
Pythonを使用してPDFファイルからテキスト(文章)を抽出してみます。
PDFファイルからテキスト(文章)を抽出する場合は、PyPDF2モジュールを事前にインストールする必要があります。PyPDF2モジュールは、Pythonの標準ライブラリではありません。
■Python
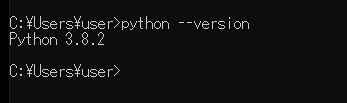
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■PDFファイルを用意する
Pythonを使用してPDFファイルからテキスト(文章)を抽出しますが、その前にテキスト(文章)を抽出するPDFを用意します。
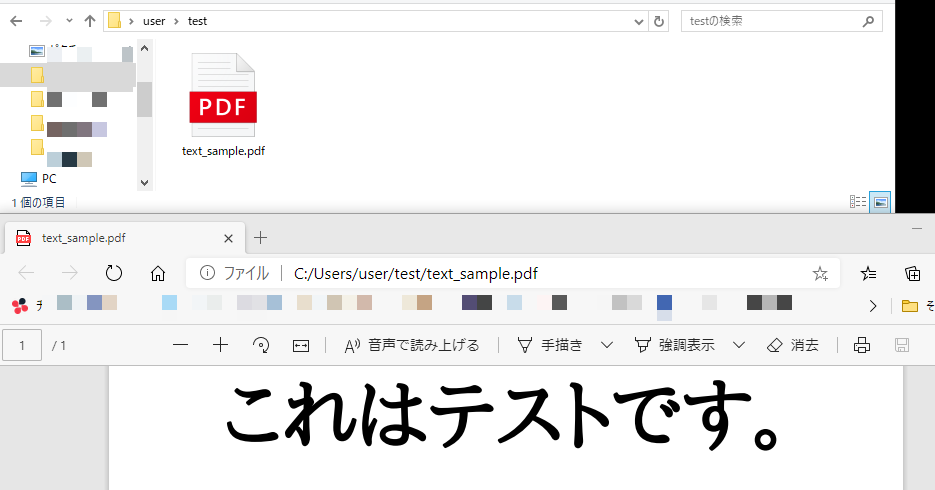
今回は上記のようなPDFファイルを用意しました。
保存されている場所は「C:\Users\user\test(フォルダパス)」です。
■PyPDF2モジュールを使用してPDFファイルからテキスト(文章)を抽出する
PDFファイルの用意ができましたので、PyPDF2モジュールを使用してPDFファイルからテキスト(文章)を抽出するスクリプトを書いていきます。
■コード
import PyPDF2 pdffile = open(r'C:\Users\user\test\text_sample.pdf','rb') pdfreader = PyPDF2.PdfFileReader(pdffile) print(pdfreader.numPages) g_page = pdfreader.getPage(0) print(g_page.extractText()) pdffile.close()
インポートでPyPDF2モジュールを呼び出して、pdffileという変数を作成し、open()で今回用意したPDFファイルを開きます。開いたファイルは、rbモードで読み込みます。
次にpdfreaderという変数を作成し、PyPDF2.PdfFileReader()で、読み込んだPDFファイルをPDFファイルとして読み込みます。
読み込んだ後に、print()関数で読み込んだPDFファイルのページ数を出力します。
出力後、g_pageという変数を作成し、読み込んだPDFファイルの最初のページを取得します。
取得した後に、extractText()で取得したページのテキスト(文章)を抽出します。
最後にclose()で読み込んだPDFファイルを閉じます。
■実行
今回書いたスクリプトを「extract_text_from_pdf.py」という名前で保存し、コマンドプロンプトから実行してみます。
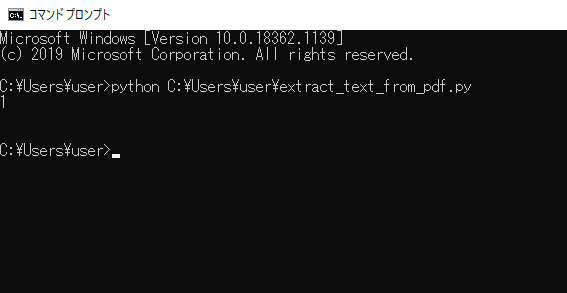
実行してみると、今回用意したPDFファイルのページ数のみが出力され、テキスト(文章)の抽出はできませんでした。日本語のテキスト(文章)の抽出は行なえません。英語のテキスト(文章)の抽出も行ってみましたが、抽出できない場合がありました。

コメント