
Hugging Face内の言語モデルを使って推論(inference)を実行してみます。
実行する際は、事前にアカウント登録と、Hugging FaceのAPIトークン(アクセストークン)を取得しておきます。
■今回の環境(Python)
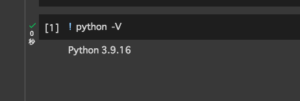
今回のPythonは、バージョン3.9.16を用いる。(なお、Google Colaboratory(Google Colab)を使用。)
API リクエストによる言語モデルの推論(inference)の実行
では、API リクエストによる言語モデルの推論(inference)の実行を行うために、コードを書いていきます。
■コード
import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": f"Bearer アクセストークン"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "What is the capital of Japan?",})
print(output)Pythonのrequestsモジュールを使用し、Hugging FaceのAPIを介してGPT-2モデル(https://api-inference.huggingface.co/models/gpt2)に問い合わせを行います。
最初に、APIのエンドポイントをAPI_URL変数に設定しています。このURLは、Hugging FaceのモデルAPIのエンドポイントを指定します。
次に、ヘッダー情報をheaders変数に設定しています。このヘッダーには、アクセストークンを含める必要があります。アクセストークンは、Hugging FaceのAPIにアクセスするための認証情報です。このコードでは、Bearerという文字列の後にアクセストークンを記述する必要があります。
query関数は、与えられたペイロード(APIへのリクエストデータ)を使用して、APIにPOSTリクエストを送信します。リクエストの際には、事前に設定したAPIのエンドポイントとヘッダー情報を使用します。そして、APIからのレスポンスをJSON形式で取得し、その結果を返します。
最後に、query関数を使用して具体的な質問(今回は「What is the capital of Japan?」)をAPIに送信し、その結果をoutput変数に格納しています。
output変数には、APIからの応答が含まれています。この応答はJSON形式であり、print()によって出力されます。
■実行・検証
このコードセルを保存し、Google Colaboratory上で、セルを実行してみます。
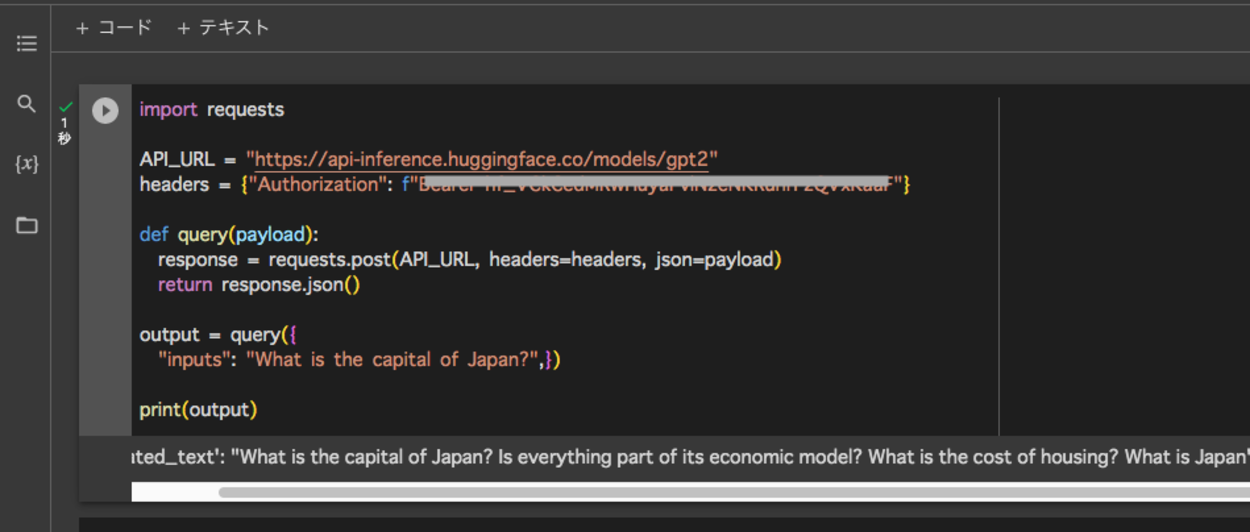
実行してみると、Hugging FaceのAPIを介してGPT-2モデルの推論(inference)を実行し、応答を出力させることができました。

コメント