
Pythonでautoscraperを用いて自動的なウェブスクレイピングを行ってみます。
今回、autoscraperを用います。このライブラリ・モジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■autoscraperを用いて自動的なウェブスクレイピングをする
では、早速autoscraperを用いて自動的なウェブスクレイピングをするスクリプトを書いていきます。
■コード
from autoscraper import AutoScraper url = 'https://www.yahoo.co.jp/' wanted_list = ["スノーボード"] scraper = AutoScraper() result = scraper.build(url,wanted_list) print(result)
「from import」でautoscraperを呼び出します。その後、urlという変数を定義し、その中にスクレイピングを行うWebサイトのURLを格納します。
格納後、wanted_listという変数を定義し、Webサイト内のキーワードを格納します。その後、scraperという変数を定義し、その中でAutoScraper()を用います。
変数を定義した後に、さらにresultという変数を定義し、その中でscraperに対してbuild()を用います。括弧内には、引数,パラメータとして、urlとwanted_listを渡します。これでscraperが構築され、Webスクレイピングを開始し、結果をresult変数に格納します。
最後に、result変数の情報をprint()を用いて出力します。
■実行・検証
このスクリプトを「py_scraping.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。

実行してみると、scraperは構築されているはずですが、Webスクレイピングはされず、result変数内は何も出力されませんでした。出力後、原因を調べてみました。そもそもautoscraperは日本語対応しているのかですが、中国語には対応(https://gist.github.com/alirezamika/72083221891eecd991bbc0a2a2467673)しており、またすべての文字列はUnicodeであるため、言語固有の問題は発生しないはずというautoscraperの開発者のGithub上での投稿を発見しました。
では、なぜスクレイピングできないのか。Github上(https://gist.github.com/alirezamika/72083221891eecd991bbc0a2a2467673)に投稿されていたコードを参考して、再度スクリプトを書いてみます。
■コード
import requests
from autoscraper import AutoScraper
url = 'https://news.yahoo.co.jp/'
res = requests.get(url)
res.encoding = 'utf-8'
html = res.text
wanted_dict = {'web_name':['ワクチン'], 'url':['https://news.yahoo.co.jp/']}
scraper = AutoScraper()
result = scraper.build(url, html=html, wanted_dict=wanted_dict)
result = scraper.get_result_similar(url, html=html, group_by_alias=True)
print(result)■実行・検証
「py_scraping.py」を変更し、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
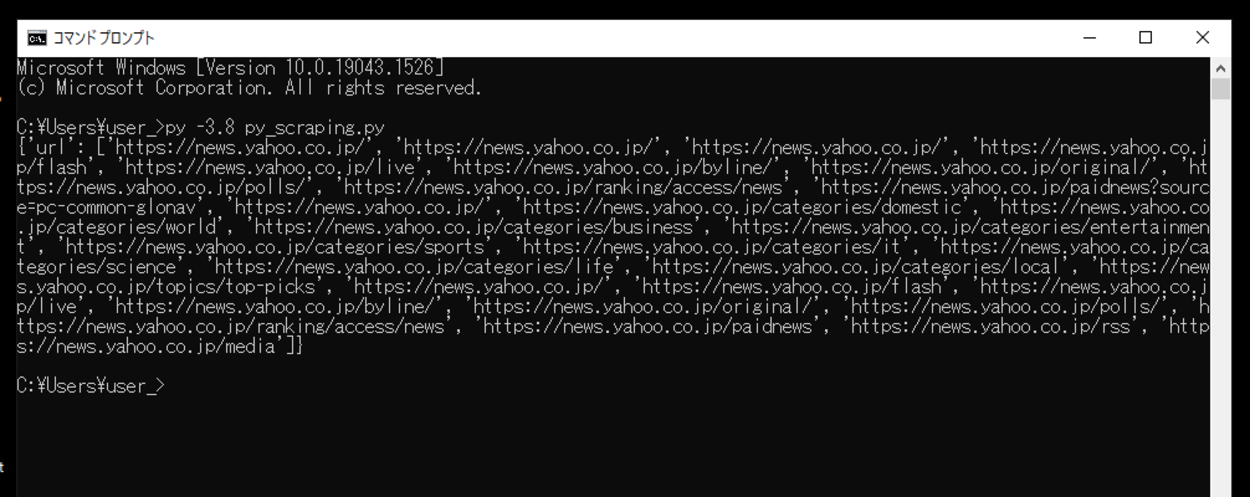
実行してみると、Webスクレイピングは行われたようですが、指定したキーワードである「ワクチン」を含むページを取得していない。この原因を調べてみましたが、不明。
最後にGithub上(https://gist.github.com/alirezamika/72083221891eecd991bbc0a2a2467673)に投稿されている方で、「空のリストを取得」したことを投稿している方がちらほらいましたので、根本的に問題が解決されていないように感じました。なので、今回の実験はこれで一旦終了とします。また今度スクレイピングを試みます。

コメント