
PandasにおけるDataFrameの列から一意の値を取得してみます。
なお、一意とは「重複しない」という意味です。つまり”ユニーク(他に類を見ない)”であるとも言えます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■DataFrameを作成する
DataFrameの列から一意の値を取得する前に、DataFrameを作成します。
■コード
import pandas as pd
data = {
'名前':['田村','吉岡','佐々木','小島','上村'],
'出身':['北海道','愛知','宮城','東京','大阪'],
'年齢':[28,37,41,25,32]
}
df = pd.DataFrame(data)
print(df)インポートでPandasモジュールを呼び出します。dataという変数を作成し、その中に「名前」、「出身」、「年齢」の3つの列を格納します。
格納後、dfという変数を作成し、pd.DataFrame()と記述し、DataFrameを作成。作成後、dfという変数に格納します。
■実行
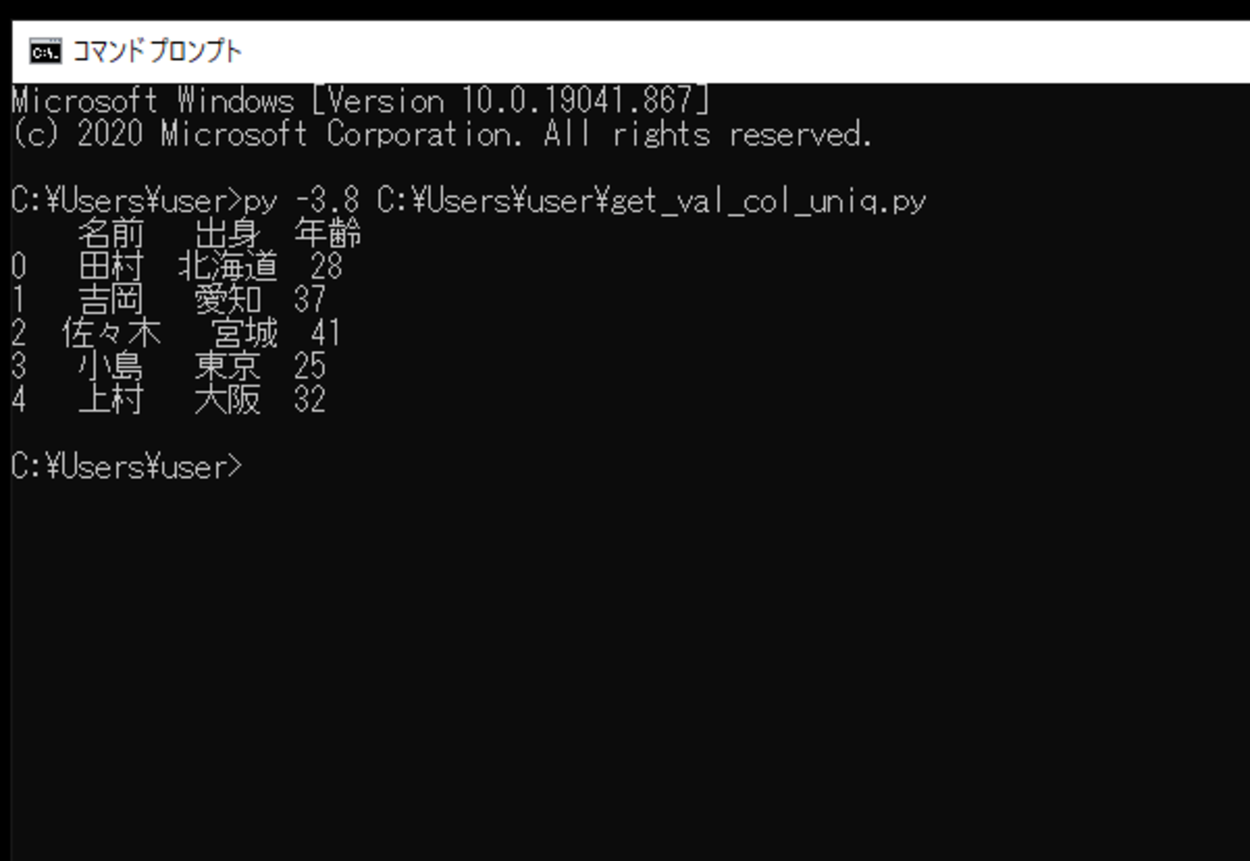
このスクリプトを実行すると、作成したDataFrameが出力されます。
■DataFrameの列から一意の値を取得する
DataFrameの用意ができましたので、DataFrameの列から一意の値を取得するスクリプトを書いていきます。
■コード
import pandas as pd
data = {
'名前':['田村','吉岡','佐々木','小島','上村'],
'出身':['北海道','愛知','宮城','東京','大阪'],
'年齢':[28,37,41,25,32]
}
df = pd.DataFrame(data)
print(df)
print(df.出身.unique())DataFrameの列から一意の値を取得する場合は、、dfという変数を作成し、pd.DataFrame()と記述し、DataFrameを作成。その後にunique()を使用し、DataFrameの列を指定します。これで列から一意の値を取得することができます。
指定後、print関数で一意の値を出力してみます。
■実行
このスクリプトを「get_val_col_uniq_2.py」という名前で保存し、コマンドプロンプトから実行してみます。
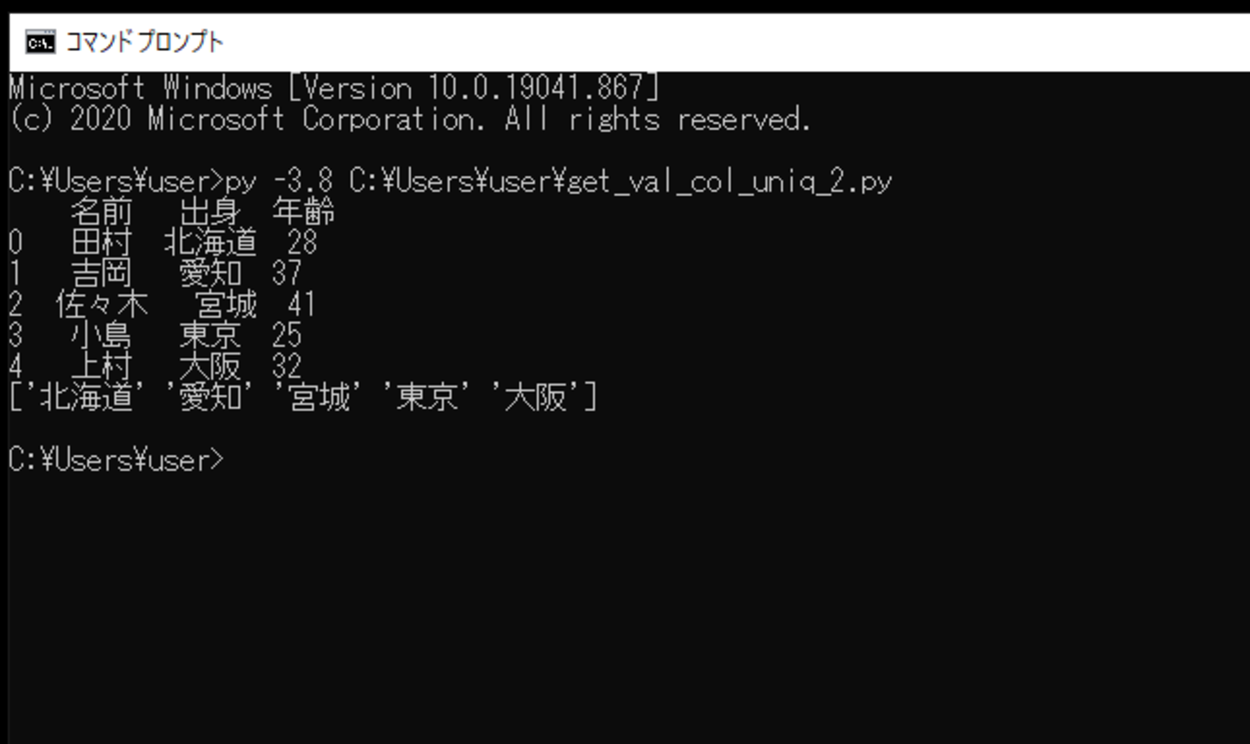
実行してみると、作成したDataFrameで、今回指定した列の値で一意のものを取得し出力できました。
■重複している場合
では、次にDataFrameの列の値が重複している場合はどうなるのかやってみます。
■コード
import pandas as pd
data = {
'名前':['田村','吉岡','佐々木','小島','上村'],
'出身':['北海道','北海道','北海道','北海道','北海道'],
'年齢':[28,37,41,25,32]
}
df = pd.DataFrame(data)
print(df)
print(df.出身.unique())今回は「出身」という列の値が全て重複しています。
■実行
このスクリプトを「df_headers_3.py」という名前で保存し、コマンドプロンプトから実行してみます。
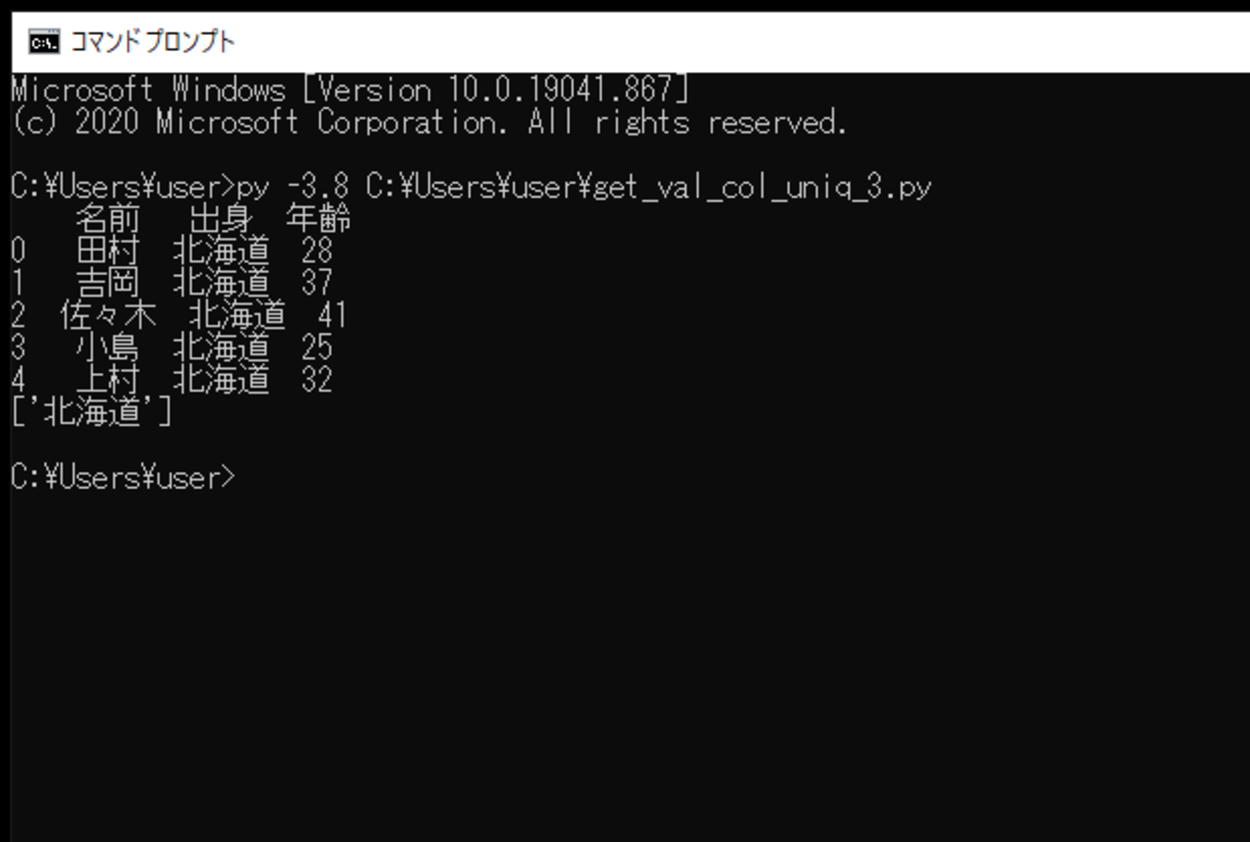
実行してみると、DataFrameの「出身」という列の値は全て重複していますので、重複せず出力されるものは、「北海道」のみになります。
■列内の一意の値の数を取得する
では、次にDataFrameの列内の一意の値の数を取得してみます。
■コード
import pandas as pd
data = {
'名前':['田村','吉岡','佐々木','小島','上村'],
'出身':['北海道','愛知','宮城','東京','大阪'],
'年齢':[28,28,28,25,32]
}
df = pd.DataFrame(data)
print(df)
print(df.年齢.nunique(dropna = True))DataFrameの列内の一意の値の数を取得する場合は、nunique()を使用することで一意の値の個数を取得できます。さらに括弧内で「dropna = True」と記述すると、NaN値を除外することができます。
■実行
このスクリプトを「get_val_col_uniq_4.py」という名前で保存し、コマンドプロンプトから実行してみます。

実行してみると、DataFrameの列内の一意の値の数を取得し出力できました。

コメント