
Pythonでrequestsを用いてWebスクレイピングを行い、スクレイピングしたデータをsqlite3データベースに保存してみます。
なお、今回はrequests,datetime,sqlite3を用います。この3つのライブラリ・モジュールはPythonの標準ライブラリで事前にインストールする必要はありませんが、BeautifulSoupはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■requestsを用いてWebスクレイピングを行い、スクレイピングしたデータをsqlite3データベースに保存する
では、早速requestsを用いてWebスクレイピングを行い、スクレイピングしたデータをsqlite3データベースに保存するスクリプトを書いていきます。
■コード
import requests
from bs4 import BeautifulSoup
import datetime
import sqlite3
conn = sqlite3.connect('amazon_product1.db')
c = conn.cursor()
def get_amazon_data(url):
headers = {'User-agent': '*********'}
r = requests.get(url,headers=headers)
soup =BeautifulSoup(r.content,'html.parser')
current_data = datetime.datetime.now()
title = soup.find('span', {'id': 'productTitle'}).text.strip()
price = soup.find('span', {'class': 'a-price-whole'}).text.strip()
c.execute('''CREATE TABLE IF NOT EXISTS detail(current_data TEXT, title TEXT, price TEXT)''')
c.execute('''INSERT INTO detail VALUES(?,?,?)''',(current_data,title, price))
return
get_amazon_data("https://www.amazon.co.jp/******/dp/******/")
conn.commit()
print('データを取得しDBへの保存が完了しました')
c.execute('''SELECT * FROM detail''')
results = c.fetchall()
print(results)
conn.close()なお、今回Pythonの標準ライブラリ(HTTPライブラリ)であるrequestsモジュールを用いて情報を取得するWebサイトは、「アマゾン: Amazon(https://www.amazon.co.jp/)」になります。requestsモジュールで、Amazonの商品詳細ページから情報を取得し、BeautifulSoupモジュールを用いて取得したページ内を解析し「商品のタイトル(名前)」と「価格」の情報を抽出。抽出後、「amazon_product1.db」というsqlite3データベースに「商品のタイトル(名前)」と「価格」の情報を保存するという仕組みです。
なお、スクリプトの処理の最後にデータベース内に保存された情報を出力させます。
■実行・検証
このスクリプトを「amazon_ws.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
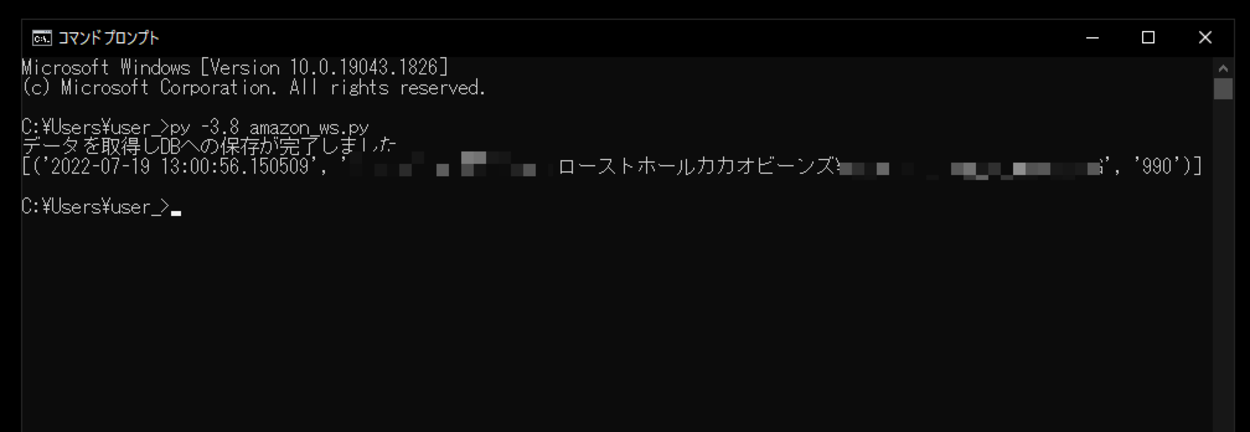
実行してみると、「データを取得しDBへの保存が完了しました」という文字列とsqlite3データベース内の情報が出力されました。
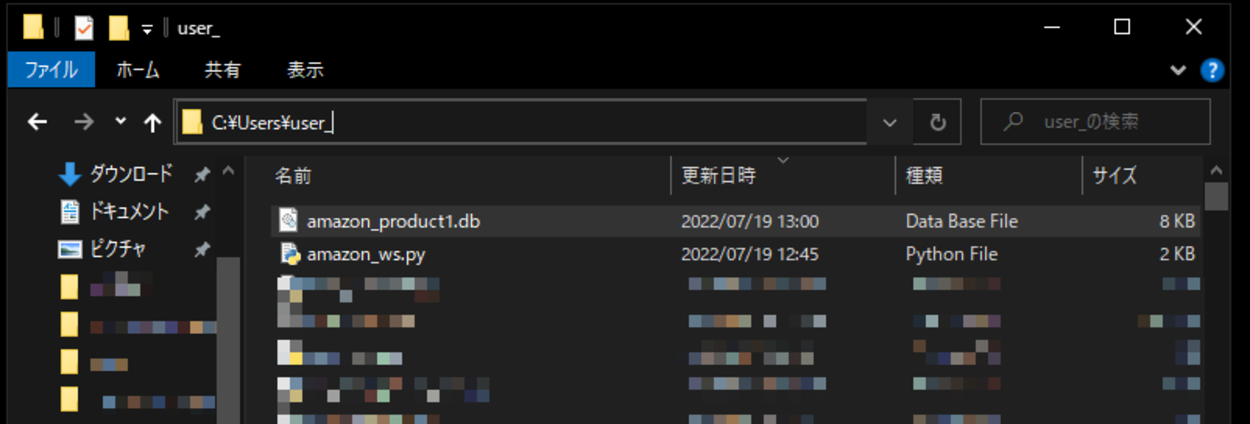
出力後、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)内を確認すると、「amazon_product1.db」というデータベースが作成されていることが確認できました。
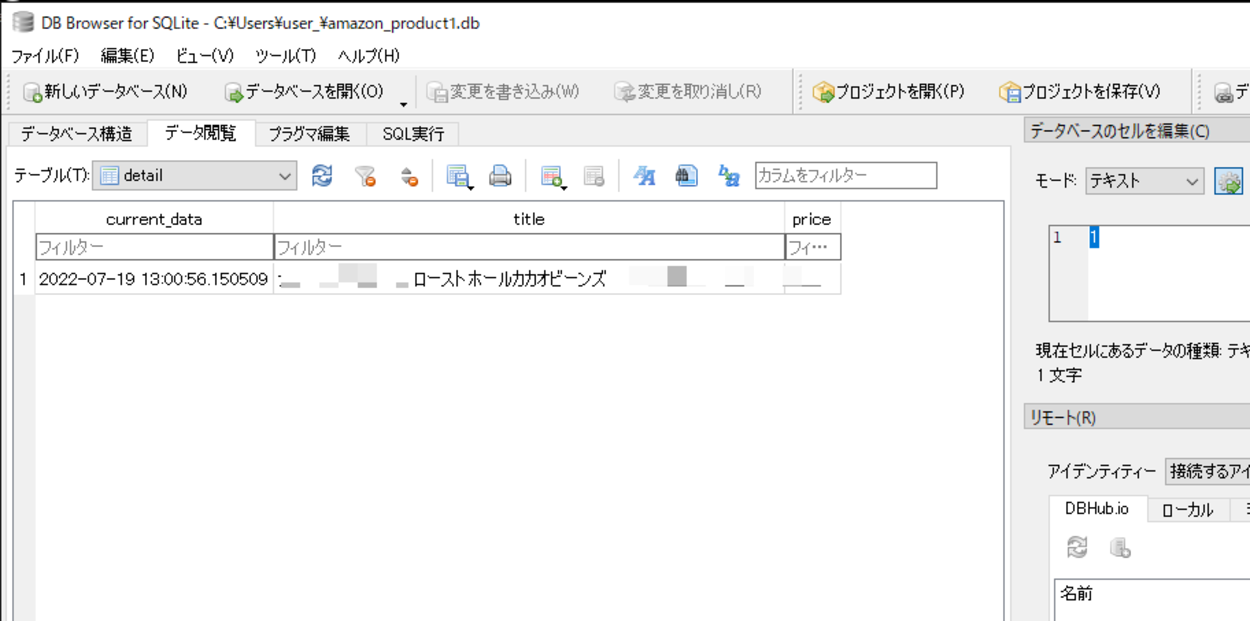
確認後、SQLiteのデータベースを管理できる「DB Browser for SQLite」を用いて「amazon_product1.db」の中身を確認してみると、Webスクレイピングを行い取得した情報が保存されていることが確認できました。

コメント