
Pythonでsplitlines()を用いてファイル内の文字列をリストに分割してみます。
splitlines()関数は、文字列をリストに分割することができます。分割を行う際は、改行で分割が行われます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■ファイルを用意する
splitlines()を用いてファイル内の文字列をリストに分割しますが、その前にファイルを用意します。
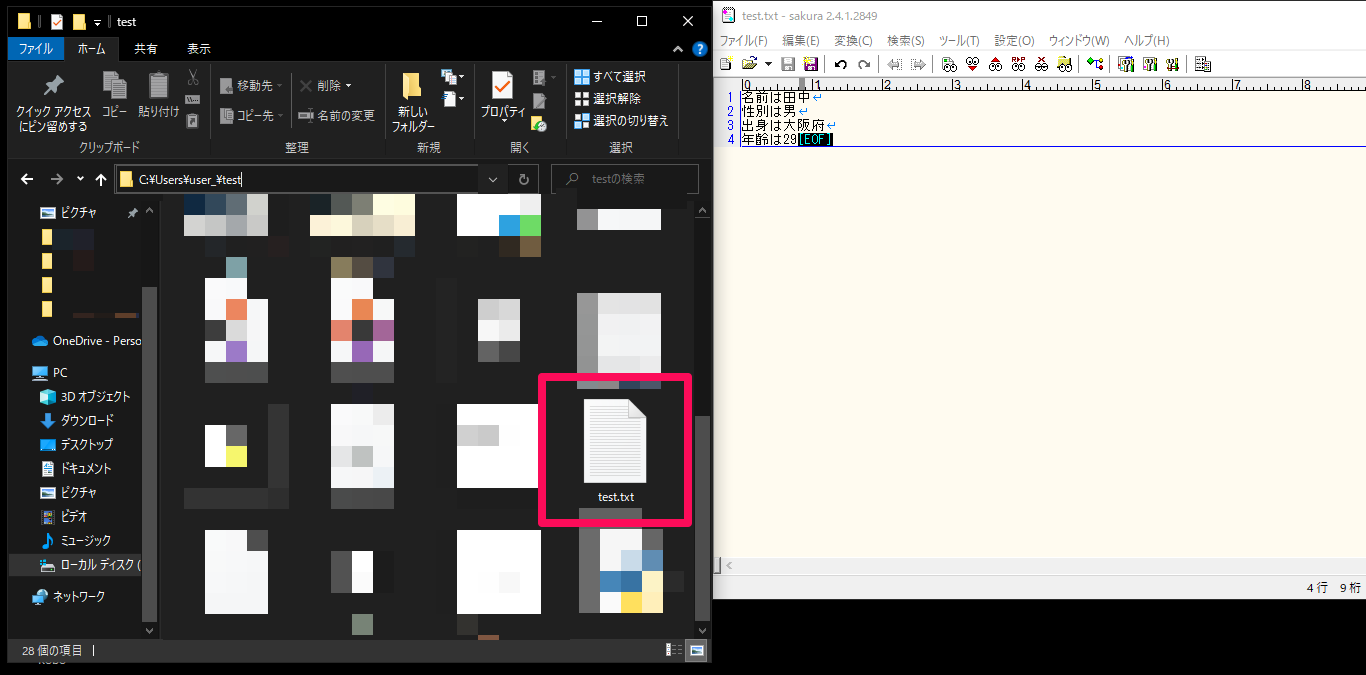
今回は「C:\Users\user_\test(フォルダパス)」内にtxt形式のテキストファイル「test.txt」を用意しました。テキストファイル内は、改行を含んだ文字列が配置されています。
■splitlines()を用いてファイル内の文字列をリストに分割する
ファイルの用意ができましたので、splitlines()を用いてファイル内の文字列をリストに分割するスクリプトを書いていきます。
■コード
File_Object = open(r"C:\Users\user_\test\test.txt","r") File_Data = File_Object.read() lines = File_Data.splitlines() print(lines) File_Object.close()
今回は、File_Objectという変数を定義し、その中でopen()関数を用います。括弧内の第1の引数,パラメータには、用意したファイルの名前,パスを渡します。第2の引数,パラメータには、”r”を渡します。”r”は読み込み専用のモードです。これで開いたファイルの中身がFile_Object変数に格納されます。
格納後、File_Dataという変数を定義し、その中でread()関数を用います。これで開いたファイルの中身を読み込みます。読み込んだものをFile_Data変数に格納します。次にlinesという変数を定義し、読み込んだものが格納されたFile_Data変数に対してsplitlines()を用います。これで文字列がリストに分割されます。分割された状態のものがlines変数に格納されます。
格納後、lines変数の情報をprint()関数で出力させます。出力後、File_Object変数の開いた状態のファイルをclose()関数を用いて閉じます。
■実行・検証
このスクリプトを「string_slit.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
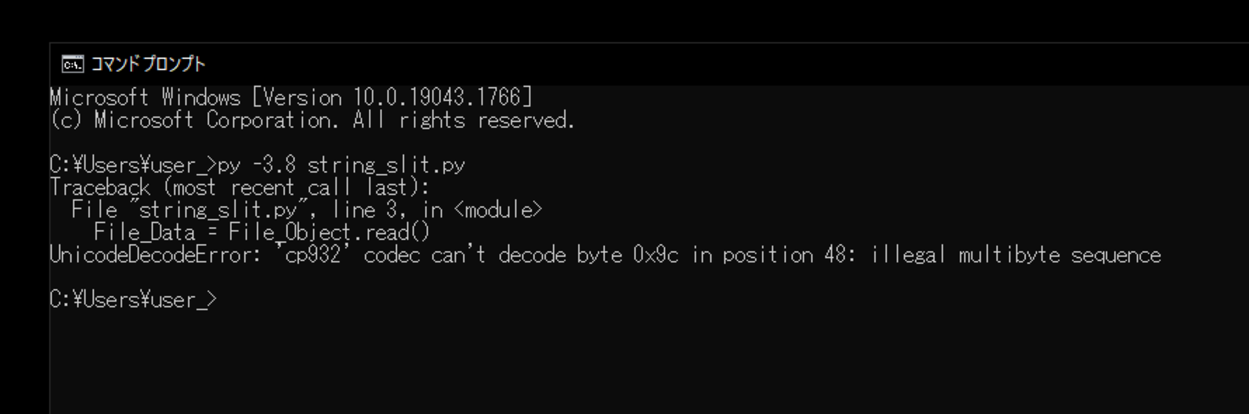
Traceback (most recent call last):
File "string_slit.py", line 3, in
File_Data = File_Object.read()
UnicodeDecodeError: 'cp932' codec can't decode byte 0x9c in position 48: illegal multibyte sequence実行すると「UnicodeDecodeError」というエラーが発生し、文字列を分割することができませんでした。
このエラーを調べてみると、今回用意したファイルがcp932でエンコードされていないため、エラーが発生したと判明。改善するためには、エンコードを変更する必要があると理解する。
■コード
File_Object = open(r"C:\Users\user_\test\test.txt","r",encoding='utf-8') File_Data = File_Object.read() lines = File_Data.splitlines() print(lines) File_Object.close()
理解後、スクリプトファイルをコードエディタで開き、File_Object変数を定義し、その中でopen()関数を用いた時に、括弧内に引数,パラメータ(encoding=’utf-8’)を追加し、スクリプトを保存します。
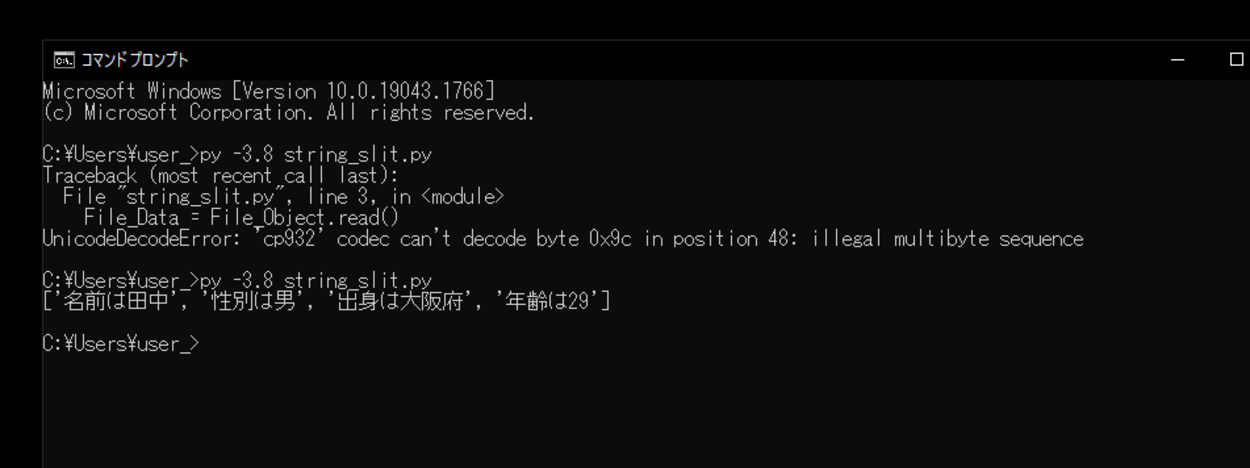
保存後、再度スクリプトを実行してみると、今度はエラーが発生せずにsplitlines()を用いてファイル内の文字列をリストに分割することができました。

コメント