
PythonでRPAライブラリ「tagui」を用いWEBの自動化を行ってみます。
今回は「tagui」を用います。「tagui」はPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■Webサイトに自動化でアクセスする
では、taguiを用いてWebサイトに自動化でアクセスするスクリプトを書いていきます。
■コード
import tagui as t
t.init()
t.url('https://www.google.com')
t.type('//*[@name="q"]','大阪市[enter]')
print(t.read('result-stats'))
t.snap('page','results.png')
t.close()importでtaguiモジュールを呼び出します。その後にinit()を用い初回起動時にtaguiを自動セットアップ。セットアップ後、url()を用いWebブラウザを起動し、括弧内に引数,パラメータとして渡したURLにアクセスします。今回はGoogle検索のURLを指定しています。
アクセス後、type()を用い括弧内に引数,パラメータとして渡した要素「//*[@name=”q”]」の箇所にテキストを入力します。今回は日本語で「大阪市」というキーワードを自動で入力します。
入力後、テキストの自動入力でGoogle検索結果が表示されますので、結果の数をprint()関数で出力します。出力後、snap()を用い括弧内に第1の引数,パラメータとして、要素の識別子として「page」を渡し、検索結果のページを指定します。第2の引数,パラメータとして、指定したページをスクリーンショットとして保存する指定(スクリーンショットのファイル名の指定)をします。これで、スクリーンショットが保存されます。
最後に、close()を用いWebブラウザを閉じプロセスを終了します。
■実行・検証
このスクリプトを「rpa_web.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
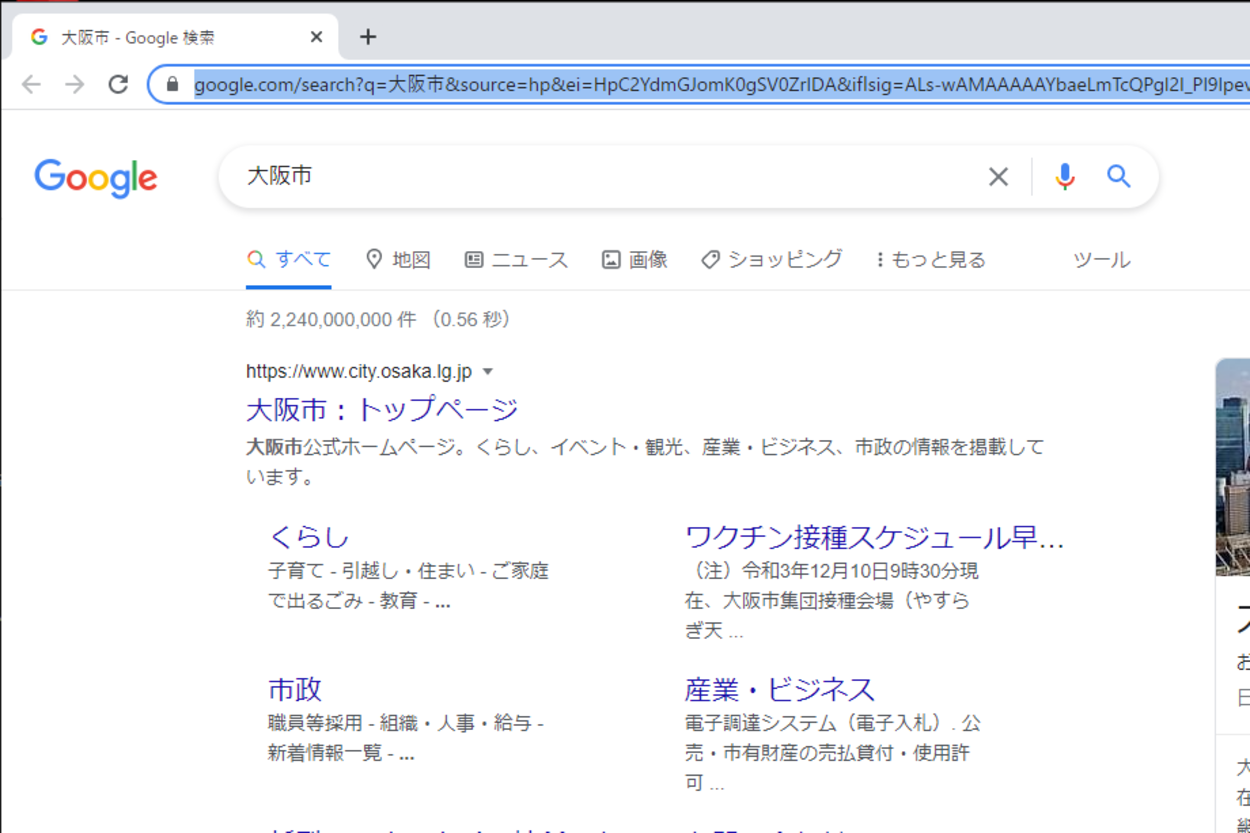
実行してみると、GoogleChromeが自動で起動し、検索窓に今回指定したキーワードである「大阪市」が自動入力で入力され、検索結果が表示されました。初回起動は、ChromeEngineなどが表示されます。
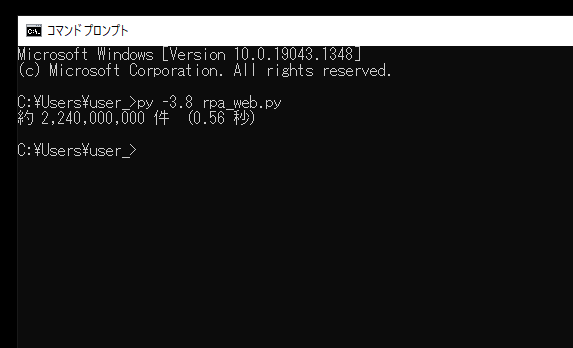
その後、コマンドプロンプト上にGoogle検索結果数が出力されました。
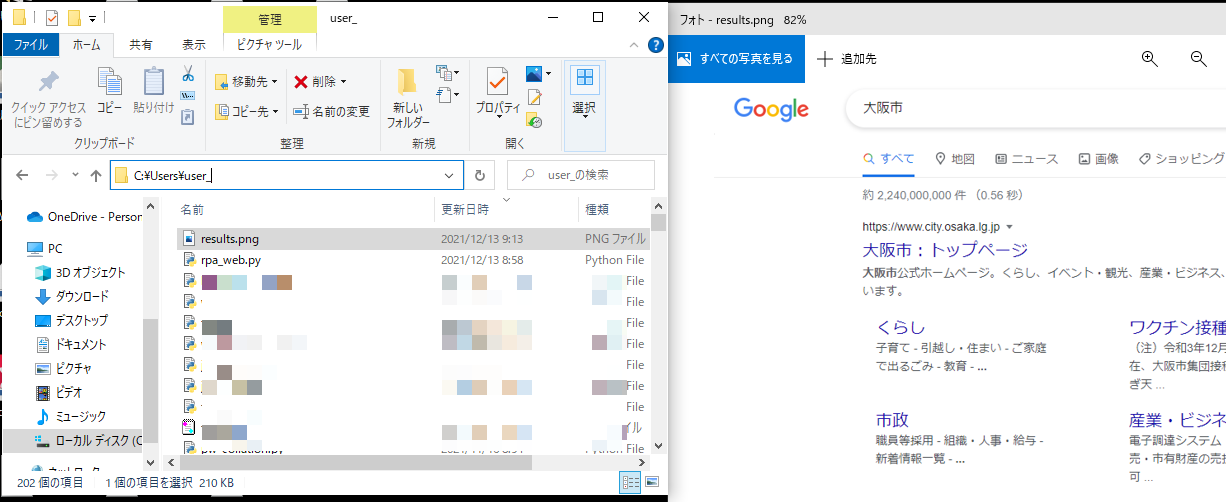
出力後、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)を確認すると、snap()を用いたことで、「results.png」というpng形式のスクリーンショット画像のファイルが出力されていました。ファイルを確認すると、スクリーンショットが撮影されていることが確認できました。

コメント