
lxmlを使用しPythonでWebスクレイピングを実装してみます。
lxmlモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
なお、今回はrequestsモジュールも使用しますので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■lxmlを使用しPythonでWebスクレイピングを実装する
では、早速lxmlを使用しPythonでWebスクレイピングを実装するスクリプトを書いていきます。
■コード
import requests from lxml import html link = 'https://laboratory.kazuuu.net/docker-desktop-for-installing-windows-windows10/' path = '//*[@id="content"]/div' response = requests.get(link) byte_string = response.content source_code = html.fromstring(byte_string) tree = source_code.xpath(path) print(tree[0].text_content())
インポートでrequestsと、lxmlのhtmlを呼び出して、linkという変数を作成し、今回Webスクレイピングの対象となるWebサイト・ページを指定します。今回は当サイトのページ(https://laboratory.kazuuu.net/docker-desktop-for-installing-windows-windows10/)を指定しています。
次にpathという変数を作成し、対象となるWebサイト・ページ内でWebスクレイピングを行った場合に抽出する特定の要素を指定します。
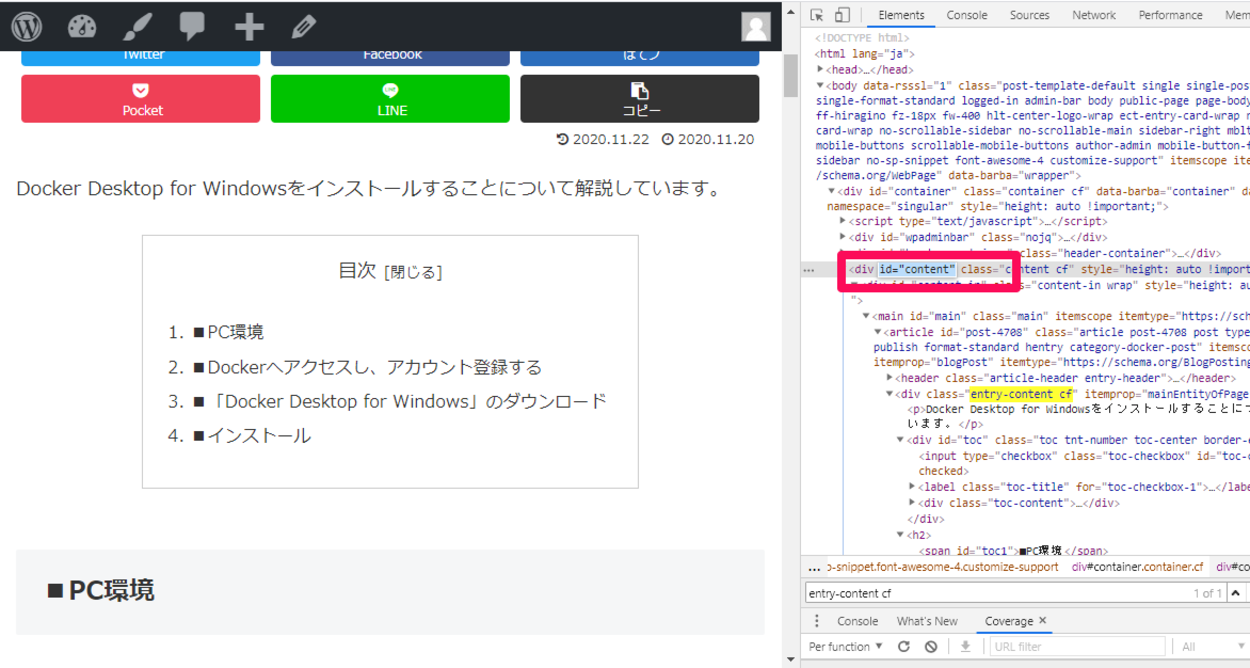
今回は、Google Chromeのデベロッパーツール(検証モード)を使用し、対象となるWebサイト・ページ内の「<div id=”content“></div>」の部分を抽出してみますので、「//*[@id=”content”]/div」と記述します。
記述後、responseという変数を作成し、requests.get()で対象となるWebサイト・ページにGET リクエストを行う。さらにbyte_stringという変数を作成し、response.contentでデコードされていないレスポンスのバイト列を取得します。
次にsource_codeという変数を作成し、取得したresponse.contentでデコードされていないレスポンスのバイト列をHtmlElementオブジェクトに変換します。
次にtreeという変数を作成し、デコードされていないレスポンスのバイト列をHtmlElementオブジェクトにしたものを、XPathで指定し特定の要素を取得します。
取得した後は、treeの1番目のテキストコンテンツをprintで出力します。
■実行
今回の書いたスクリプトを「web_scraping_test.py」という名前で保存、コマンドプロンプトから実行してみます。
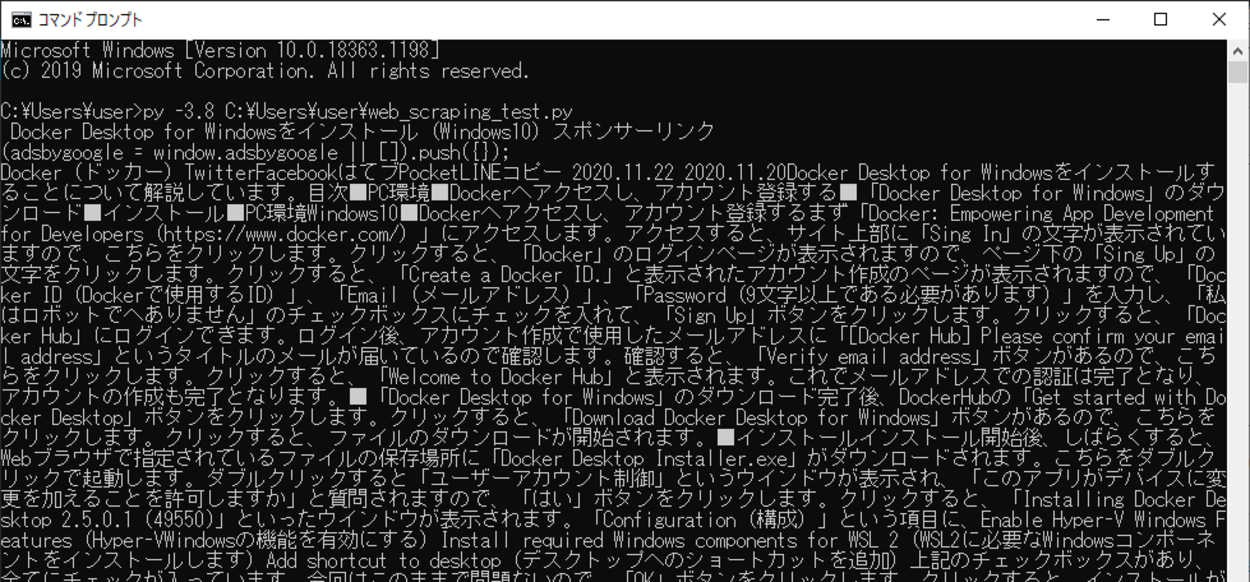
実行してみると、対象となるWebサイト・ページ内の特定の要素を抽出し、出力させることができました。

コメント