
Pythonの非同期処理を利用して複数のWebサイトからデータを取得してみます。
■今回の環境(Python)
今回のPythonはバージョン3.10.8を用いる。(https://replit.com/を用いる)
■非同期処理を利用して複数のWebサイトからデータを取得する
では、非同期処理を利用して複数のWebサイトからデータを取得するスクリプトコードを書いていきます。
■コード
import asyncio
import aiohttp
# 非同期関数
async def fetch_data(session, url):
async with session.get(url) as response:
data = await response.text()
print(f"データ取得完了: {url}")
return data
# メイン関数
async def main():
# セッションの作成
async with aiohttp.ClientSession() as session:
# 非同期処理の並行実行
urls = [
"https://www.baidu.com",
"https://google.com",
"https://yahoo.co.jp",
]
tasks = [fetch_data(session, url) for url in urls]
results = await asyncio.gather(*tasks)
print("取得したデータ:")
for url, data in zip(urls, results):
print(f"{url}: {data[:50]}...")
# イベントループの作成と実行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
loop.close()まずimportでasyncioによりasyncioモジュールとaiohttpによりasyncioモジュールをインポートします。次にfetch_data()関数を定義します。この関数は指定されたURLからデータを非同期に取得するための非同期関数です。引数としてsession(aiohttp.ClientSessionオブジェクト)とurlが渡されます。「async with session.get(url) as response」は、指定されたURLに対して非同期でHTTP GETリクエストを行います。「session.get()」は非同期に実行され、responseオブジェクトが取得されます。async withステートメントを使用することで、リクエストの送信とレスポンスの受信が自動的に行われます。 「await response.text()」は、レスポンスオブジェクトから非同期にテキストデータを取得します。「response.text()」は非同期に実行され、レスポンスのテキストデータが取得されます。awaitキーワードにより、非同期処理の完了を待ちます。 テキストデータが取得された後、print(f”データ取得完了: {url}”)が実行され、取得が完了した旨が表示されます。 最後に、取得したデータがreturnステートメントを通じて関数から返されます。
次にmain()関数を定義します。この関数は非同期処理のエントリーポイントとなります。この関数内で非同期処理を実行します。「async with aiohttp.ClientSession() as session:」はaiohttp.ClientSession()を使用して非同期HTTPセッションを作成します。async with構文を使用することで、セッションが自動的に開始され、終了時にクリーンアップされます。セッションは非同期処理の実行に使用されます。「urls = [“https://www.baidu.com”, “https://google.com”, “https://yahoo.co.jp”]:」は、取得したいデータのURLをリストとして定義しています。今回は、3つのURLが指定しています。「tasks = [fetch_data(session, url) for url in urls]」は、fetch_data()関数を呼び出して非同期タスクのリストを作成しています。各URLごとにfetch_data()関数が呼び出され、非同期タスクが作成されます。引数として、先ほど作成したセッションと各URLが渡されます。「results = await asyncio.gather(*tasks)」はasyncio.gather()関数を使用して非同期タスクの並行実行と結果の取得を行います。「*tasks」を使用してタスクのリストを展開し、gather()関数に渡します。gather()関数は、タスクの実行を同時に行い、全てのタスクが完了するまで待機します。完了した結果はresultsに格納されます。「print(“取得したデータ:”)」は、取得したデータの表示を開始することを示すメッセージを表示します。「for url, data in zip(urls, results):」はzip()関数を使用して、元のURLと取得したデータの結果をペアにして反復処理を行います。各URLとその対応するデータをurlとdataに取り出します。「print(f”{url}: {data[:50]}…”)」は取得したデータの一部を表示します。ここでは、URLとそのデータの最初の50文字までを表示しています。なお、f文字列(f-strings)を用いてPythonの文字列内で変数や式を埋め込みます。
その後、イベントループを作成し、非同期処理を実行します。run_until_complete()メソッドは、非同期処理が完了するまでイベントループを制御し、close()メソッドは処理の最後にイベントループをクローズします。これにより、非同期処理の実行が適切に管理され、リソースの解放も行われる。
■実行・検証
このスクリプトコードをrepl.itのエディタ上に記述し「main.py」という名前で保存。保存後、コンソールで実行してみます。
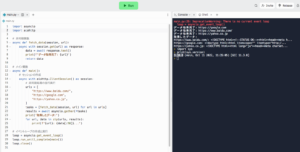
実行してみると、非同期処理を利用して複数のWebサイトからデータを取得し、取得したデータの一部を表示させることができました。また、非同期処理によって、複数のタスクを効率的に並行実行させることもできた。なお、「main.py:28: DeprecationWarning: There is no current event loop loop = asyncio.get_event_loop()」という警告が出力されたがあくまで警告でありエラーではないので今回は無視しています。

コメント