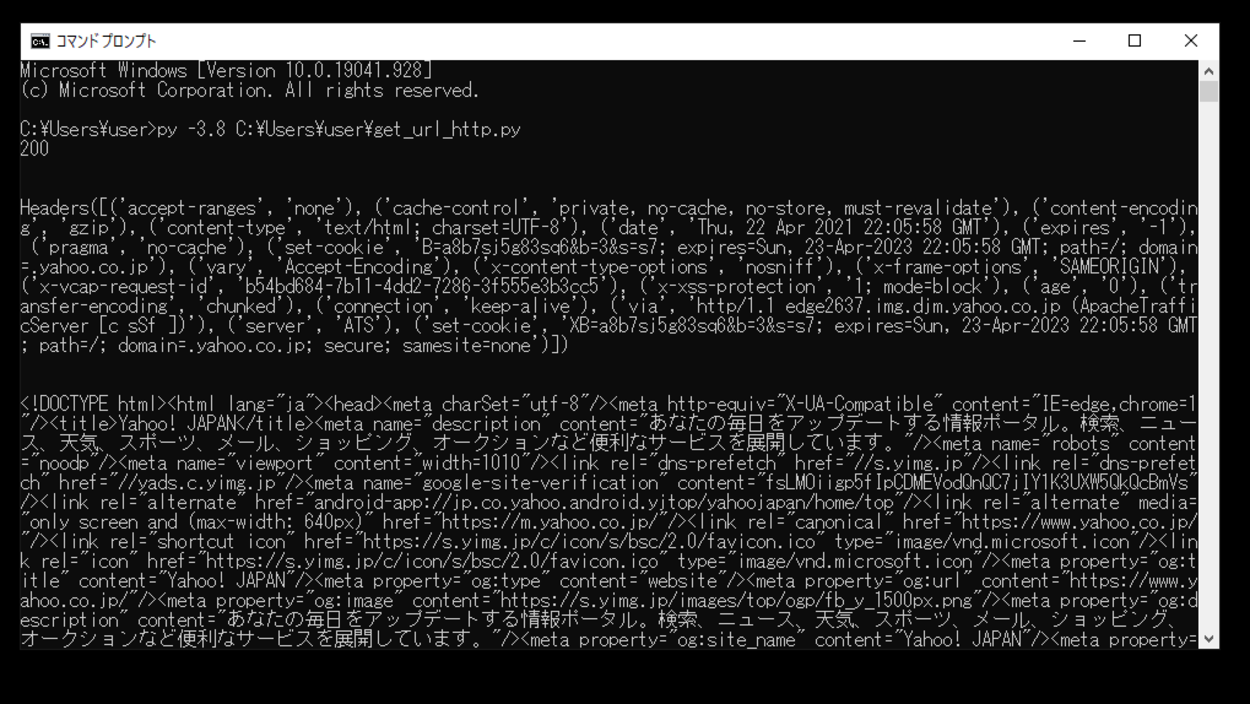
実行してみると、まずステータスコードが「200」と出力されHTTPリクエストが成功となったことが確認されました。次に今回指定したURLのヘッダーの情報とテキストの情報が取得され出力されたことを確認できました。

コメント