
PandasにおけるDataFrameの行のランク付け(ランキング)を行ってみます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■DataFrameを作成する
DataFrameの行のランク付けする前に、DataFrameを作成します。
■コード
import pandas as pd
data = {
'名前':['田中','佐々木','小島','有田','長野'],
'評価':['8.2','5.5','2.4','7.8','9.8']
}
df = pd.DataFrame(data)
print(df)インポートでPandasモジュールを呼び出します。dataという変数を作成し、その中に「名前」、「評価(ランキング)」の2つの列を格納します。
格納後、dfという変数を作成し、pd.DataFrame()と記述し、DataFrameを作成。作成後、dfという変数に格納します。
■実行
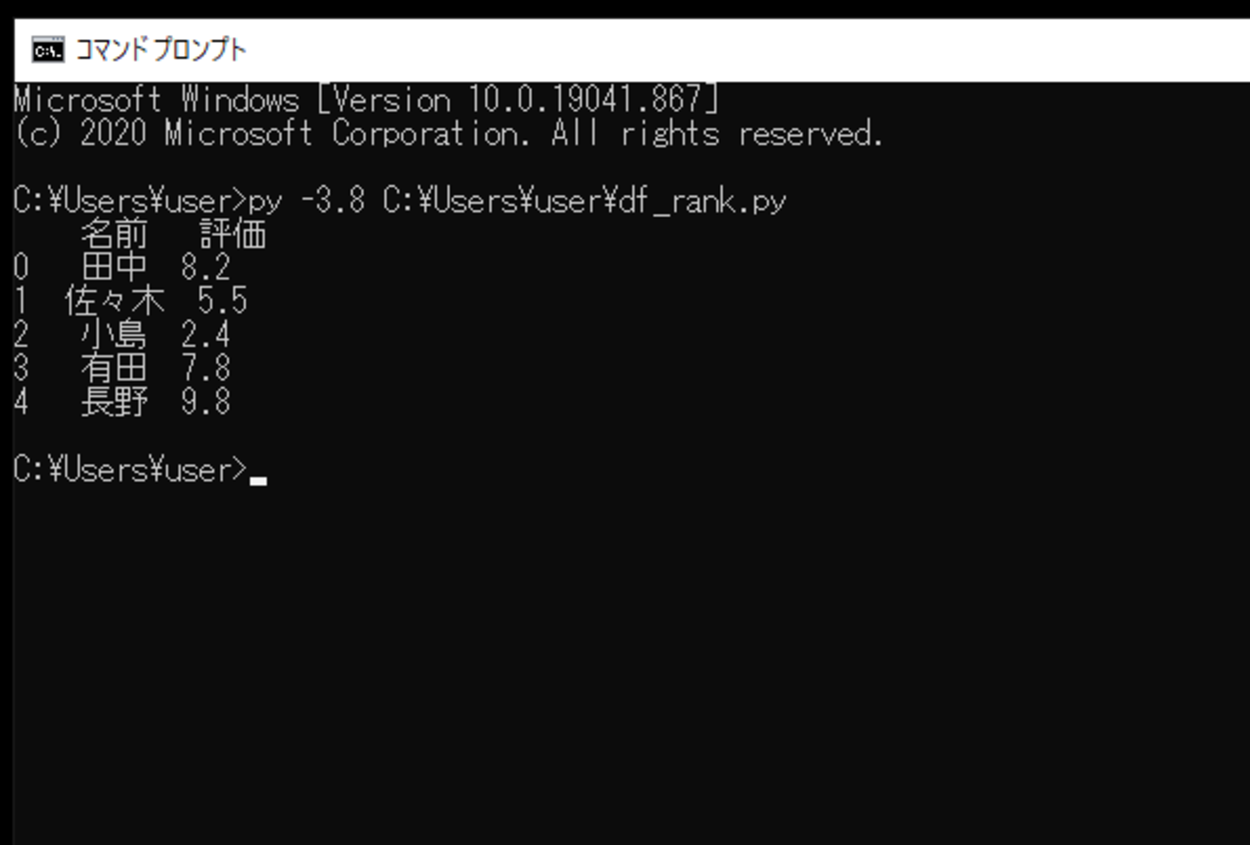
このスクリプトを実行すると、作成したDataFrameが出力されます。
■DataFrameの行のランク付けをする
DataFrameの用意ができましたので、DataFrameの行のランク付けをするスクリプトを書いていきます。
■コード
import pandas as pd
data = {
'名前':['田中','佐々木','小島','有田','長野'],
'評価':['8.2','5.5','2.4','7.8','9.8']
}
df = pd.DataFrame(data)
df['ランキング'] = df['評価'].rank(ascending= 1)
df = df.set_index('ランキング')
print(df)DataFrameの行のランク付けをする場合は、dfという変数を作成し、pd.DataFrame()と記述し、DataFrameを作成。
その後に、DataFrame内に「ランキング」という列を作り、その中にDataFrame内の「評価」の列を指定し、「評価」内のデータを、rank(ascending= 1)と記述し、昇順でランク付けし格納します。
格納後、DataFrame内にset_index()と記述し、「ランキング」という列にインデックスを割り当て格納します。
最後にDataFrame内の情報をprint関数で出力します。
■実行
このスクリプトを「df_rank_2.py」という名前で保存し、コマンドプロンプトから実行してみます。
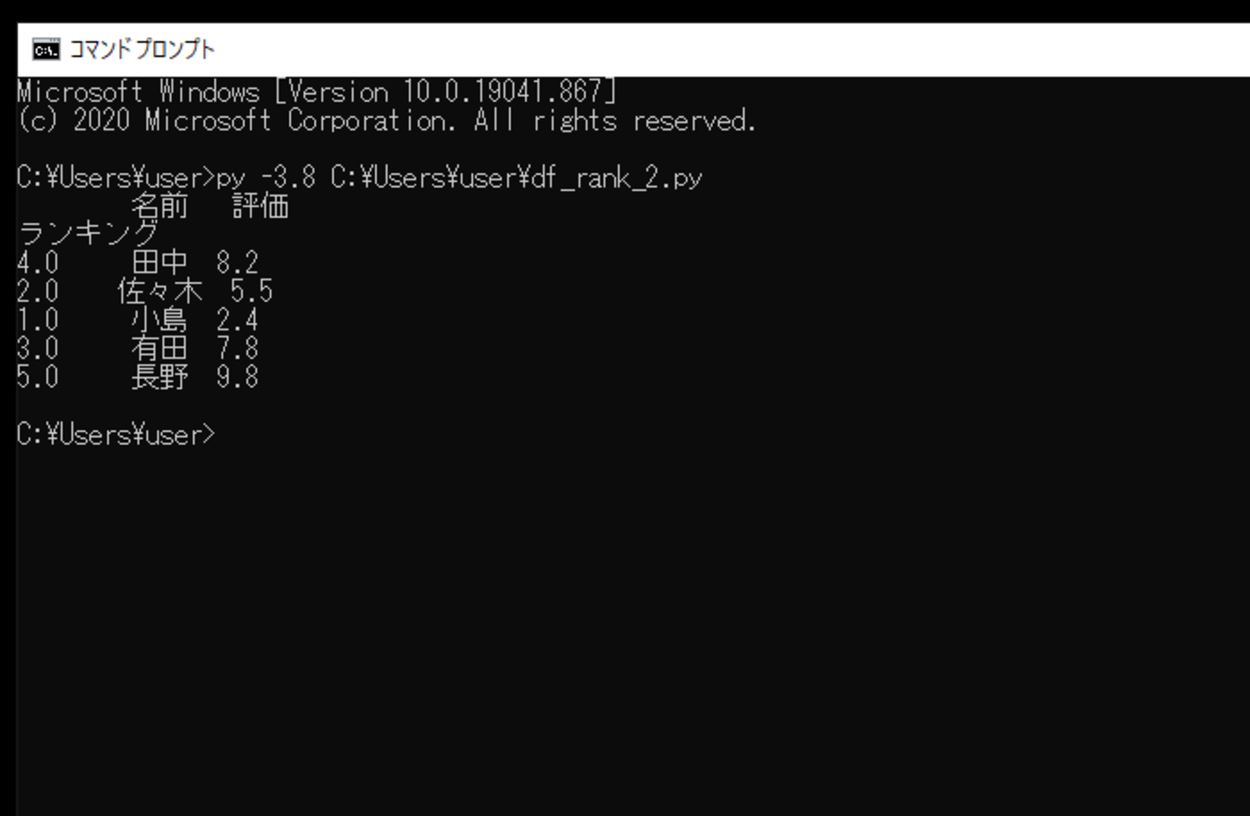
実行してみると、今回作成したDataFrame内に「ランキング」という列が追加され、「評価」のデータを元にランク付けて出力できました。
■ランク付けをソートする
次にDataFrameの行のランク付けを行いましたが、ランクに応じてDataFrameの行をソートしてみます。
■コード
import pandas as pd
data = {
'名前':['田中','佐々木','小島','有田','長野'],
'評価':['8.2','5.5','2.4','7.8','9.8']
}
df = pd.DataFrame(data)
df['ランキング'] = df['評価'].rank(ascending= 1)
df = df.set_index('ランキング')
df = df.sort_index()
print(df)DataFrameの行をソートする場合は、作成したDataFrameに対して、sort_index()を使用し、インデックスとして割り当てた「ランキング」の列を基準してソートすることができます。
ソート後、dfという変数に格納し、print関数でdf変数の情報を出力します。
■実行
このスクリプトを「df_rank_3.py」という名前で保存し、コマンドプロンプトから実行してみます。
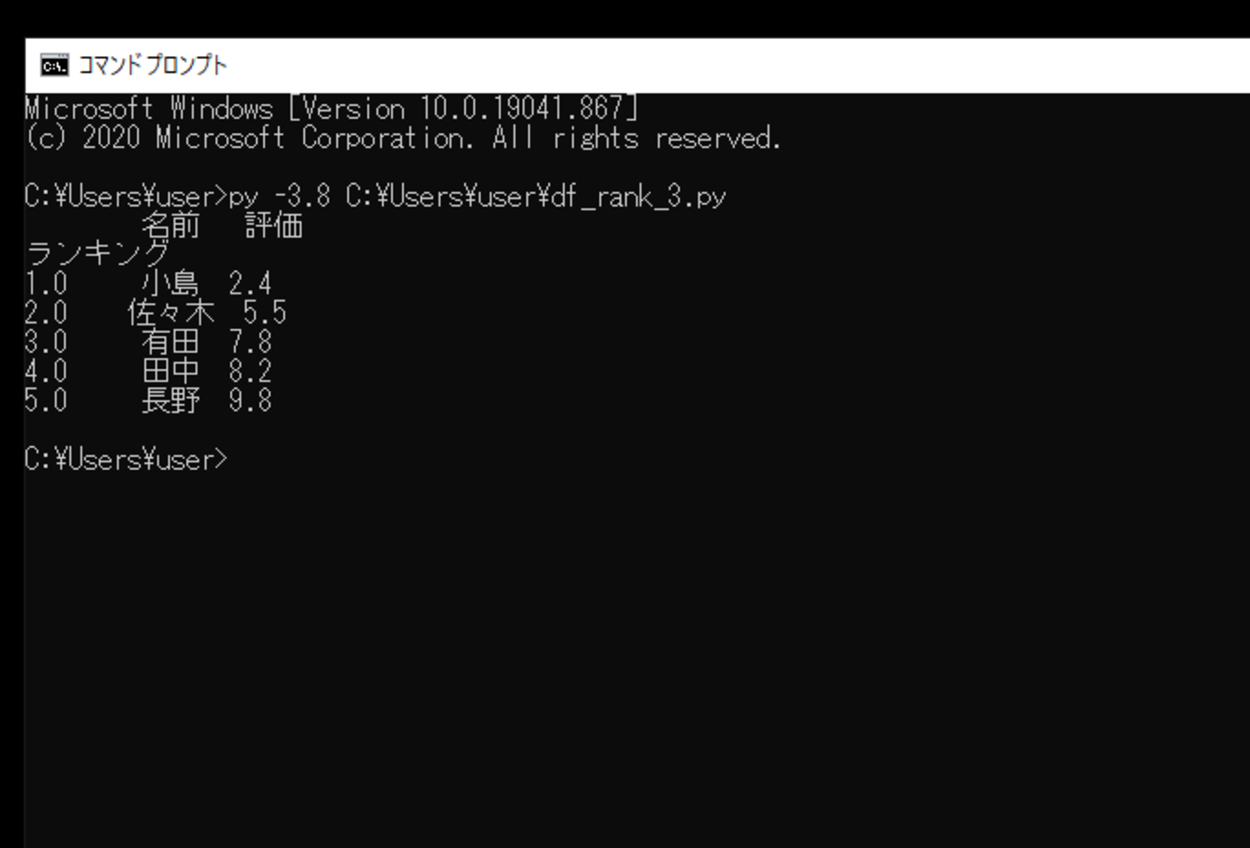
実行してみると、インデックスとして割り当てた「ランキング(ランク)」順にDataFrame内のデータがソートされて出力することができました。

コメント