
前回、Pythonでautoscraperを用いて自動的なウェブスクレイピングを行うという記事を公開しましたが、スクリプトを書いて実行してみると「空のリストが取得」され、ウェブスクレイピングが開始できませんでした。
開始できませんでしたが、スクリプトのコード内には、Yahoo!Japanを指定し、このWebサイトをスクレイピングするように指定していたので、Webサイトを変更し、”アマゾン: Amazon”をウェブスクレイピングしてみることにしました。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■autoscraperを用いてAmazonをウェブスクレイピングする
では、早速Pythonでautoscraperを用いてAmazonをウェブスクレイピングするスクリプトを書いていきます。
■コード
from autoscraper import AutoScraper url = 'https://www.amazon.co.jp/s?k=%E3%83%99%E3%83%BC%E3%83%88%E3%83%99%E3%83%B3' wanted_list = ["ベートーベン"] scraper = AutoScraper() result = scraper.build(url, wanted_list) print(result)
今回はurl変数を定義し、その中にAmazon検索で「ベートベン」と検索した結果のページを格納します。
格納後、wanted_listを定義し、その中に検索結果ページから「ベートベン」というキーワードを取得するために、キーワードを格納。
その後、scraperを構築し、Webスクレイピングを開始。開始後、結果をresult変数に格納。格納した結果をprint()で出力してみます。
■実行・検証
このスクリプトを「scraper_test.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
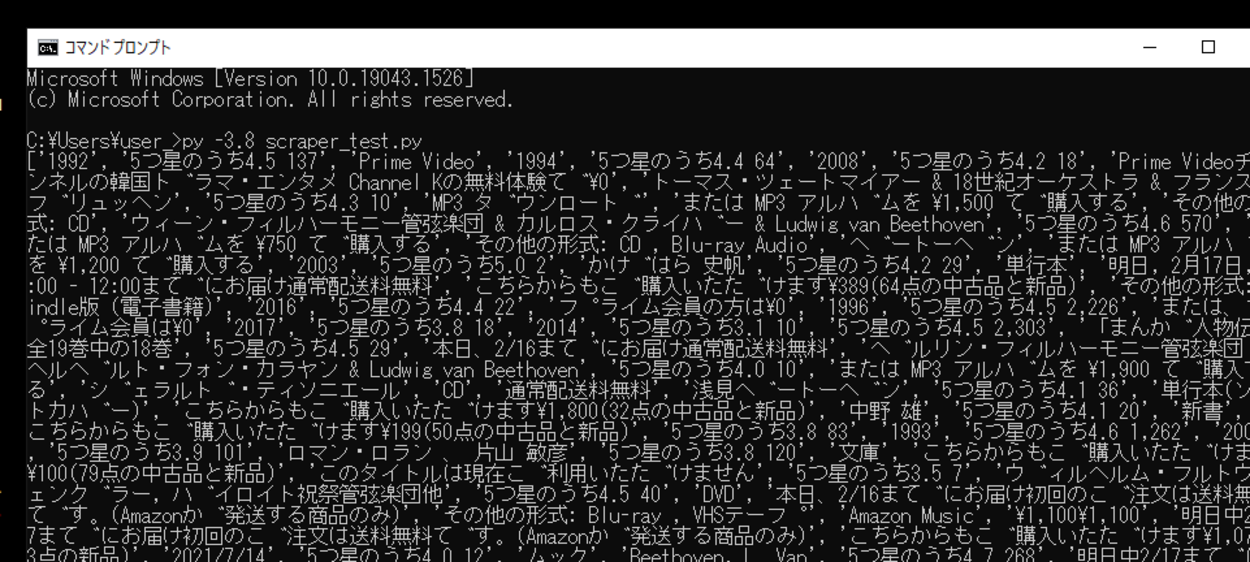
実行してみると、今回指定したキーワードでAmazonの検索結果ページをスクレイピングすることができました。できましたが、今回指定したキーワードは「ベートベン」で、このキーワードを違う日本語のキーワードに変更し、再度スクレイピングしてみると、「空のリストが取得」されるケースが発生することを確認しました。どうやら、うまく日本語の取得できていないような感じがしました。

コメント