
Pythonでラベルエンコーディングを実行してみます。
scikit-learnモジュールのLabelEncoder(ラベルエンコーダー)を用いてラベル エンコーディングを使用することで、アルファベット順に基づいて、各カテゴリ値に整数値を割り当てることができます。
なお、今回はscikit-learnとpandasモジュールを用います。これらのライブラリ・モジュールはPythonの標準ライブラリではないので、事前にインストールする必要があります。
■Python
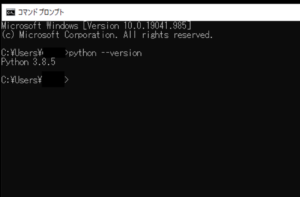
今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■仮想環境への切り替え
ラベルエンコーディングを実行する前に、今回は仮想環境を構築し、その中にscikit-learnモジュールをインストールしていますので、まずはWindows10のコマンドプロンプトを起動します。
C:\Users\user_>cd scikit_test
起動後、上記のコマンドを入力し、Enterキーを押します。「cd」コマンドで「scikit_test」ディレクトリ内に移動します。
C:\Users\user_\scikit_test>.venv\Scripts\activate.bat
移動後、上記のコマンドを入力し、Enterキーを押します。仮想環境のディレクトリ内に作成された activateスクリプトを実行し、仮想環境に入ります。
(.venv) C:\Users\user_\scikit_test>
Enterキーを押すと、「(.venv)」と表示されます。これで仮想環境に入ることができました。
■pandasのインストール
(.venv) C:\Users\user_\scikit_test> pip install pandas
仮想環境に入った後に、上記のコマンドを入力し、Enterキーを押します。今回はscikit-learnモジュールは事前にインストールしていますが、pandasのインストールは行っていないので、インストールします。
Collecting pandas Using cached pandas-1.4.3-cp38-cp38-win_amd64.whl (10.6 MB) Requirement already satisfied: numpy>=1.18.5; platform_machine != "aarch64" and platform_machine != "arm64" and python_version < "3.10" in c:\users\user_\scikit_test\.venv\lib\site-packages (from pandas) (1.23.1) Collecting pytz>=2020.1 Using cached pytz-2022.1-py2.py3-none-any.whl (503 kB) Collecting python-dateutil>=2.8.1 Using cached python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB) Collecting six>=1.5 Using cached six-1.16.0-py2.py3-none-any.whl (11 kB) Installing collected packages: pytz, six, python-dateutil, pandas Successfully installed pandas-1.4.3 python-dateutil-2.8.2 pytz-2022.1 six-1.16.0 WARNING: You are using pip version 20.1.1; however, version 22.2.2 is available. You should consider upgrading via the 'c:\users\user_\scikit_test\.venv\scripts\python.exe -m pip install --upgrade pip' command.
Enterキーを押すと、インストールが開始され、「Successfully installed(正常にインストールされました)」と出力されます。これが出力されればpandasのインストールは完了となります。今回は「WARNING(警告)」が出力されましたが、エラーではないので、一旦無視します。
■ラベルエンコーディングを実行する
インストール後、ラベルエンコーディングを実行するスクリプトを書いていきます。
■コード
import pandas as pd
from sklearn.preprocessing import LabelEncoder
lab = LabelEncoder()
df = pd.DataFrame({'組':['A','A','B','B','B','C'],
'名前':['田中','佐々木','松本','野村','小杉','村田'] })
df['組'] = lab.fit_transform(df['組'])
print(df)今回は「import」でpandasモジュールを呼び出し、asを用いてpdとします。さらに「from import」でsklearn.preprocessingのLabelEncoderを呼び出します。
その後、labという変数を定義し、その中でLabelEncoder()を用います。これでLabelEncoder(ラベルエンコーダー)のインスタンスが作成されました。
作成後、dfという変数を定義し、その中でpd.DataFrame()を用います。括弧内に引数,パラメータとして、辞書(dict型オブジェクト)を渡します。これで、二次元の表形式のデータ(DataFrameオブジェクト)が作成されます。
二次元の表形式のデータ(DataFrameオブジェクト)の作成後に、DataFrameオブジェクト内の「組」に対して、lab変数のfit_transform()を用います。これで二次元の表形式のデータ(DataFrameオブジェクト)内のデータ(アルファベット順のキー)に合わせて、整数値が割り当てられます。
最後にprint()を用いてdf変数内の情報を出力してみます。
このスクリプトを「scikit_test」ディレクトリ内に「label_test.py」という名前で保存します。
■実行・検証
保存後、コマンドプロンプト上で仮想環境に入った状態でスクリプトファイルを実行してみます。
(.venv) C:\Users\user_\scikit_test>python label_test.py
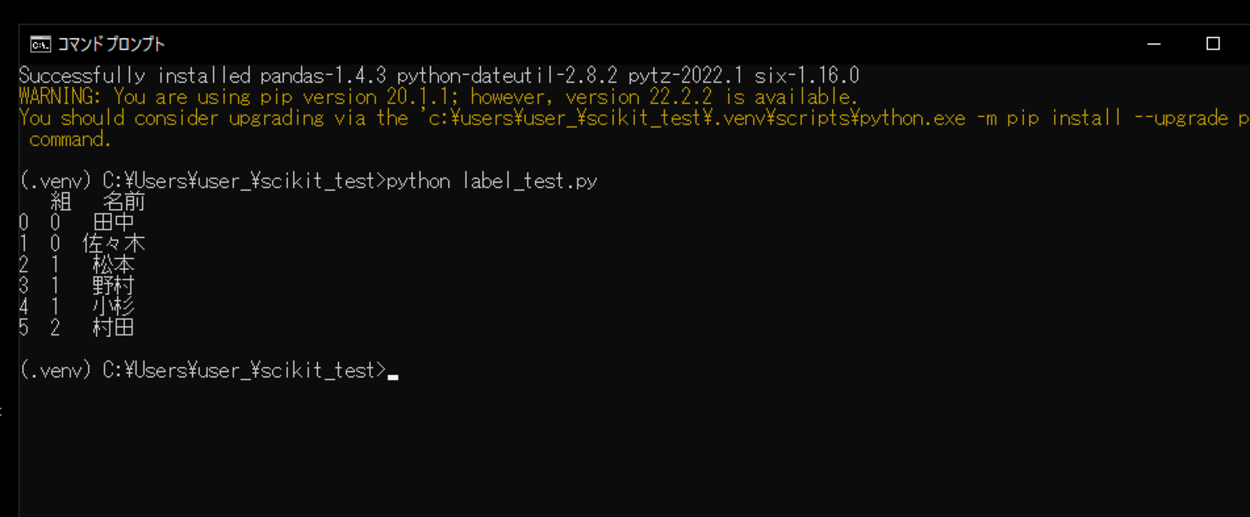
実行してみると、二次元の表形式のデータ(DataFrameオブジェクト)が出力されました。二次元の表形式のデータ(DataFrameオブジェクト)を確認すると、本来だと今回の辞書の「組」というキーには、アルファベットを設定していましたが、それが整数値に変換されていることが確認できました。

コメント