
Pythonでpdf2docxを用いて簡単にPDFからDOCXに変換してみます。
今回はpdf2docxを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので事前にインストールする必要があります。
■Python
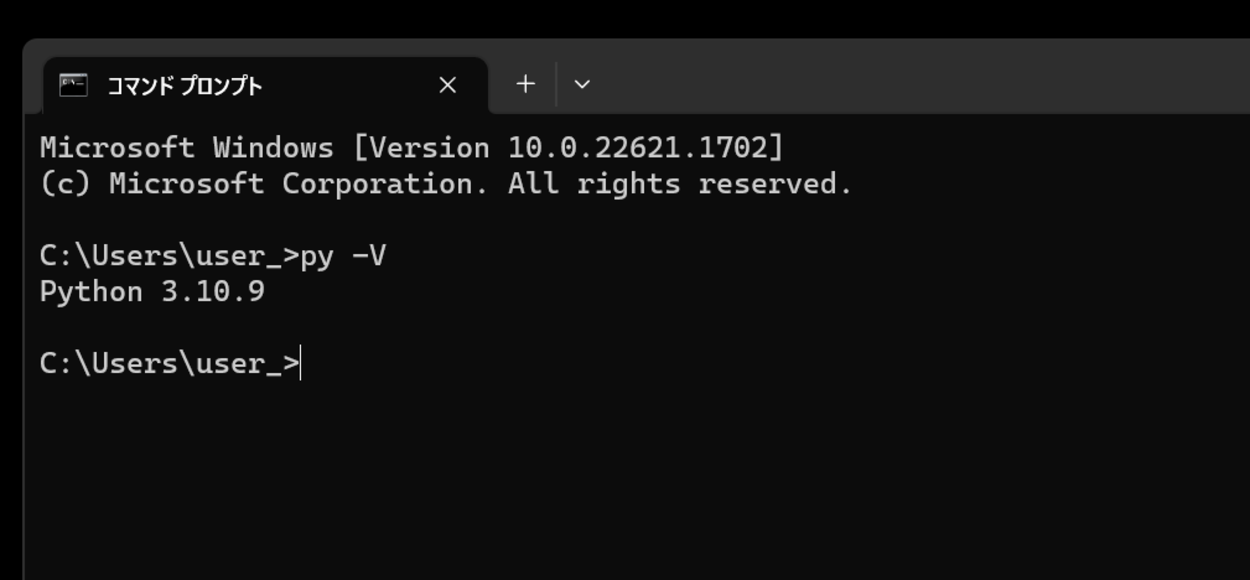
今回のPythonのバージョンは、「3.10.9」を使用しています。(Windows11)(pythonランチャーでの確認)
■変換するための準備
PDFからDOCXに変換してみますが、その前に準備を行います。
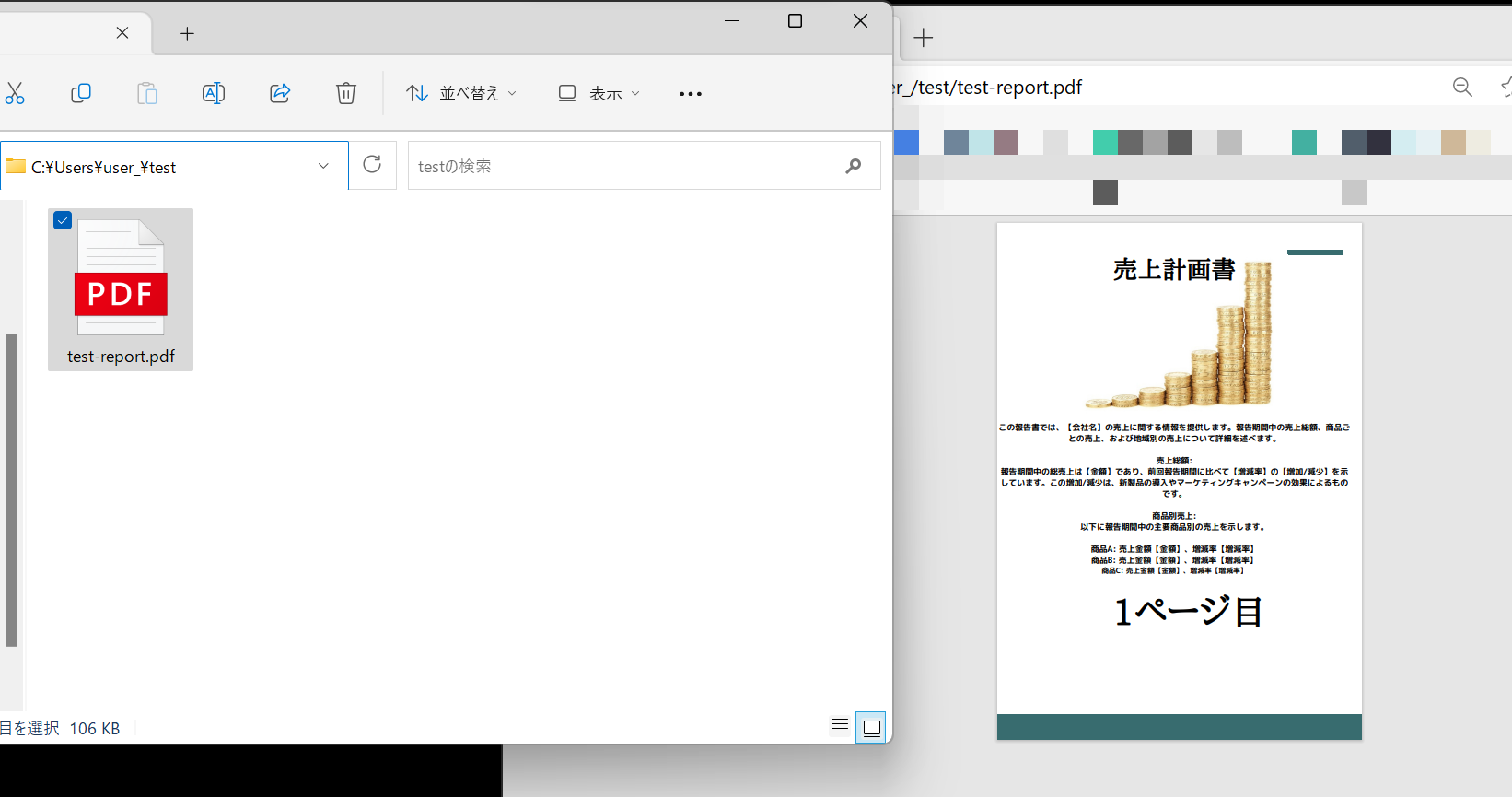
今回は分かりやすいように「C:\Users\user_\test(フォルダパス)」という場所を用意します。この場所に「test-report.pdf」というファイルを置きます。このPDFファイルで用いている画像は著作権フリー素材となります。これで準備は完了となります。
■pdf2docxを用いてPDFからDOCXに変換する
次にpdf2docxを用いてPDFからDOCXに変換するためのスクリプトを書いていきます。
■コード
from pdf2docx import Converter pdf_file = r"C:\Users\user_\test\test-report.pdf" docx_file = r"C:\Users\user_\test\c_result_report.docx" cv = Converter(pdf_file) cv.convert(docx_file) cv.close
まずはpdf2docxモジュールのConverterクラスをインポートします。次に変換元のPDFファイルのパスをpdf_file変数に指定します。今回は「C:\Users\user_\test\test-report.pdf」です。次に変換後のDOCXファイルのパスをdocx_file変数に指定します。今回は「C:\Users\user_\test\c_result_report.docx」です。Converterクラスのインスタンスを作成し、pdf_fileを引数として渡します。これにより、PDFファイルが変換プロセスの対象になります。cv.convert(docx_file)を呼び出して、PDFファイルをDOCXファイルに変換します。docx_fileは、変換後のDOCXファイルのパスです。
変換が完了したら、cv.close()を呼び出してConverterクラスのインスタンスを閉じます。実行すると、指定したPDFファイルがDOCXファイルに変換されます。変換されたDOCXファイルは、docx_fileで指定したパスに保存されます。
■実行・検証
今回書いたスクリプトを「test_converter.py」という名前でPythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
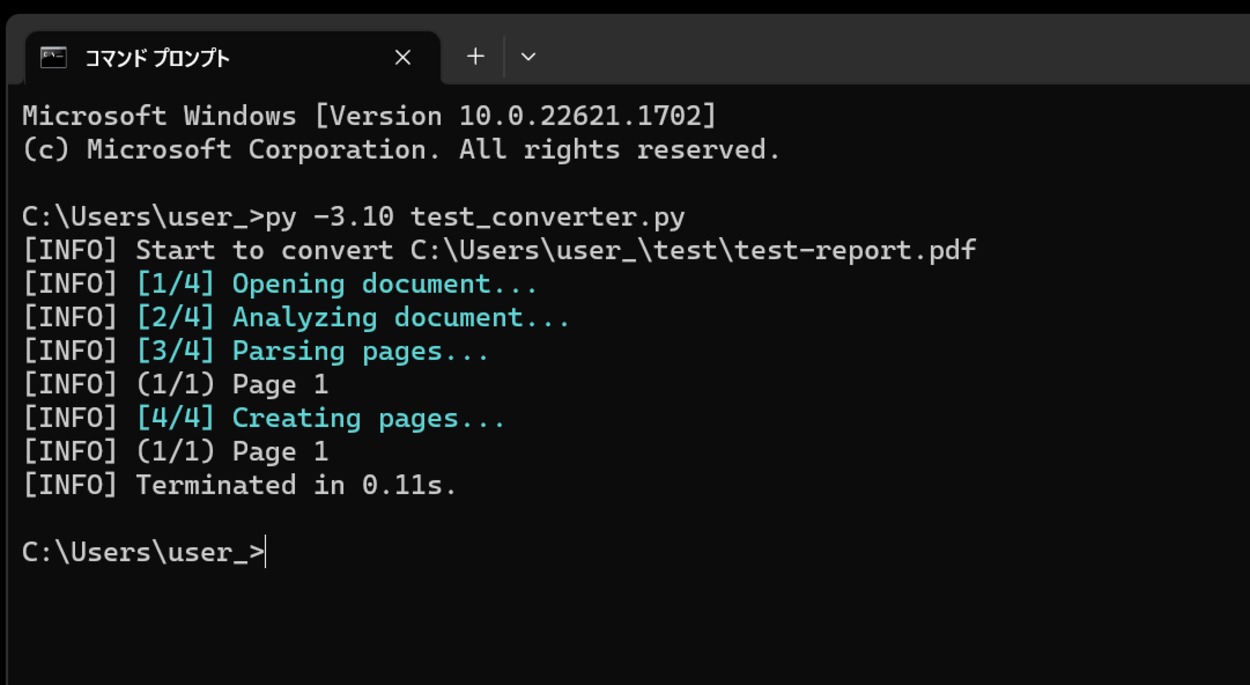
[INFO] Start to convert C:\Users\user_\test\test-report.pdf [INFO] [1/4] Opening document... [INFO] [2/4] Analyzing document... [INFO] [3/4] Parsing pages... [INFO] (1/1) Page 1 [INFO] [4/4] Creating pages... [INFO] (1/1) Page 1 [INFO] Terminated in 0.11s.
実行してみるとコマンドプロンプト上に上記のメッセージが出力されます。「Terminated in ****.」と表示されれば変換は完了となります。
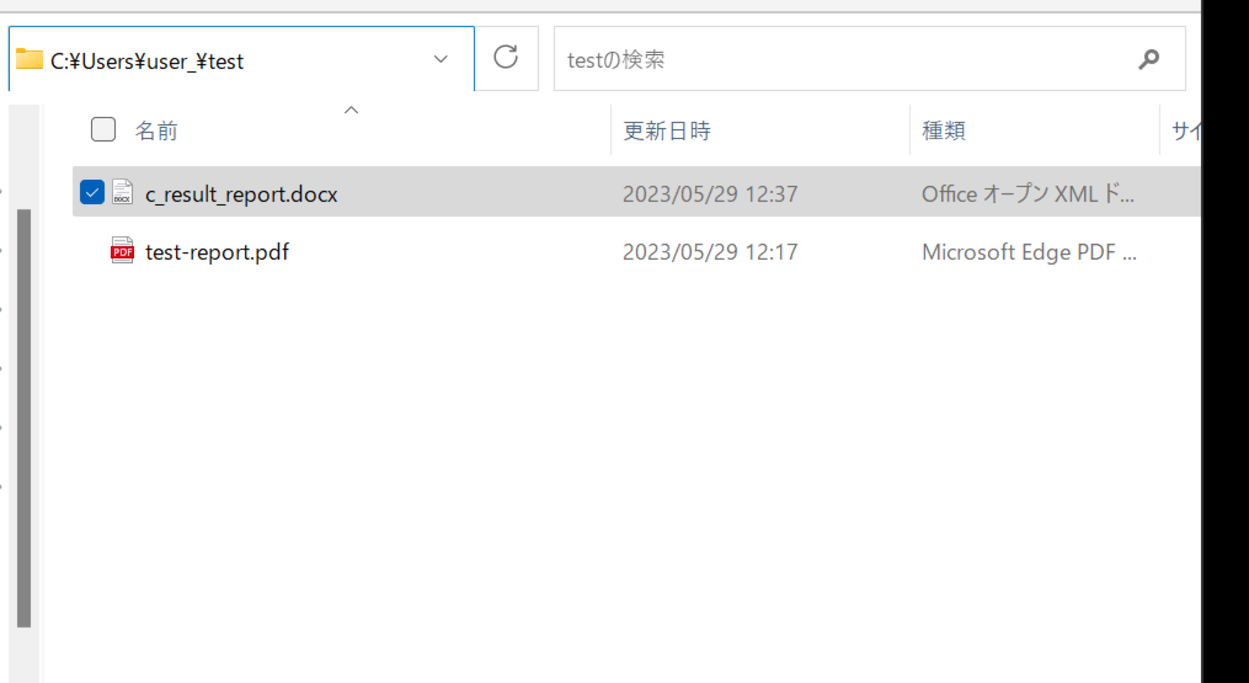
完了後docx_fileで指定したパスを確認すると「c_result_report.docx」というDOCXが生成されていることを確認できました。
確認後、DOCXを開いてみるとPDF内の情報が抽出され解析後変換されていることが確認できました。ただし、今回の場合ではレイアウトがずれているなどの問題が発生していました。最後に気付いたこととしては日本語であっても文字化けせずに変換が行えたことです。

コメント