
Pythonでweasyprintを用いてHTMLをPDFに変換してみます。
今回は、weasyprintを用います。このライブラリは、Pythonの標準ライブラリ・モジュールではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■weasyprintを用いてHTMLをPDFに変換する
では、早速、weasyprintを用いてHTMLをPDFに変換するスクリプトを書いていきます。
■コード
from weasyprint import HTML
HTML('https://laboratory.kazuuu.net/').write_pdf('test_p.pdf')「from import」でweasyprintのHTMLを呼び出します。その後、HTML()を用います。括弧内には引数,パラメータとしてHTMLを渡します。今回は当サイトのURLを指定します。次に”.”(ドッド)を用いてwrite_pdf()を用います。括弧内には引数,パラメータとして変換されたPDFを保存する場所の指定と、pdfファイルの名前を渡します。今回は「test_p.pdf」というPDFファイルの名前を指定します。保存される場所は、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)になります。
■実行・検証
このスクリプトを「w_pdf.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
Traceback (most recent call last):
File "w_pdf.py", line 1, in
from weasyprint import HTML
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\weasyprint\__init__.py", line 325, in
from .css import preprocess_stylesheet # noqa isort:skip
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\weasyprint\css\__init__.py", line 27, in
from . import computed_values, counters, media_queries
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\weasyprint\css\computed_values.py", line 16, in
from ..text.ffi import ffi, pango, units_to_double
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\weasyprint\text\ffi.py", line 404, in
gobject = _dlopen(
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\weasyprint\text\ffi.py", line 391, in _dlopen
return ffi.dlopen(names[0]) # pragma: no cover
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\cffi\api.py", line 150, in dlopen
lib, function_cache = _make_ffi_library(self, name, flags)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\cffi\api.py", line 832, in _make_ffi_library
backendlib = _load_backend_lib(backend, libname, flags)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\cffi\api.py", line 827, in _load_backend_lib
raise OSError(msg)
OSError: cannot load library 'gobject-2.0-0': error 0x7e. Additionally, ctypes.util.find_library() did not manage to locate a library called 'gobject-2.0-0'実行してみると「OSError」というエラーが出力され実行することができませんでした。その後、エラー内容を確認し、調べてみると「gobject-2.0-0」というライブラリがloadできないことが原因だと判明しました。この原因を解決するために、weasyprint(https://doc.courtbouillon.org/weasyprint/stable/first_steps.html)のドキュメントにも書かれている、GTK(https://github.com/tschoonj/GTK-for-Windows-Runtime-Environment-Installer/releases)をWindows10にインストールすることにしました。
インストール後、再度スクリプトを実行してみます。
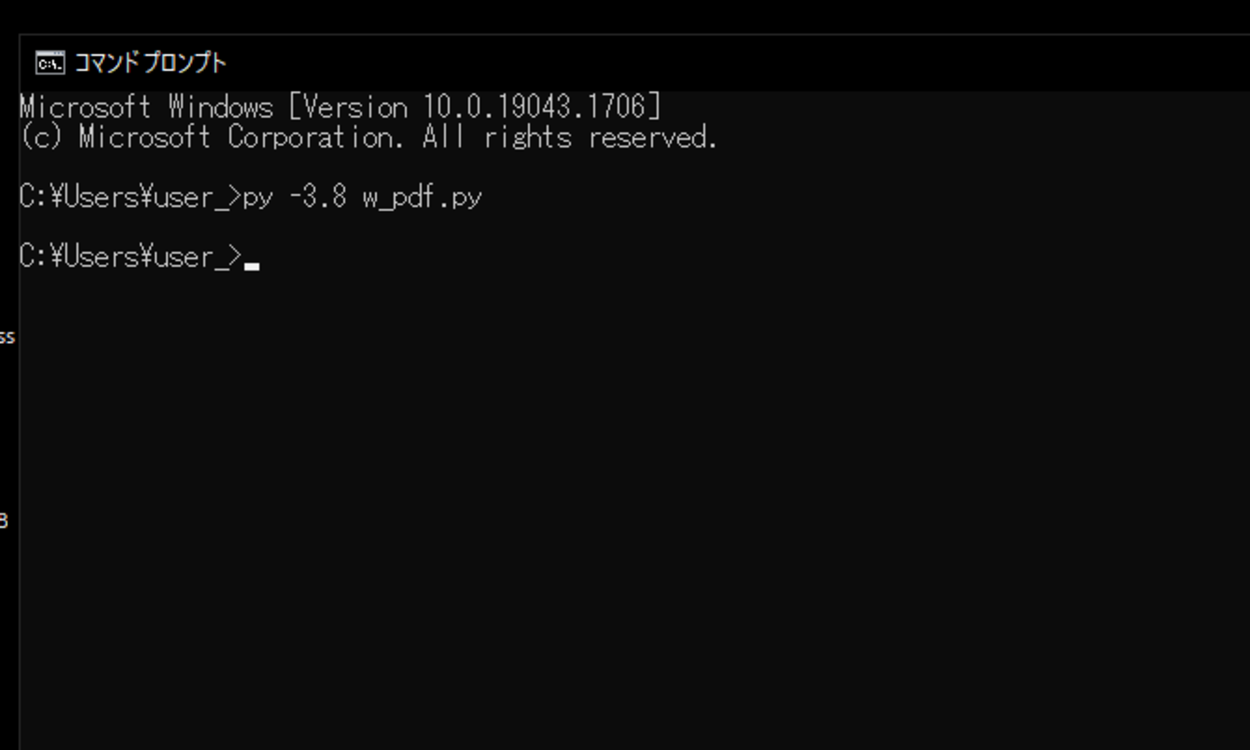
実行してみると、変換後に変換したことを完了という文字列を出力させる指示などはスクリプトに記述していないので、何も出力されません。

出力されませんが、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)を確認すると、「test_p.pdf」というPDFファイルが作成されていることが確認できました。
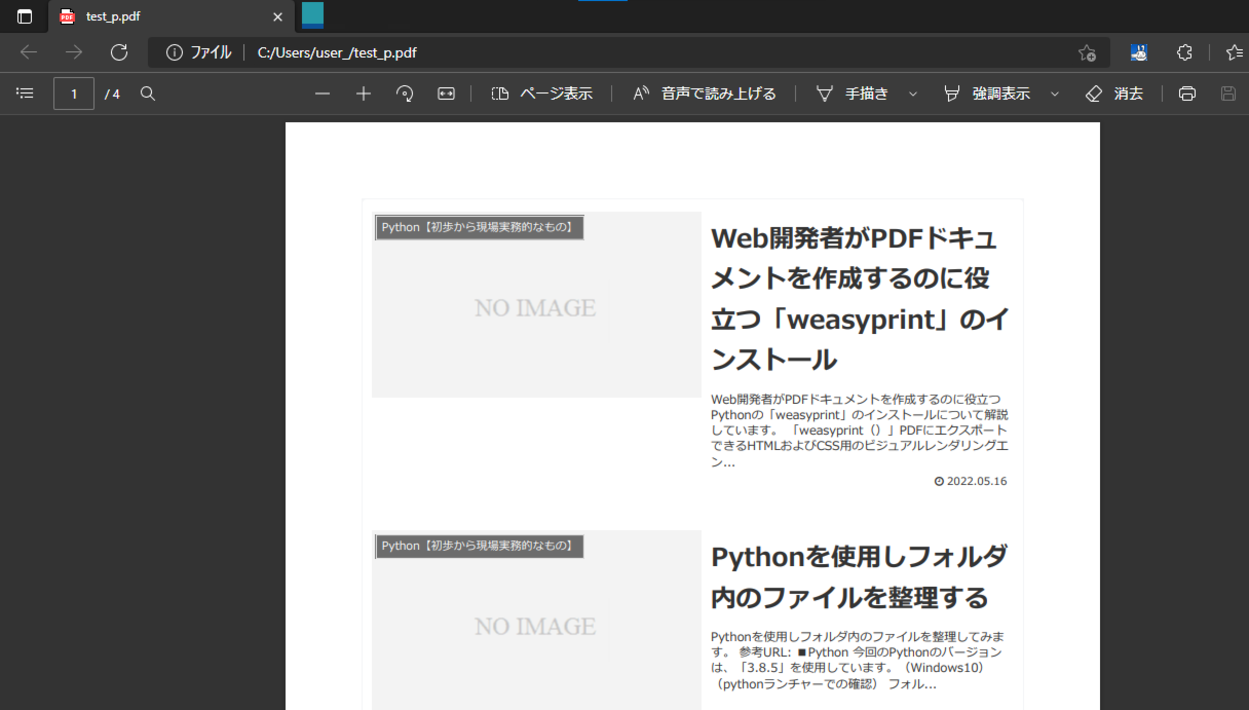
このPDFファイルを開いてみると、今回指定したHTML(Webサイト)がPDF形式に変換されていることが確認できました。

コメント