
正規表現を使用しPythonでテキスト内の単語、またはフレーズが発生する回数を見つけてみます。
正規表現を使用するには、reモジュールを使います。reモジュールはPythonの標準ライブラリとなっていますので、事前にインストールする必要はありません。
■Python
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■正規表現を使用しPythonでテキスト内の単語が発生する回数を見つける
では、早速正規表現を使用しPythonでテキスト内の単語が発生する回数を見つけてみます。
■コード
import re
text = "I started playing golf two months ago. But he had a set of golf equipment for years. He had bought dozens of golf shoes and balls, but he didn't play golf until two months ago."
word = [r'golf']
for w in word:
match = re.findall(w, text)
print(match)
length = len(match)
print(length)インポートで、reモジュールを呼び出して、textの「golf」という単語の出現回数を確認するために、wordという名前の変数を作成し、[r’golf’]を記述します。なお、textの文章は、青空文庫から著作権切れの作品を使って翻訳したものになります。
そして、textの文章で、word変数と一致する全てのものを照合します。照合後、出現回数を数えるために、len()関数を使用します。使用したものをprint関数で出力します。
■実行
今回書いたスクリプトを「word_Identify.py」という名前で保存し、コマンドプロンプトから実行してみます。
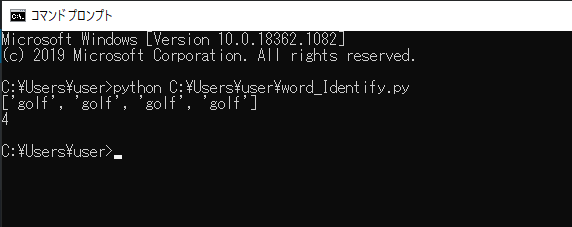
実行してみると、text内の「golf」という単語が4回出力され、text内での出現回数は4回であることを確認することができました。
■フレーズが発生する回数を見つける
次にテキスト内のフレーズが発生する回数を見つけてみます。
■コード
import re
text = "I started playing golf two months ago. But he had a set of golf equipment for years. He had bought dozens of golf shoes and balls, but he didn't play golf until two months ago."
word = [r'I started playing golf']
for w in word:
match = re.findall(w, text)
print(match)
length = len(match)
print(length)スクリプトは先程のテキスト内の単語が発生する回数を見つける時と変わりありません。
見つけたいフレーズをword変数に記述するだけです。今回は「I started playing golf」というフレーズの出現回数を調べてみます。
■実行

「word_Identify.py」のスクリプトを変更し実行してみると、テキスト内の「I started playing golf」というフレーズの出現回数は1回であることが確認できました。

コメント