
PythonでPandasとSQLAlchemyを使用しSQLからデータを取得してみます。
なお、今回はPandasモジュールとSQLAlchemyモジュールの2つを用います。この2つのライブラリは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
また、今回はPostgreSQL データベースを用いますが、ElephantSQLを利用します。事前にElephantSQLの無料プランでアカウント登録を行い、インスタンスを作成した状態となっています。「ElephantSQL」のアカウント登録とインスタンスの作成についてこちらをご確認ください。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■ElephantSQLのインスタンスの状態を確認する
まずは、ElephantSQLのインスタンスの状態を確認してみます。Webブラウザで、ElephantSQL(https://customer.elephantsql.com/login)のログインページにアクセスし、登録したアカウント情報でログインを行います。
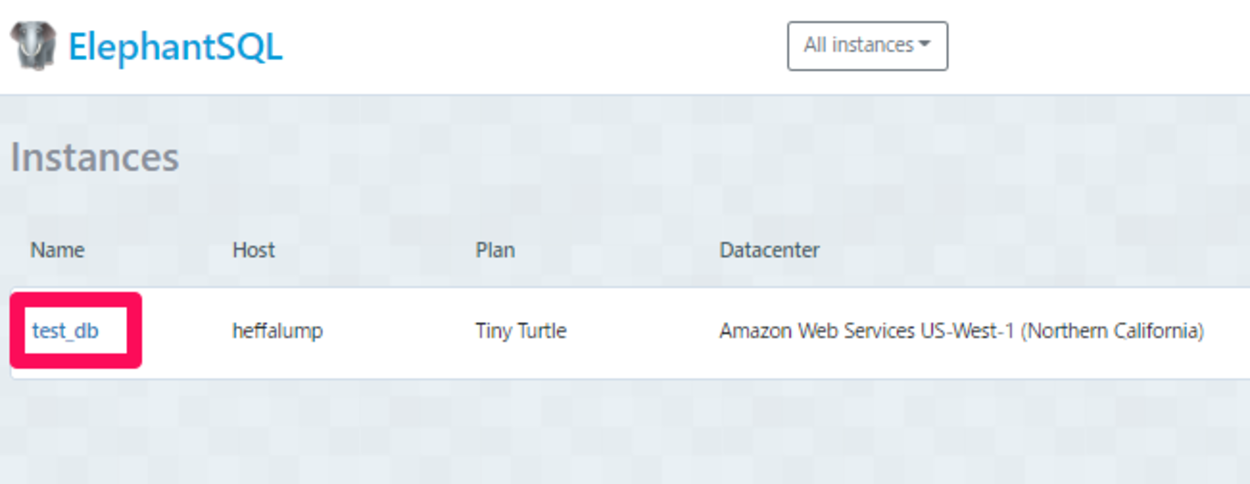
ログインを行うと、ElephantSQLの「Instances(インスタンス)」ページが表示されます。今回は事前に「test_db」というインスタンスを作成しています。このインスタンスの「Name」をクリックします。
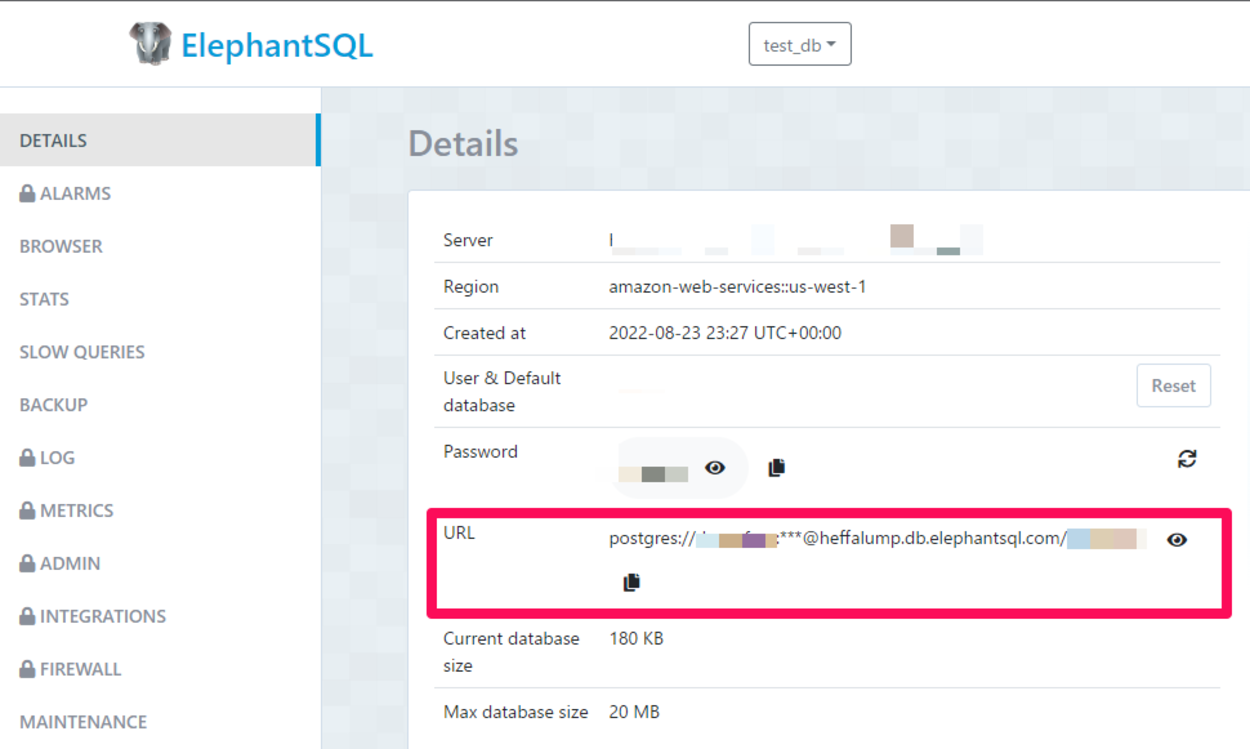
クリックすると、作成したインスタンスの「Details(詳細)」が表示されます。この「Details(詳細)」のURLの情報は今回使用しますので、コピーして保存しておきます。
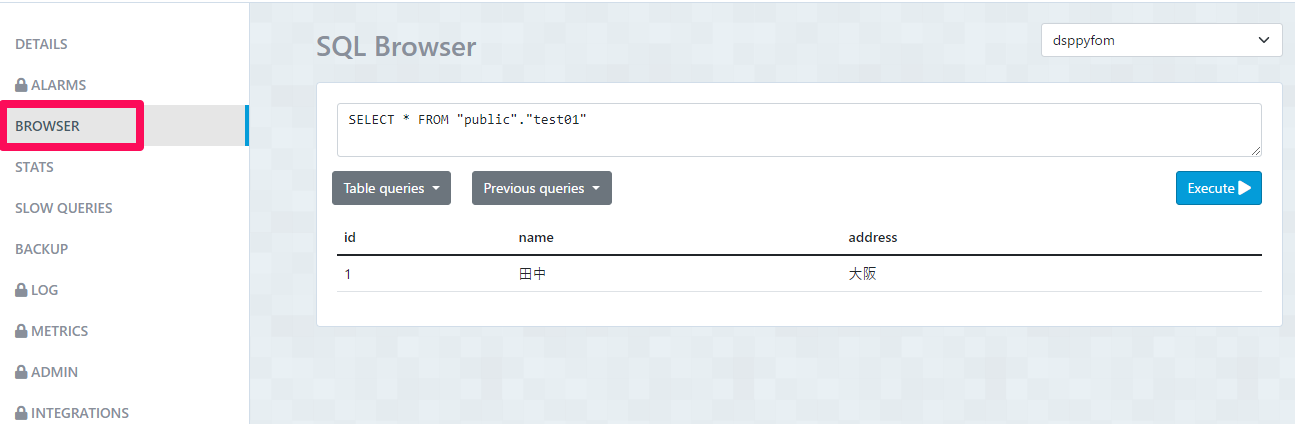
保存後、左側メニューから「BROWSER」をクリックします。クリックすると、命令文を用いてデータベースを操作できるので、テーブル等を確認します。確認してみると、今回は事前に「test01」というテーブルを作成しており、テーブル内に「id」、「name」、「address」という3つの列(カラム)が存在し、それぞれに値,データが挿入されていることが確認できます。
■PandasとSQLAlchemyを使用しSQLからデータを取得する
確認後、PandasとSQLAlchemyを使用しSQLからデータを取得するスクリプトを書いていきます。
■コード
import pandas as pd
import sqlalchemy as sql
connect=sql.create_engine("postgres://*****:*****@heffalump.db.elephantsql.com/dsppyfom(コピーしたURL)")
data = pd.read_sql(f'SELECT * FROM test01', con=connect)
print(data)今回は、importでpandasモジュールを呼び出し、これをpdとします(as)。さらにimportでsqlalchemyモジュールを呼び出し、これをsqlとします(as)。
その後、connectという変数を定義し、sql.create_engine()を用います。括弧内には引数,パラメータとして、先程コピーしたURLを貼り付けます。これで新しいEngineインスタンスが作成されます。
Engineインスタンスを作成後、dataという変数を定義し、その中でpd.read_sql()を用います。括弧内には第1の引数,パラメータとしてDataFrameとしてデータを読み込むために、実行するSQLクエリを渡します。今回はデータを取得するために、SELECT文を用いてtest01というテーブル内の全て(“*”,アスタリスク)のデータを取得します。次に第2の引数,パラメータとしてDB(データベース)を渡します。今回はconnect変数とします。これでSQLクエリを用いてSQLのデータを、DataFrameとして読み込みます。読み込んだものは、data変数に格納されます。
最後にdata変数内の情報をprint()で出力させます。
■実行・検証
このスクリプトを「db_p_data.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
Traceback (most recent call last):
File "db_p_data.py", line 4, in
connect=sql.create_engine("postgres://*****:*****@heffalump.db.elephantsql.com/dsppyfom(コピーしたURL)")
File "", line 2, in create_engine
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\sqlalchemy\util\deprecations.py", line 309, in warned
return fn(*args, **kwargs)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\sqlalchemy\engine\create.py", line 522, in create_engine
entrypoint = u._get_entrypoint()
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\sqlalchemy\engine\url.py", line 655, in _get_entrypoint
cls = registry.load(name)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\sqlalchemy\util\langhelpers.py", line 343, in load
raise exc.NoSuchModuleError(
sqlalchemy.exc.NoSuchModuleError: Can't load plugin: sqlalchemy.dialects:postgres実行してみると、「sqlalchemy.exc.NoSuchModuleError」というエラーが出力されました。エラーの内容を確認し、このエラーが発生する原因を調べてみると、SQLAlchemy1.4では、「postgres」という名前が非推奨であり削除され、代わりに「postgresql」という名前を使用する必要があることがわかりました。
■コード
import pandas as pd
import sqlalchemy as sql
connect=sql.create_engine("postgresql://*****:*****@heffalump.db.elephantsql.com/dsppyfom(コピーしたURL)")
data = pd.read_sql(f'SELECT * FROM test01', con=connect)
print(data)必要であることから、ElephantSQLの作成したインスタンスの「Details(詳細)」からコピーしたURLを変更しました。
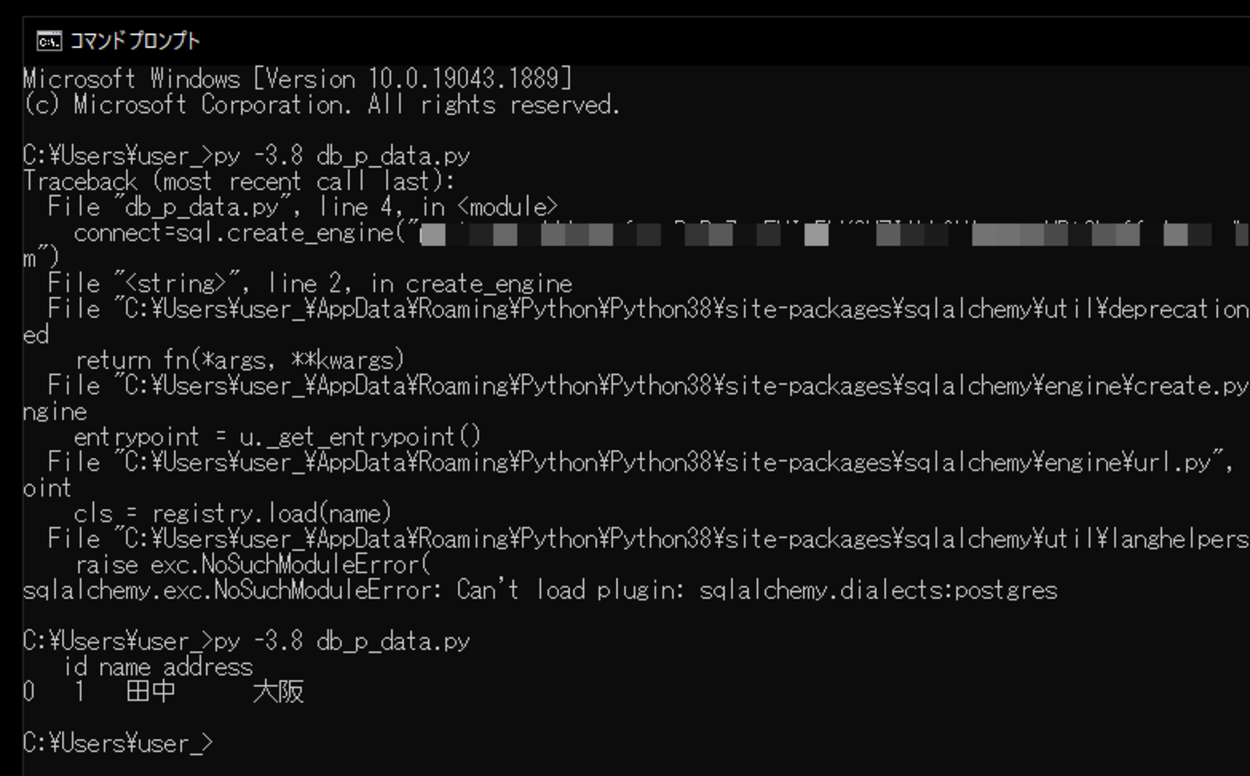
変更後、再度スクリプトを実行してみると、PandasとSQLAlchemyを使用しSQLからデータを取得し、取得したデータを出力させることができました。

コメント