
PythonでCerberusを用いてデータの検証を行ってみます。
今回はCerberusを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■Cerberusを用いてデータの検証を行う
では、早速Cerberusを用いてデータの検証を行うスクリプトを書いていきます。
■コード
from cerberus import Validator
schema = {'name': {'type':'string'}}
v =Validator(schema)
document = {'name':'tanaka testtaou'}
print(v.validate(document))「from import」でcerberusモジュールのValidatorを呼び出します。呼び出した後にschemaという変数を定義し、その中に検証するための形式を格納します。これで検証スキーマが定義されました。今回の検証スキーマとしては、辞書内の「name」の「type」が「string(文字列)」であるというものです。
その後、vという変数を定義し、その中でValidator()を用います。括弧内には引数,パラメータとして、schema変数を渡します。これでValidatorクラスのインスタンスを作成し、検証スキーマを渡しました。
Validatorクラスのインスタンスを作成後、documentという変数を定義し、その中で辞書を作成し格納します。これは検証スキーマを用いて検証を行うために用意する辞書です。
最後に、vに対して、validate()を用います。括弧内には引数,パラメータとして、document変数を渡します。これで検証スキーマに対して辞書を検証し、検証の結果が返されます。返された結果をprint()で出力させます。
■実行・検証
このスクリプトを「Cerb_test.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
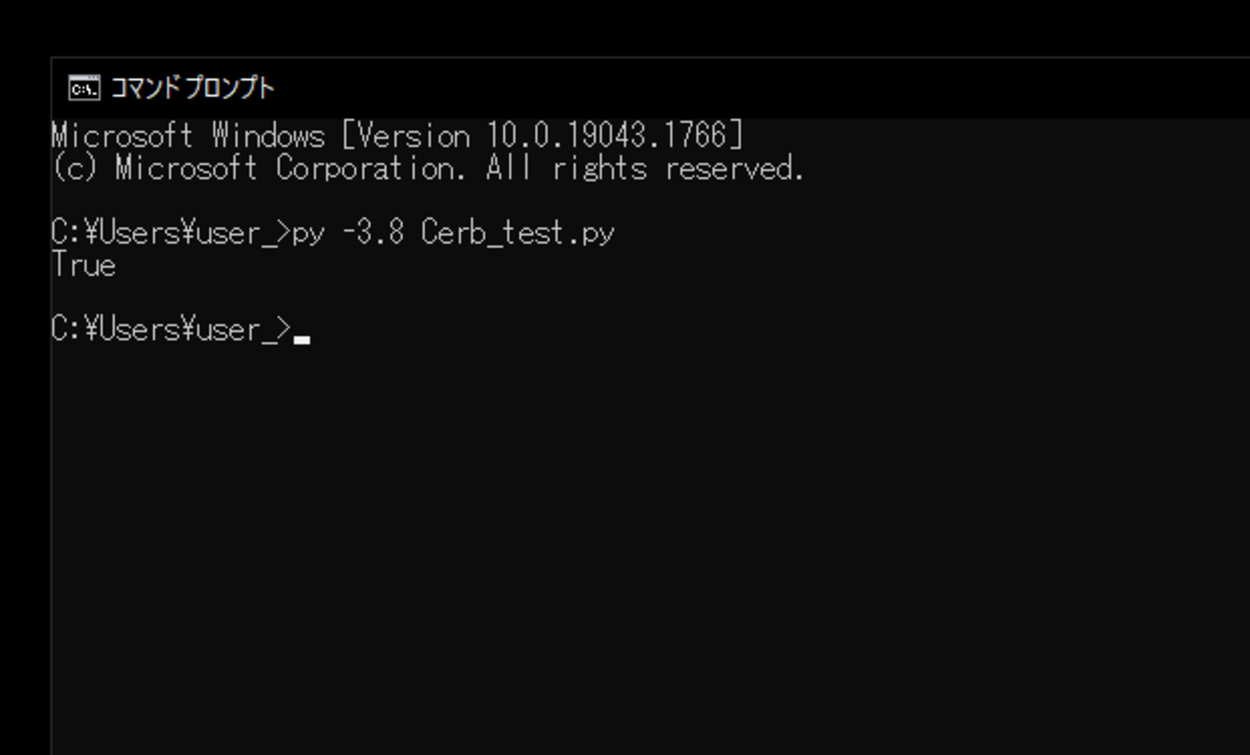
実行してみると、今回の検証スキーマに対して指定した辞書の検証が行われ「True(真)」と出力されました。これは辞書内の「name」の「type」が「string(文字列)」であることを意味しています。

コメント