
PandasにおけるDataFrameで重複をカウントしてみます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■DataFrameを作成する
DataFrameで重複をカウントする前に、DataFrameを作成します。
■コード
import pandas as pd
data = {
'名前':['田村','吉田','小杉','林','中山'],
'出身':['北海道','青森','岐阜','福井','山口'],
'職業':['弁護士','インストラクター','弁護士','弁護士','プログラマー']
}
df = pd.DataFrame(data)
print(df)インポートでPandasモジュールを呼び出します。dataという変数を作成し、その中に、今回は「名前」,「出身」,「職業」という3つの行を追加し格納します。今回は「職業」の列に重複する値を格納しています。
格納後、dfという変数を作成し、pd.DataFrame()と記述し、格納したdataを元にDataFrameを作成。作成後、dfという変数に格納します。
■実行
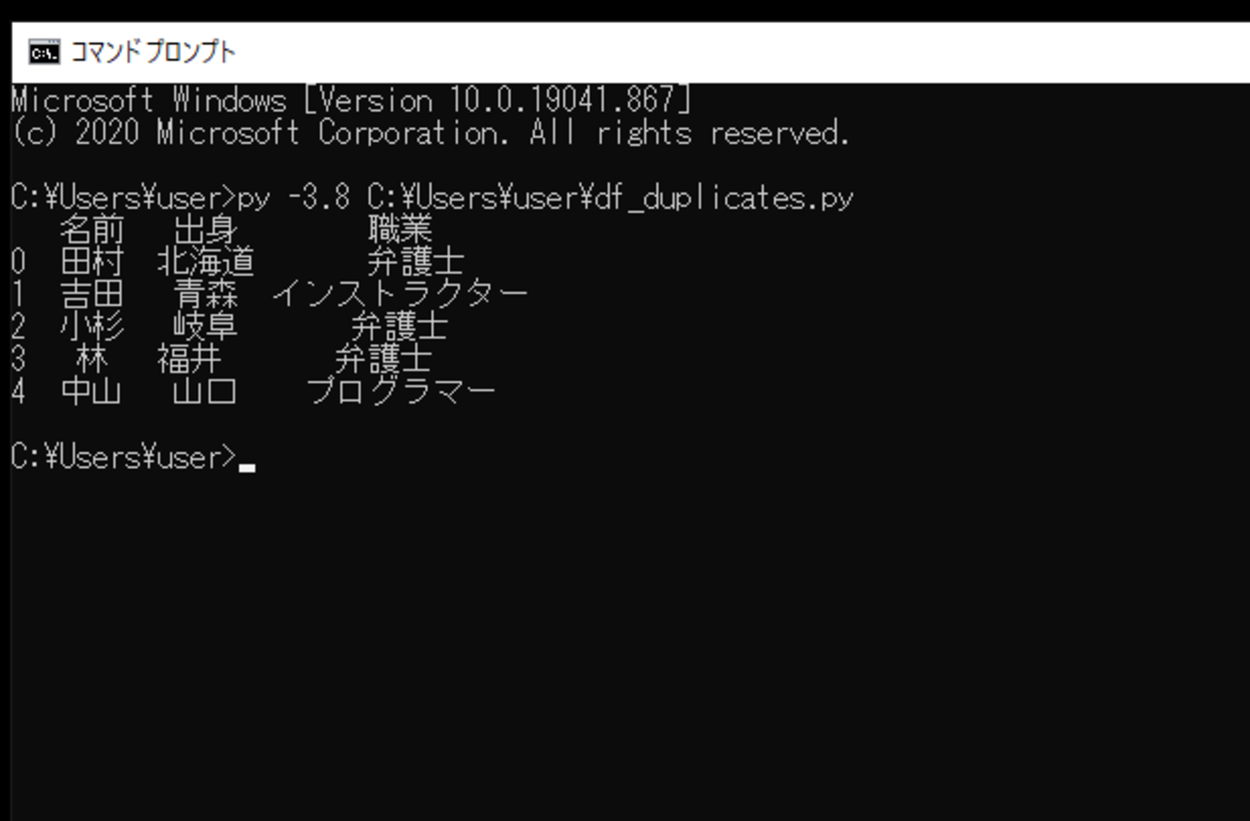
このスクリプトを実行すると、作成したDataFrameが出力されます。
■DataFrameで重複をカウントする
DataFrameの用意ができましたので、DataFrameで重複をカウントするスクリプトを書いていきます。
■コード
import pandas as pd
data = {
'名前':['田村','吉田','小杉','林','中山'],
'出身':['北海道','青森','岐阜','福井','山口'],
'職業':['弁護士','インストラクター','弁護士','弁護士','プログラマー']
}
df = pd.DataFrame(data)
duplicates01 = df.pivot_table(index = ['職業'], aggfunc = 'size')
print(duplicates01)DataFrameで重複をカウントする場合は、dfという変数を作成し、格納したdataを元にDataFrameを作成。その後に、duplicates01という変数を作成し、dfという変数に対して、pivot_table()を使用し、ピボットテーブルを作成します。作成するピボットテーブルは、「index = [‘職業’]」で対象をdfという変数内の「職業」の列に設定し、「aggfunc = ‘size’」と記述することで、dfという変数内の「職業」の列の中で集計を行うことができます。
集計を行った結果をduplicates01という変数に格納します。
格納後、print関数でduplicates01という変数の情報を出力します。
■実行
このスクリプトを「df_duplicates_2.py」という名前で保存し、コマンドプロンプトから実行してみます。
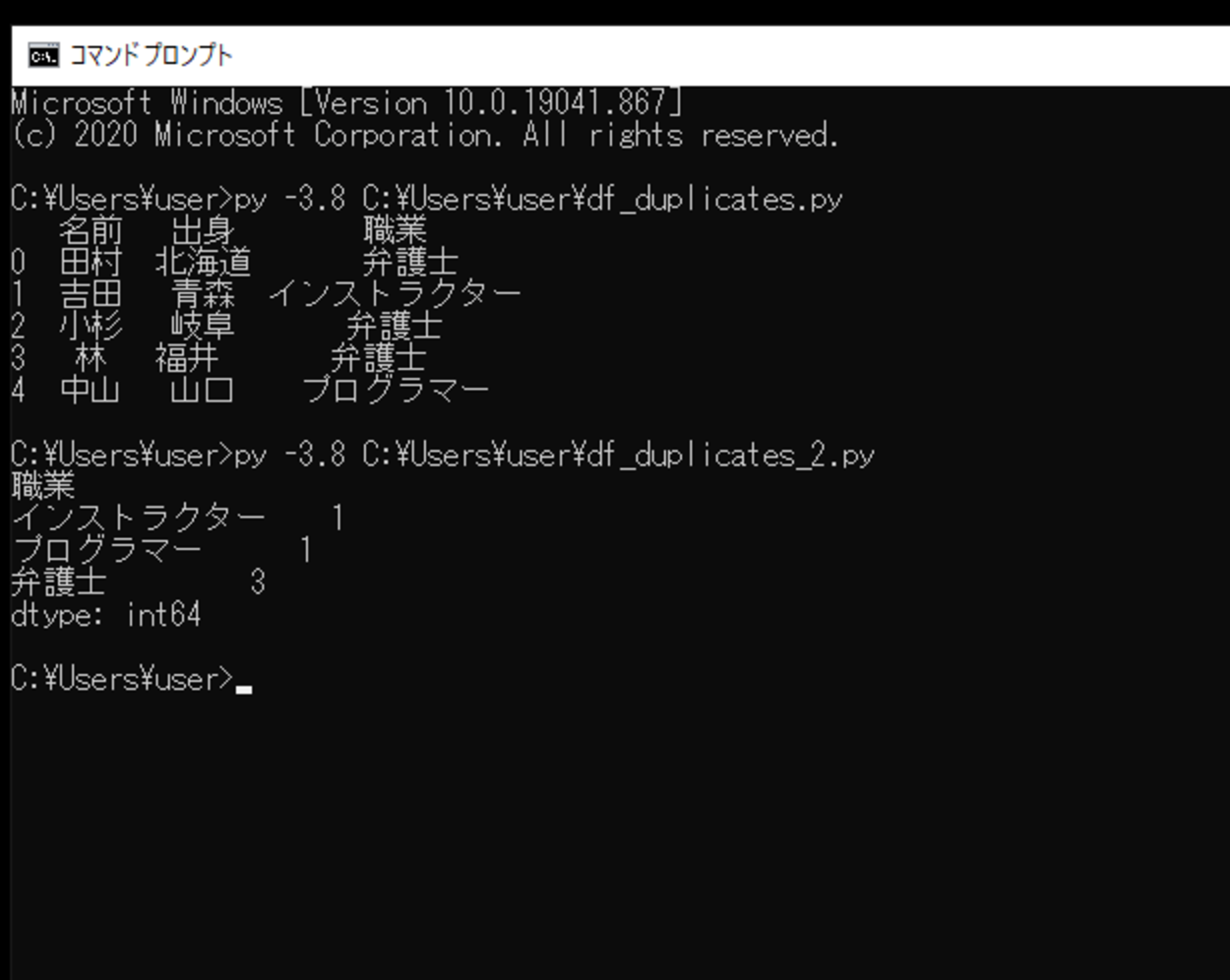
実行してみると、作成したDataFrameの特定の列の値が集計され重複がカウントされ、どこが重複しているのかを確認することができました。
■複数の列にまたがる重複をカウントする
では、次に複数の列にまたがる重複をカウントすることもできますので、やってみます。
■コード
import pandas as pd
data = {
'名前':['田村','吉田','小杉','林','中山'],
'出身':['北海道','青森','岐阜','福井','山口'],
'職業':['弁護士','インストラクター','弁護士','弁護士','プログラマー'],
'転職の有無':['有','無','有','有','無']
}
df = pd.DataFrame(data)
duplicates01 = df.pivot_table(index = ['職業','転職の有無'], aggfunc = 'size')
print(df)
print(duplicates01)先ほどは単一の列の重複をカウントしましたが、今回は複数の列にまたがる重複をカウントしますが、方法は単一の列の重複をカウントする場合とほとんど変わりません。duplicates01という変数を作成し、dfという変数に対して、pivot_table()を使用し、ピボットテーブルを作成します。この作成したピボットテーブルで、「index = [‘職業’,’転職の有無’]」で対象をdfという変数内の「職業」と「転職の有無」の複数の列に設定すれば、列にまたがる重複をカウントすることができます。
■実行
このスクリプトを「df_duplicates_3.py」という名前で保存し、コマンドプロンプトから実行してみます。
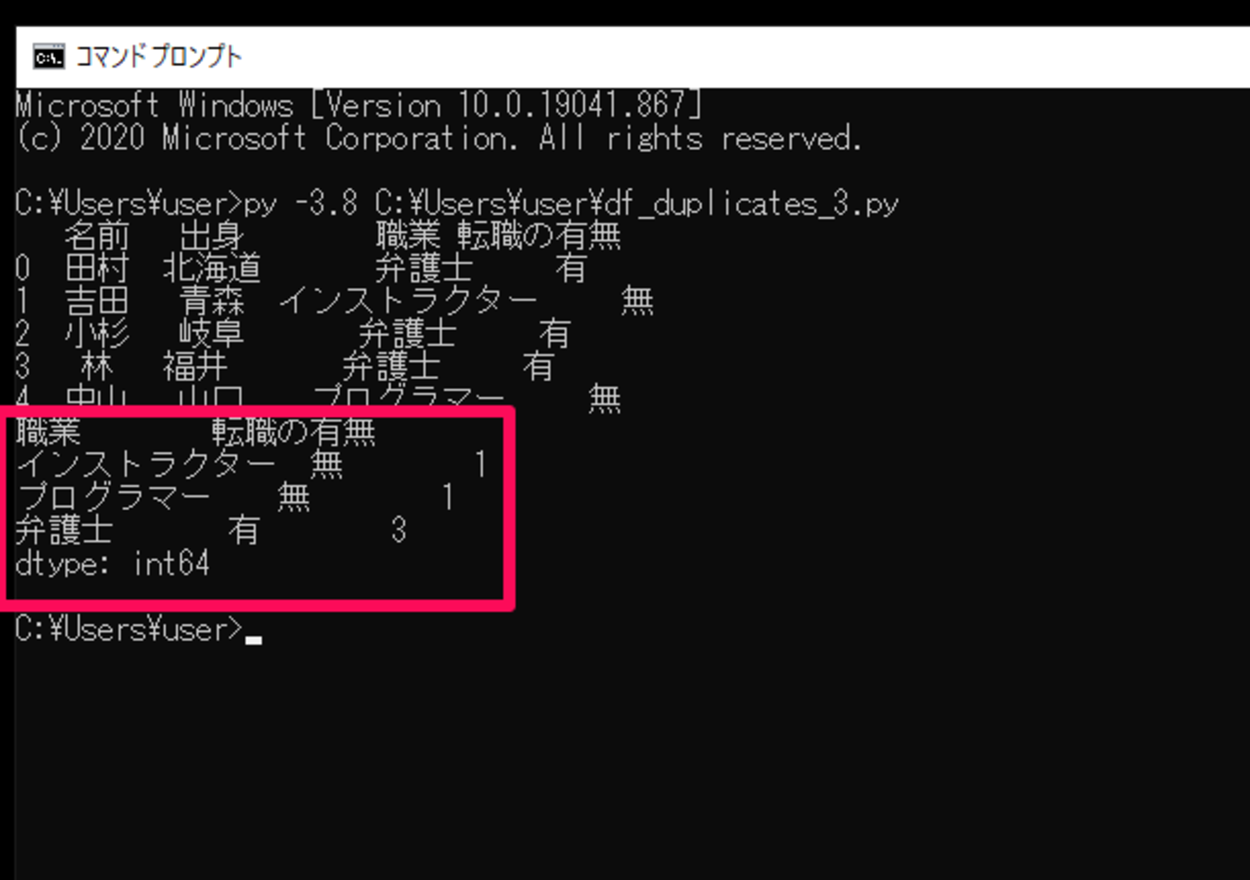
実行してみると、複数の列の値が集計され重複がカウントされていることが確認できました。

コメント