
pdfminer.sixを用いてPDFからテキストを抽出してみます。
今回はpdfminer.sixを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python
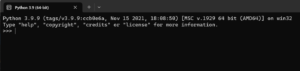
今回のPythonのバージョンは、「3.9.9」を使用しています。(Windows11)(pythonランチャーでの確認)
■PDF形式のファイルを用意する
まずpdfminer.sixを用いてPDFからテキストを抽出してみますが、その前にPDF形式のファイルを用意します。

今回は当サイト(https://laboratory.kazuuu.net/)をPDF化したファイル(test.pdf)を「C:\Users\user_\test_1(フォルダパス)」という場所に置きます。これで準備は完了となります。
■pdfminer.sixを用いてPDFからテキストを抽出する
では、次にpdfminer.sixを用いてPDFからテキストを抽出するスクリプトを書いていきます。
■コード
from pdfminer.high_level import extract_text text = extract_text(r"C:/Users/user_/test_1/test.pdf") print(text)
まずは、from importでpdfminerの高レベルの関数のextract_textを呼び出します。extract_textは、PDF ファイルに含まれるテキストを解析し、返します。
その後、textという変数を定義し、その中でextract_text()を用います。括弧内には引数,パラメータとして、作業対象のPDFファイルのファイルパスである「C:\Users\user_\test_1(フォルダパス)」を渡します。なお、特殊記号である「¥」を表記するために、バックスラッシュを用いています。これでPDF ファイルに含まれるテキストを解析し、返された結果をtext変数に格納。
格納後、print()でtext変数内の情報を出力します。
■実行・検証
このスクリプトを「pdf_c.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。

実行してみると、pdfminer.sixを用いてPDFからテキストを抽出し、抽出されたテキストを出力させることができました。

コメント