
Pythonでtextblobを用いて名詞句の抽出を行ってみます。
今回はtextblobを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python
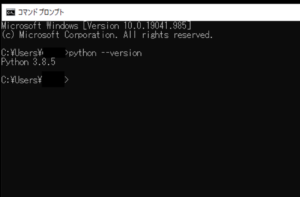
今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■textblobを用いて名詞句の抽出する
では、早速textblobを用いて名詞句の抽出するスクリプトを書いていきます。
■コード
from textblob import TextBlob
wiki = TextBlob("Make Python output a string")
print(wiki.noun_phrases)「from import」でtextblobのTextBlobを呼び出します。その後、wikiという変数を定義し、その中でTextBlob()を用います。括弧内には引数,パラメータとして、名詞句の抽出するための文字列を渡します。今回は英語の文章を渡しています。
その後、wikiに対してnoun_phrasesを用いて名詞句の抽出を行います。抽出されたものが返されますので、print()で出力します。
■実行・検証
このスクリプトを「py_string_test.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
**********************************************************************
Resource [93mbrown[0m not found.
Please use the NLTK Downloader to obtain the resource:
[31m>>> import nltk
>>> nltk.download('brown')
[0m
For more information see: https://www.nltk.org/data.html
Attempted to load [93mcorpora/brown[0m
Searched in:
- 'C:\\Users\\user_/nltk_data'
- 'C:\\Program Files\\Python38\\nltk_data'
- 'C:\\Program Files\\Python38\\share\\nltk_data'
- 'C:\\Program Files\\Python38\\lib\\nltk_data'
- 'C:\\Users\\user_\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
Traceback (most recent call last):
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\corpus\util.py", line 84, in __load
root = nltk.data.find(f"{self.subdir}/{zip_name}")
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\data.py", line 583, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource [93mbrown[0m not found.
Please use the NLTK Downloader to obtain the resource:
[31m>>> import nltk
>>> nltk.download('brown')
[0m
For more information see: https://www.nltk.org/data.html
Attempted to load [93mcorpora/brown.zip/brown/[0m
Searched in:
- 'C:\\Users\\user_/nltk_data'
- 'C:\\Program Files\\Python38\\nltk_data'
- 'C:\\Program Files\\Python38\\share\\nltk_data'
- 'C:\\Program Files\\Python38\\lib\\nltk_data'
- 'C:\\Users\\user_\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\decorators.py", line 35, in decorated
return func(*args, **kwargs)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\en\np_extractors.py", line 109, in train
train_data = nltk.corpus.brown.tagged_sents(categories='news')
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\corpus\util.py", line 121, in __getattr__
self.__load()
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\corpus\util.py", line 86, in __load
raise e
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\corpus\util.py", line 81, in __load
root = nltk.data.find(f"{self.subdir}/{self.__name}")
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\nltk\data.py", line 583, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource [93mbrown[0m not found.
Please use the NLTK Downloader to obtain the resource:
[31m>>> import nltk
>>> nltk.download('brown')
[0m
For more information see: https://www.nltk.org/data.html
Attempted to load [93mcorpora/brown[0m
Searched in:
- 'C:\\Users\\user_/nltk_data'
- 'C:\\Program Files\\Python38\\nltk_data'
- 'C:\\Program Files\\Python38\\share\\nltk_data'
- 'C:\\Program Files\\Python38\\lib\\nltk_data'
- 'C:\\Users\\user_\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "py_string_test.py", line 5, in
print(wiki.noun_phrases)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\decorators.py", line 24, in __get__
value = obj.__dict__[self.func.__name__] = self.func(obj)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\blob.py", line 483, in noun_phrases
for phrase in self.np_extractor.extract(self.raw)
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\en\np_extractors.py", line 138, in extract
self.train()
File "C:\Users\user_\AppData\Roaming\Python\Python38\site-packages\textblob\decorators.py", line 38, in decorated
raise MissingCorpusError()
textblob.exceptions.MissingCorpusError:
Looks like you are missing some required data for this feature.
To download the necessary data, simply run
python -m textblob.download_corpora
or use the NLTK downloader to download the missing data: http://nltk.org/data.html
If this doesn't fix the problem, file an issue at https://github.com/sloria/TextBlob/issues.実行してみると、上記のエラーが出力された。エラー内容を確認すると、NLTK corporaをダウンロードする必要がある。
>py -3.8 -m textblob.download_corpora
ダウンロードの必要があるため、上記のコマンドを入力し、Enterキーを押す。本来だと上記のコマンドは「python -m textblob.download_corpora」だが、今回Pythonのバージョンを指定している。
[nltk_data] Downloading package brown to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Unzipping corpora\brown.zip. [nltk_data] Downloading package punkt to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Unzipping tokenizers\punkt.zip. [nltk_data] Downloading package wordnet to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Downloading package averaged_perceptron_tagger to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip. [nltk_data] Downloading package conll2000 to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Unzipping corpora\conll2000.zip. [nltk_data] Downloading package movie_reviews to [nltk_data] C:\Users\user_\AppData\Roaming\nltk_data... [nltk_data] Unzipping corpora\movie_reviews.zip. Finished.
Enterキーを押すとダウンロードが開始され、「Finished.」と出力されれば、ダウンロードは完了となる。
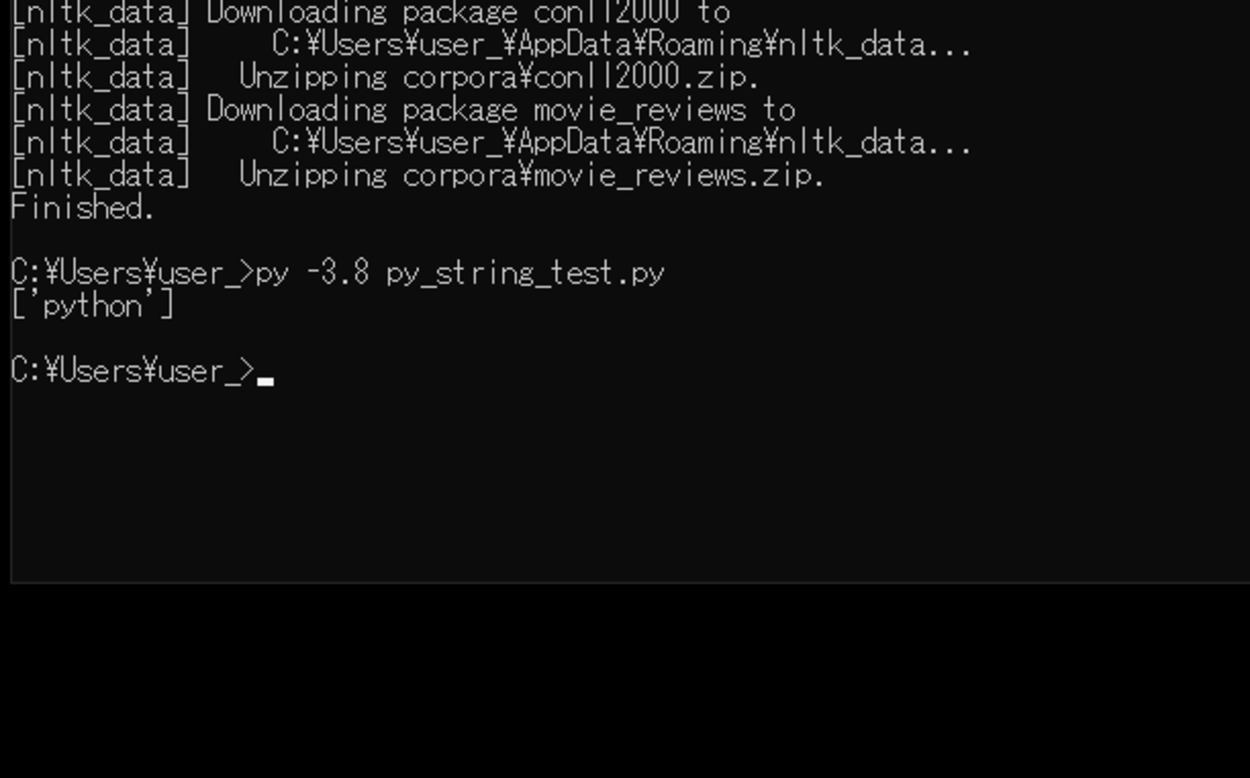
完了後、再度スクリプトを実行してみる。実行してみると、textblobを用いて名詞句を抽出し出力させることができた。

コメント