
Pythonで非同期処理とタイムアウトの管理を組み合わせプログラムを作り実装してみます。
■今回の環境(Python)
今回のPythonはバージョン3.8.5を用いる。(Mac OS)
■非同期処理とタイムアウトの管理を組み合わせプログラムの作成
では、早速非同期処理とタイムアウトの管理を組み合わせプログラムを作成するために、コードを書いていきます。
■コード
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def get_website_data(url):
async with aiohttp.ClientSession() as session:
html = await fetch(session, url)
return url, html
async def main():
# 取得するWebサイトのURLリスト
urls = ["https://google.com", "https://github.com","https://******.com"]
# タスクを実行するためのイベントループを作成
loop = asyncio.get_event_loop()
tasks = []
for url in urls:
tasks.append(get_website_data(url))
# タスクの実行を待ち合わせる
done, pending = await asyncio.wait(tasks, timeout=5.0)
# 完了したタスクの結果を取得する
for task in done:
try:
url, result = await task
print("Webサイトのデータを取得しました:", url, result[:10]) # 最初の10文字のみ表示
except Exception as e:
print("タスクでエラーが発生しました:", str(e))
# タイムアウトしたタスクをキャンセルする
for task in pending:
task.cancel()
print("タスクがタイムアウトしましたのでキャンセルされました。")
if __name__ == "__main__":
asyncio.run(main())
■処理プロセス、関数の解説
fetch関数:
aiohttpライブラリを使用して、指定されたURLからデータを非同期に取得する関数です。
session.get(url)を使用してGETリクエストを行い、response.text()でレスポンスのテキストデータを取得します。
get_website_data関数:
aiohttp.ClientSessionを使用して非同期セッションを作成し、指定されたURLからデータを取得する関数です。fetch関数を呼び出してデータを取得し、URLと取得したデータをタプルとして返します。
main関数:
実際の処理の流れを制御するためのメイン関数です。取得するWebサイトのURLリストを定義します。asyncio.get_event_loopでイベントループを取得します。各URLに対してget_website_data関数を非同期タスクとして追加し、リストに格納します。asyncio.waitを使用してタスクの実行を待ち合わせます。指定されたタイムアウト時間内に完了しなかったタスクはキャンセルされます。完了したタスクの結果を処理し、URLと結果の一部を表示します。タイムアウトしたタスクはキャンセルされます。
if __name__ == “__main__”:のブロック:
プログラムが直接実行された場合にmain関数を実行します。asyncio.runを使用してイベントループを実行します。
■実行・検証
このスクリプトを「f_web_timeout.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、ターミナルから実行してみます。
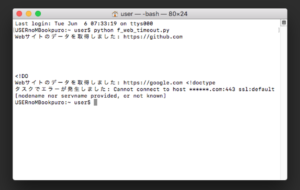
実行してみると、今回指定した複数のWebサイトのデータが非同期に取得され、タイムアウトの管理が行われます。各タスクの結果が表示されました。結果では「https://******.com」という存在しないWebサイトも含まれており、この場合は「タスクでエラーが発生しました: Cannot connect to host ******.com:443 ssl:default [nodename nor servname provided, or not known]」と表示されることを確認しました。

またページ表示が重いWebサイトで検証を行うと「タスクがタイムアウトしましたのでキャンセルされました。」となることも確認できました。

コメント