
requests-htmlを使用しPythonでアマゾン(Amazon)の商品詳細ページ(価格・タイトル)から自動で情報を抽出してみます。
なお、requests-htmlモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■requests-htmlを使用しアマゾン(Amazon)の商品詳細ページから情報を抽出する
では、早速requests-htmlを使用しアマゾン(Amazon)の商品詳細ページから情報を抽出するスクリプトを書いていきます。
■コード
from requests_html import HTMLSession
#Amazonの商品詳細ページ
urls = ['https://www.amazon.co.jp/******/dp/B07N*****/ref=sr_1_15***qid=1***&sr=***',
'https://www.amazon.co.jp/gp/slredirect/picassoRedirect.html/ref=***,
'https://www.amazon.co.jp/%****/dp/B08****/ref=****&keywords=**']
#GETリクエストを作成しXPathで特定要素の抽出
def getPrice(url):
s = HTMLSession()
r = s.get(url)
r.html.render(timeout=20)
product = {
'タイトル': r.html.xpath('//*[@id="productTitle"]', first=True).text,#XPathを使って要素の抽出
'価格': r.html.xpath('//*[@id="priceblock_ourprice"]', first=True).text#XPathを使って要素の抽出
}
print(product)
return product
tvprices = [] #空のリストを作成
#for文によるループ処理(繰り返し処理)で各商品詳細ページの情報を抽出
for url in urls:
tvprices.append(getPrice(url))#空のリストに関数の戻り値を追加
#リストを出力
print(len(tvprices))requests_htmlモジュールのHTMLSessionを呼び出して、urlsにAmazon(アマゾン)の商品詳細ページのURLを格納します。
格納後、関数を定義し、GETリクエストを作成しXPathで特定要素の抽出します。
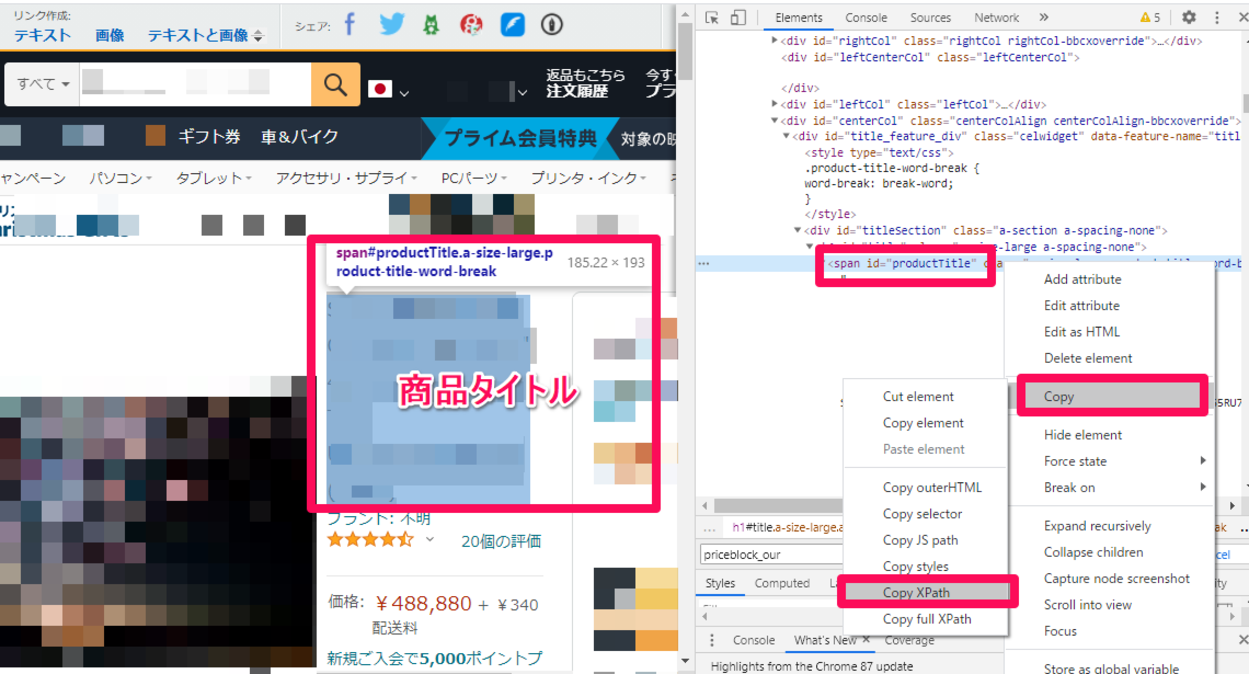
XPathで特定要素の抽出する場合は、GoogleChromeのデベロッパーツールを表示させます。表示させた後に、デベロッパーツール上で特定要素の部分で、右クリックをするとプルダウンメニューが表示され「Copy」がありますので、こちらをクリックし、さらに「Copy XPath」をクリックすると、特定要素がコピーされますので、あとはコードエディターに貼り付けるだけです。(画像は、商品タイトルを抽出するために、「<span id=”productTitle”></span>」の部分をコピーしています。)
なお、商品詳細ページによっては、「<span id=””></span>」のidが変更されている場合があります。変更せずにスクリプトを実行すると「AttributeError: ‘NoneType’ object has no attribute ‘text’」や「ConnectionResetError: [WinError 10054] 既存の接続はリモート ホストに強制的に切断されました。」といったエラーが発生します。
■実行
今回のスクリプトを「amazon_urls.py」という名前で保存し、コマンドプロンプトから実行してみます。
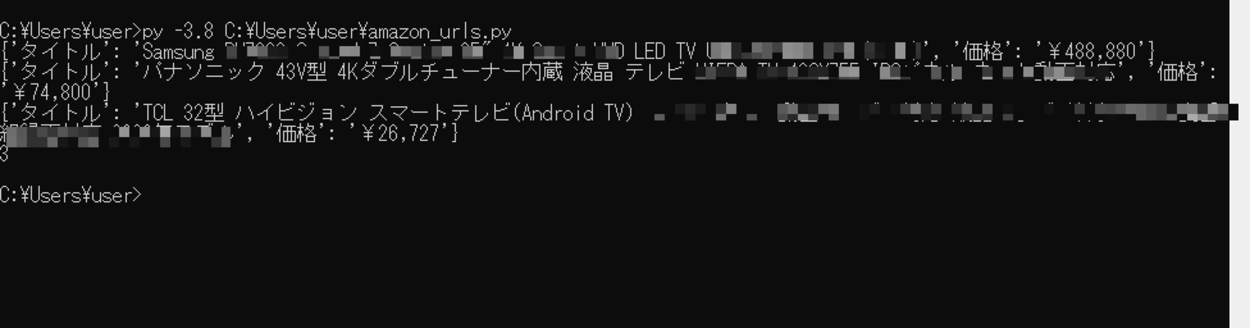
実行してみると、指定したアマゾン(Amazon)の商品詳細ページから自動で情報を抽出し、出力できることを確認できました。

コメント