
PythonでJSON文字列をテキストファイルに変換してみます。
なお、今回変換を行う際にpandasモジュールを使用します。pandasモジュールはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■JSON文字列のファイルを用意する
JSON文字列をテキストファイルに変換してみますが、その前にJSON文字列のファイルを用意します。

[
{“Product”:”Desktop Computer”,”Price”:50000,””:””},
{“Product”:”Tablet”,”Price”:25000,””:””},
{“Product”:”iPhone”,”Price”:80000,””:””},
{“Product”:”Smart watch”,”Price”:20000,””:””}
]
今回は上記のJSON文字列のファイルを用意しました。
ファイルが保存されている場所は「C:\Users\user\test(フォルダパス)」です。
■JSON文字列をテキストファイルに変換する
JSON文字列のファイルが用意できましたので、JSON文字列をテキストファイルに変換するスクリプトを書いていきます。
import pandas as pd df = pd.read_json(r"C:\Users\user\test\sample.json") df.to_csv(r"C:\Users\user\test\json_text.txt", index = False)
インポートでpandasモジュールを呼び出します。dfという変数を作成し、pd.read_json()で今回用意したJSON文字列のファイルを読み込みますので、括弧内にJSON文字列のファイルを指定します。
指定後、df.to_csv()でCSVファイルの書き出しを行いますので、括弧内に書き出すファイル名と場所を指定します。このときにCSVファイルの書き出しを行いますが、今回はテキストファイルに変換するため、「.txt」と記述し、テキストファイルでの書き出しを行います。なお、括弧内で第2の引数に「index=False」を指定するとインデックスが書き込まれません。
■実行
今回のスクリプトを「convert_jsonfile_to_textfile.py」という名前で保存し、コマンドプロンプトから実行してみます。
** On entry to DGEBAL parameter number 3 had an illegal value
** On entry to DGEHRD parameter number 2 had an illegal value
** On entry to DORGHR DORGQR parameter number 2 had an illegal value
** On entry to DHSEQR parameter number 4 had an illegal value
Traceback (most recent call last):
File “C:\Users\user\convert_jsonfile_to_textfile.py”, line 1, in <module>
import pandas as pd
File “C:\pg\Python38\lib\site-packages\pandas\__init__.py”, line 11, in <module>
__import__(dependency)
File “C:\pg\Python38\lib\site-packages\numpy\__init__.py”, line 305, in <module>
_win_os_check()
File “C:\pg\Python38\lib\site-packages\numpy\__init__.py”, line 302, in _win_os_check
raise RuntimeError(msg.format(__file__)) from None
RuntimeError: The current Numpy installation (‘C:\\pg\\Python38\\lib\\site-packages\\numpy\\__init__.py’) fails to pass a sanity check due to a bug in the windows runtime. See this issue for more information: https://tinyurl.com/y3dm3h86
実行してみると、上記のエラーが発生しました。エラーの内容を確認すると「Windowsランタイムのバグのため、サニティチェックに合格しません。」というものでWindowsに問題があるようです。
■エラーの対処方法
現在のPandasモジュールのバージョンが「pandas 1.1.4」を使用していますので、バージョンが古いものをインストールしてみます。
Pandasモジュールをインストールを行いますが、今回はpipを経由してインストールを行うので、まずWindowsのコマンドプロンプトを起動します。
pip install numpy==1.19.3
起動後、上記のコマンドを入力し、Enterキーを押します。
なお、今回は、pythonランチャーを使用しており、Python Version 3.8.5にインストールを行うために、pipを使う場合にはコマンドでの切り替えを行います。
py -3.8 -m pip install numpy==1.19.3
切り替えるために、上記のコマンドを入力し、Enterキーを押します。
Collecting numpy==1.19.3
Downloading numpy-1.19.3-cp38-cp38-win_amd64.whl (13.3 MB)
|████████████████████████████████| 13.3 MB 3.3 MB/s
Installing collected packages: numpy
Attempting uninstall: numpy
Found existing installation: numpy 1.19.4
Uninstalling numpy-1.19.4:
Successfully uninstalled numpy-1.19.4
Successfully installed numpy-1.19.3
Enterキーを押すと、インストールが開始され、「Successfully uninstalled」と表示されます。これで「pandas 1.1.4」がアンインストールされます。続いて「Successfully installed」と表示されますので、これが表示されれば、古いバージョンがインストール完了となります。
■再度実行する
インストール完了後、「convert_jsonfile_to_textfile.py」のスクリプトを実行してみます。
C:\Users\user>py -3.8 C:\Users\user\convert_jsonfile_to_textfile.py
Traceback (most recent call last):
File "C:\Users\user\convert_jsonfile_to_textfile.py", line 3, in
df = pd.read_json(r'C:\Users\user\test\sample.json')
File "C:\pg\Python38\lib\site-packages\pandas\util\_decorators.py", line 199, in wrapper
return func(*args, **kwargs)
File "C:\pg\Python38\lib\site-packages\pandas\util\_decorators.py", line 296, in wrapper
return func(*args, **kwargs)
File "C:\pg\Python38\lib\site-packages\pandas\io\json\_json.py", line 618, in read_json
result = json_reader.read()
File "C:\pg\Python38\lib\site-packages\pandas\io\json\_json.py", line 755, in read
obj = self._get_object_parser(self.data)
File "C:\pg\Python38\lib\site-packages\pandas\io\json\_json.py", line 777, in _get_object_parser
obj = FrameParser(json, **kwargs).parse()
File "C:\pg\Python38\lib\site-packages\pandas\io\json\_json.py", line 886, in parse
self._parse_no_numpy()
File "C:\pg\Python38\lib\site-packages\pandas\io\json\_json.py", line 1119, in _parse_no_numpy
loads(json, precise_float=self.precise_float), dtype=None
ValueError: Expected object or value上記のエラーが発生しました。調べてみると、JSON文字列内の引用符はダブルクォート(”)でないといけないので、シングルクォート(’)の場合はエラーとなります。しかし、JSON文字列のファイルを確認すると、引用符は全てダブルクォート(”)となっていました。
■ValueError: Expected object or valueの対処方法
「ValueError: Expected object or value」となる原因を調べてみると、UTF-8→SJISに変換してみるとこの問題を解決できるという記事を発見し試みる。
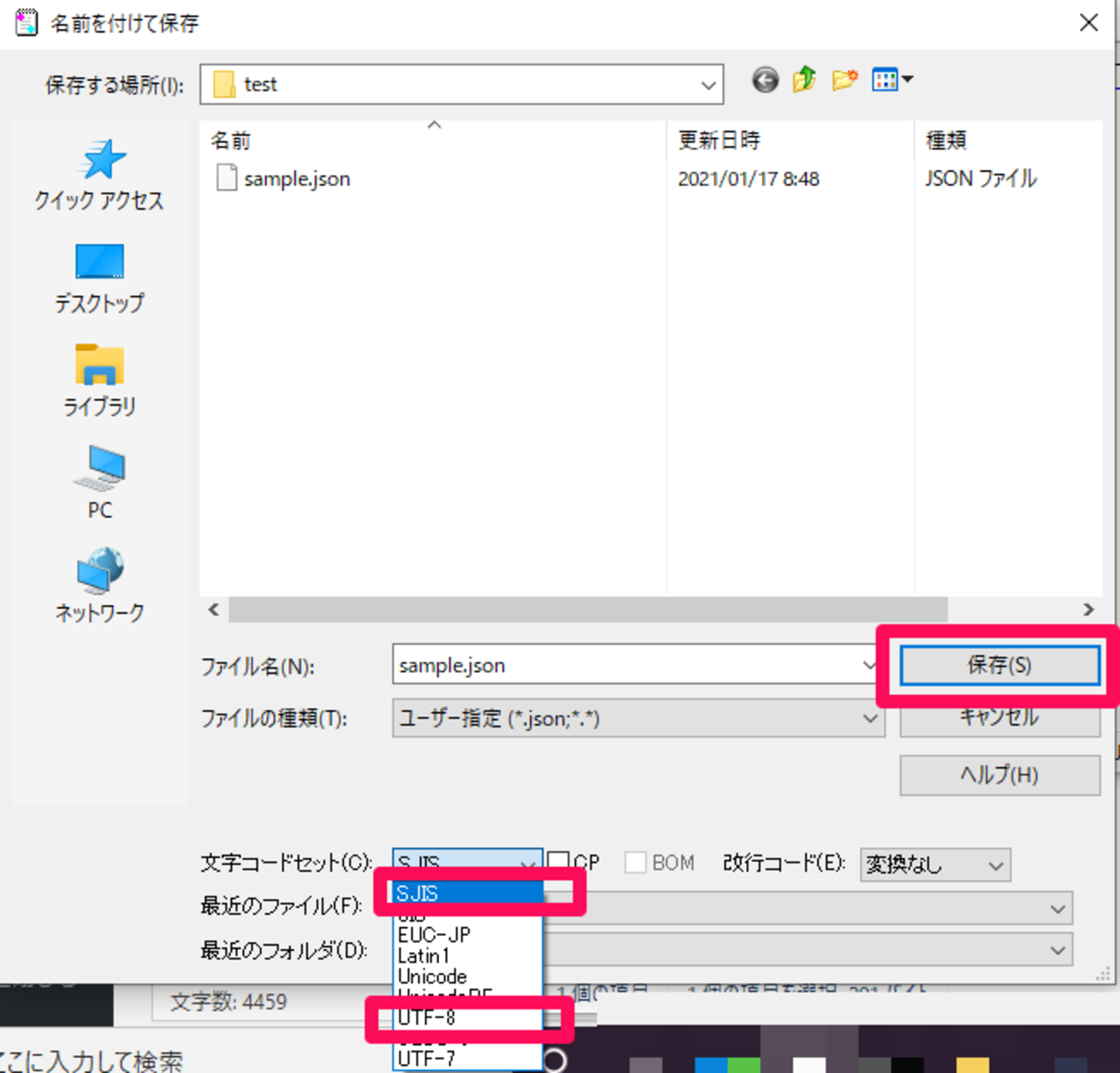
JSON文字列のファイルをテキストエディタ(今回はサクラエディタ)で開き、名前を付けて保存する際に、文字コードセットを「UTF-8」から「SJIS」に変更し、保存する。
■JSON文字列のファイルの文字コードを変更し実行する
保存後、「convert_jsonfile_to_textfile.py」のスクリプトを実行してみます。

実行してみると、「.txt」というテキストファイルが保存されていることを確認できました。ファイルの中身を確認すると、JSON文字列がテキストファイルに変換されていることも確認できました。

コメント