
PythonでWebサイトから表(テーブル)データを抽出し別の形式に変換してみます。
今回は、requests-htmlを用います。このライブラリ・モジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
参考URL:https://www.youtube.com/watch?v=YjpGdFwIAxg
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■Webサイトから表(テーブル)データを抽出し別の形式に変換する
Webサイトから表(テーブル)データを抽出し別の形式に変換してみますが、今回はこちらのWebサイト(「Premier League Table & Standings – Sky Sports Football」https://www.skysports.com/premier-league-table)をスクレイピングし、表(テーブル)データを抽出します。
■コード
from requests_html import HTMLSession
session = HTMLSession()
url = 'https://www.skysports.com/premier-league-table'
request = session.get(url)
table = request.html.find('table')[0]
print(table)「from import」でrequests_htmlモジュールのHTMLSessionを呼び出します。その後、sessionという変数を定義し、その中でHTMLSession()を用いてGETリクエストを初期化します。初期化後、urlという変数を定義し、その中に今回スクレイピングを行うWebサイトのURLを格納します。
格納後、requestという変数を定義し、GETリクエストを初期化したsession変数に対してget()を用いてGETリクエストを行います。括弧内には引数,パラメータとして、WebサイトのURLを格納したurl変数を渡します。
これでWebサイトの情報がr変数に格納されますので、新しくtable変数を定義し、その中でhtml.find()を用いて、Webサイトの情報が格納されたr変数内のHTMLでtableの部分(表(テーブル)データ)を抽出します。この際に「[0]」とすると、tableの最初の部分を抽出することができます。
■実行・検証
ここで、「tabledata_s.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。

実際してみると、指定したWebサイト内のHTMLからtableの部分(表(テーブル)データ)の最初が出力されることが確認できました。
確認後、HTMLからtableの部分(表(テーブル)データ)から情報(数値等)を抽出してみます。
■コード
from requests_html import HTMLSession
session = HTMLSession()
url = 'https://www.skysports.com/premier-league-table'
request = session.get(url)
table = request.html.find('table')[0]
for row in table.find('tr'):
print(row.text)情報(数値等)を抽出するために、今回はfor文を用いてtableの部分(表(テーブル)データ)で情報(数値等)が含まれている「tr」を取得し、取得したものを1つずつrowに格納。格納後、rowのtestを全てprint()で出力します。
■実行・検証
ここで「tabledata_s.py」を変更し、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
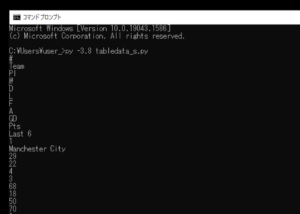
実行してみると、tableの部分(表(テーブル)データ)から情報(数値等)を抽出されprint()で出力させることができました。
■コード
from requests_html import HTMLSession
import json
session = HTMLSession()
url = 'https://www.skysports.com/premier-league-table'
request = session.get(url)
tables = request.html.find('table')[0]
tabledata = [[a.text for a in row.find('td')[:-1]] for row in tables.find('tr')][1:]
tableheader = [[a.text for a in row.find('th')[:-1]] for row in tables.find('tr')][0]
table_1 = [dict(zip(tableheader,t)) for t in tabledata]
with open('table_test.json','w') as f:
json.dump(table_1,f)出力後、tableの部分(表(テーブル)データ)の情報(数値等)を整形し、tableのヘッダー部分の情報も抽出し、こちらも整形を行い、一番最初の表(テーブル)データとヘッダー部分を辞書(dict型オブジェクト)として結合させます。
結合後、with構文を用いて表(テーブル)データをJSON形式にエンコードし、エンコードしたものを「table_test.json」というファイルに書き込みます。エンコードの際はPythonの標準ライブラリであるjsonモジュールをimportして用います。
■実行・検証
最後に「tabledata_s.py」を変更し、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
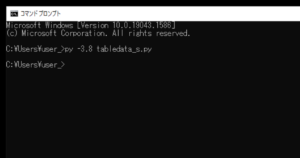
実行してみると、今回のスクリプトには、JSON形式のファイルを生成した場合に、生成完了といった文字列を出力させる指示は書いていないので、何も出力されません。何も出力されませんが、作業ディレクトリ(カレントディレクトリ)を確認すると、「table_test.json」が生成されていることが確認できました。
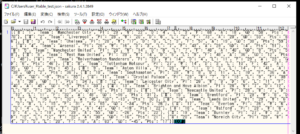
確認後、JSON形式のファイルの中身を確認すると、今回指定したWebサイトの表(テーブル)データが抽出され、ファイルに書き込まれていることが確認できました。

コメント