
Pythonでpdfkitを使用しHTMLからPDFを作成してみます。
なお、今回はWebページをPDFとしてダウンロードするために、Pythonにpdfkitモジュールのインストールと、Windows10にwkhtmltopdfのインストールを行っています。これらがインストールされていないと、HTMLからPDFを作成することはできません。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■HTMLからPDFを作成する
では、早速HTMLからPDFを作成するスクリプトを書いていきます。
■コード
import pdfkit
html = '<!doctype html><html lang="ja"><head><meta charset="UTF-8"></head><body><h1>サンプルPDFファイル</h1><br></br><p>・テスト1</p><p>・テスト2</p><p>・テスト3</p></body></html>'
config = pdfkit.configuration(wkhtmltopdf = r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe")
pdfkit.from_string(html, output_path="html_test.pdf", configuration=config)
インポートでpdfkitモジュールを呼び出します。
呼び出した後に、htmlという変数を作成し、その中にPDFを作成するためのHTMLコードを記述します。なお、日本語のPDFを作成するためには記述の際に、「<meta charset=”utf-8/”>」を記述します。これがないと、文字化けが発生します。またHTMLコードを囲うときは、ダブルクオーテーション(””)ではなく、シングルクォーテーション(”)を使用します。これを使用しないと「SyntaxError: invalid syntax」というエラーが発生します。
その後に、configという変数を作成し、その中で、pdfkit.configuration()関数を使用し、括弧内にWindows10にインストールしたwkhtmltopdfのwkhtmltopdf.exeというファイルを指定し、格納します。
格納後、pdfkit.from_string()関数を使用し、第1の引数にPDFファイルを作成するためのHTMLを指定します。第2の引数に、作成されるPDFファイルの名前を指定します。第3の引数には、「configuration =config」と記述し、格納します。
これでWebページをPDFファイルとしてダウンロードすることができます。
■実行
このスクリプトを「create_pdf_html.py」という名前で保存し、コマンドプロンプトから実行してみます。

Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
実行してみると、上記のメッセージが表示され、最後に「Done(完了)」と表示されます。これが表示されれば、PDFファイルの作成は完了となります。
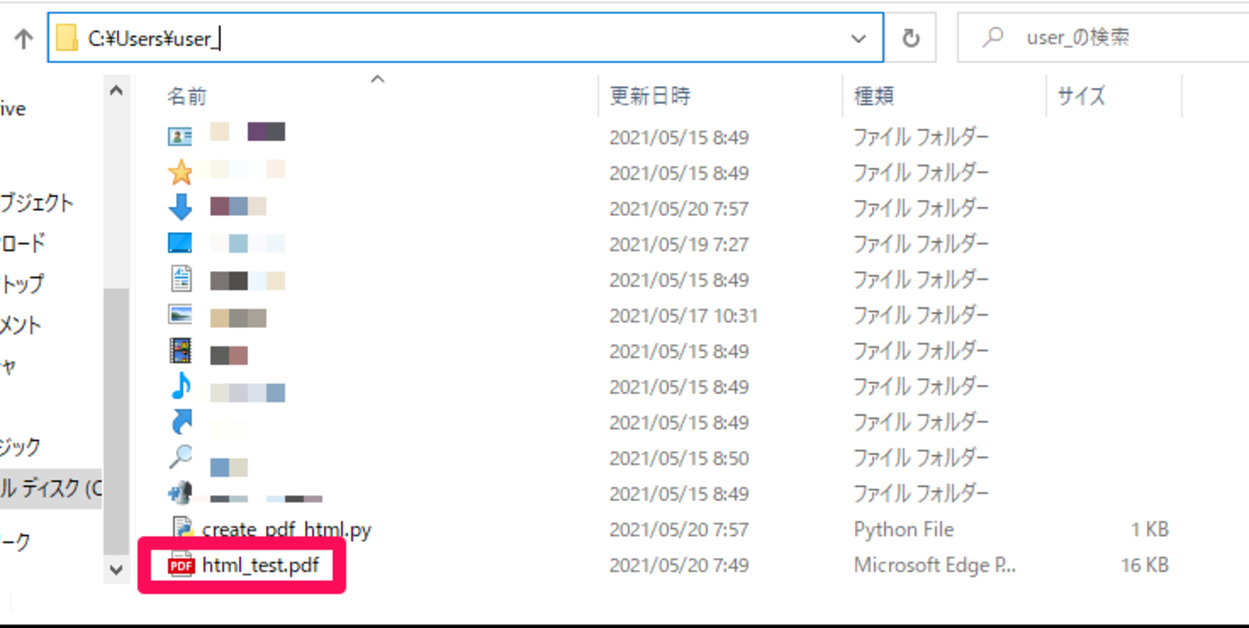
完了後、作業ディレクトリ(カレントディレクトリ)を確認すると、「html_test.pdf」というファイルが出力されていることが確認できました。

確認後、PDFファイルの中身を確認しましたが、今回記述したHTMLのデータがPDFファイルに書き込まれていることが確認できました。

コメント