
Pythonでtiktokenを用いてトークンを数えてみます。これにより、OpenAIのAPI呼び出しがいくらかかるかが概算でわかります。なお、OpenAIのAPIを利用する場合の料金はトークン単位。
今回はtiktokenを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので事前にインストールする必要があります。
■Python
今回のPythonのバージョンは、「3.9.9」を使用しています。(Windows11)(pythonランチャーでの確認)
■tiktokenを用いてトークンを数える
では、早速tiktokenを用いてトークンを数えるスクリプトを書いていきます。
■コード
import tiktoken
def print_cl100k_encodings(example_string: str) -> None:
encoding_name = "cl100k_base"
encoding = tiktoken.get_encoding(encoding_name)
token_integers = encoding.encode(example_string)
num_tokens = len(token_integers)
token_bytes = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f"{encoding_name}: {num_tokens} tokens")
print(f"token integers: {token_integers}")
print(f"token bytes: {token_bytes}")
example_string = "こんにちは、世界"
print_cl100k_encodings(example_string)まずは、import tiktokenでtiktokenモジュールをインポートします。次にdef print_cl100k_encodings(example_string: str) -> None:と記述し、print_cl100k_encodingsという関数を定義しています。この関数は引数としてexample_stringという文字列を受け取り、何も返さない(Noneを返す)ようにアノテーションします。関数内では、encoding_name = “cl100k_base”と記述し、使用するエンコーディングの名前を指定します。ここではcl100k_baseというOpenAIのモデルで使われている3つのエンコーディング(gpt-4, gpt-3.5-turbo, text-embedding-ada-002)をサポートしているものを使用します。
次にencoding = tiktoken.get_encoding(encoding_name)と記述し、tiktoken.get_encoding()関数を使用して、指定されたエンコーディング名に基づいてエンコーディングオブジェクトを取得します。取得後、token_integers = encoding.encode(example_string)では、encoding.encode()メソッドを使用して、指定された文字列example_stringをエンコードし、トークンの整数値のリストを取得します。取得後、num_tokens = len(token_integers)では、token_integersの長さを計算して、トークンの数を取得します。
取得後、token_bytes = [encoding.decode_single_token_bytes(token) for token in token_integers]と記述し、encoding.decode_single_token_bytes()メソッドを使用して、各トークンのバイト表現をデコードし、token_bytesというリストに格納しています。リスト内包表記を使用して、token_integersの各要素に対してデコード処理を行います。次にprint(f”{encoding_name}: {num_tokens} tokens”)と記述し、encoding_nameとnum_tokensをフォーマットして表示し、使用されたエンコーディング名とトークンの数を表示します。なお、f文字列(f-strings)を用いてPythonの文字列内で変数や式を埋め込みます。次にprint(f”token integers: {token_integers}”)と記述し、token_integersを表示し、トークンの整数値のリストを表示します。次にprint(f”token bytes: {token_bytes}”)と記述し、token_bytesを表示し、トークンのバイト表現のリストを表示します。
その後、example_string = “こんにちは、世界”と記述し、example_stringという変数に、今回は日本語の文字列である”こんにちは、世界”を代入します。
最後にprint_cl100k_encodings(example_string)と記述し、example_stringを引数,パラメータとしてprint_cl100k_encodings関数を呼び出し、エンコーディング結果を表示しています。
■検証・実行
今回書いたスクリプトを「tokencount.py」という名前でPythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
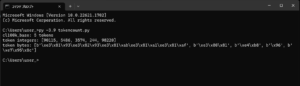
実行してみると、指定された日本語の文字列がcl100k_baseエンコーディングで符号化され、トークンの整数値とバイト表現、トークンの数が表示することを確認できました。

コメント