
PyOCRを利用して、Pythonで光学文字認識(OCR)を使用してみます。
なお、PyOCRを利用するには、事前にTesseractのインストールが必要となります。
またPythonでPyOCRを利用するには、PyOCRモジュールを事前にインストールする必要があります。画像処理ライブラリであるPILモジュールも事前にインストールが必要です。
■Python
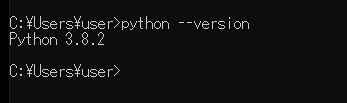
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■画像を用意する
Pythonで光学文字認識(OCR)を使用してみますが、その前に光学文字認識(OCR)で文字を読み取る画像を用意します。
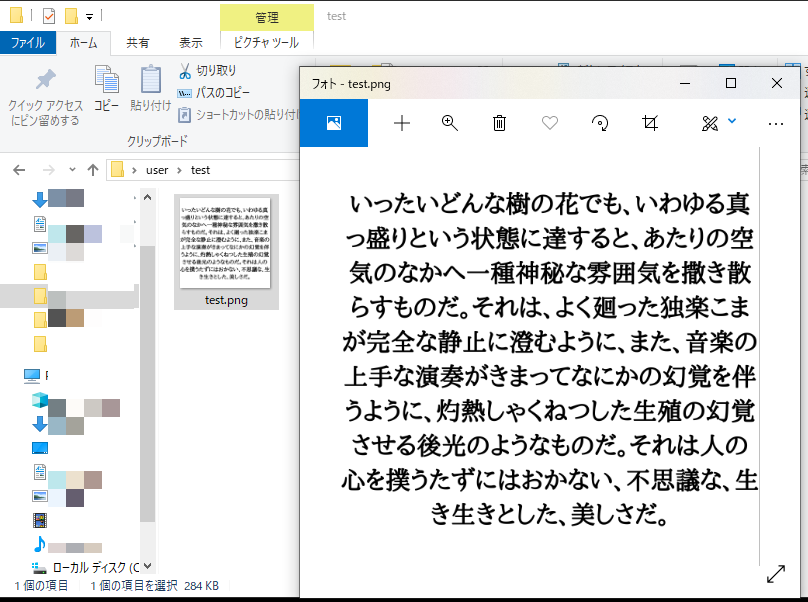
今回は上記のような画像ファイルを用意しました。画像は著作権切れした小説を公開している「青空文庫」のものを利用しています。
保存されている場所は「C:\Users\user\test(フォルダパス)」です。
■PyOCRを利用して文字を読み取る
画像の用意ができましたので、PyOCRモジュールを利用して文字を読み取るスクリプトを書いていきます。
■コード
import os
from PIL import Image
import pyocr
import pyocr.builders
path_tesseract = 'C:\\Program Files\\Tesseract-OCR'
if path_tesseract not in os.environ['PATH'].split(os.pathsep):
os.environ['PATH'] += os.pathsep + path_tesseract
tools = pyocr.get_available_tools()
tool = tools[0]
img_file = Image.open(r'C:\Users\user\test\test.png')
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img_file, lang='jpn', builder=builder)
print(result)インポートで今回用意したモジュールを呼び出して、path_tesseractという変数を作成します。作成後、事前にインストールしておいたTesseractを指定します。指定後、Tesseractのパスを通します。指定した環境変数を取得する場合はこちらが参考になります。
パスを通した後は、pyocr.get_available_tools()で光学文字認識(OCR)エンジン(Tesseract)を取得します。
取得した後は、img_fileという変数を作成し、Image.open()で今回用意した画像を指定し読み込みます。読み込んだ後、builderという変数を作成し、pyocr.buildersにある文字認識のためのTextBuilderを指定します。
指定後、resultという変数を作成し、取得した光学文字認識(OCR)エンジン(Tesseract)で読み込んだ画像の文字の認識(言語:jpn(日本語)を行います。
文字認識を行った結果をprint関数で出力します。
■実行
今回書いたスクリプトを「ocr_test.py」という名前で保存し、コマンドプロンプトから実行してみます。
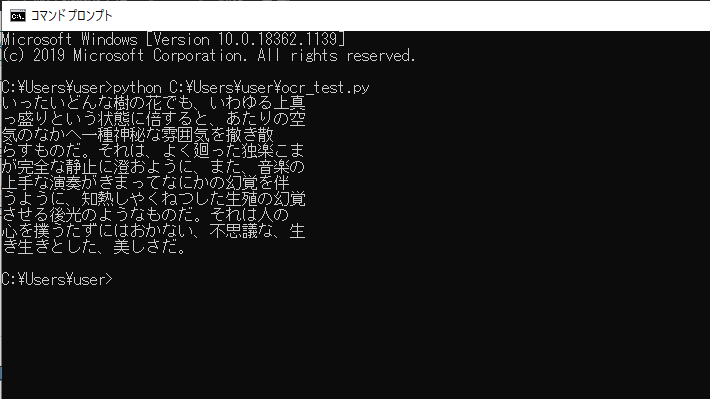
実行してみると、今回用意した画像に書かれている文字が光学文字認識(OCR)エンジンによって認識され出力されたことを確認できました。

コメント