
Pandasモジュールを使用し、Excelファイルをインポートして特定の列を見つけてみます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■Excelファイルを用意する
Pandasモジュールを使用し、Excelファイルをインポートして特定の列を見つける前に、Excelファイルを作成します。
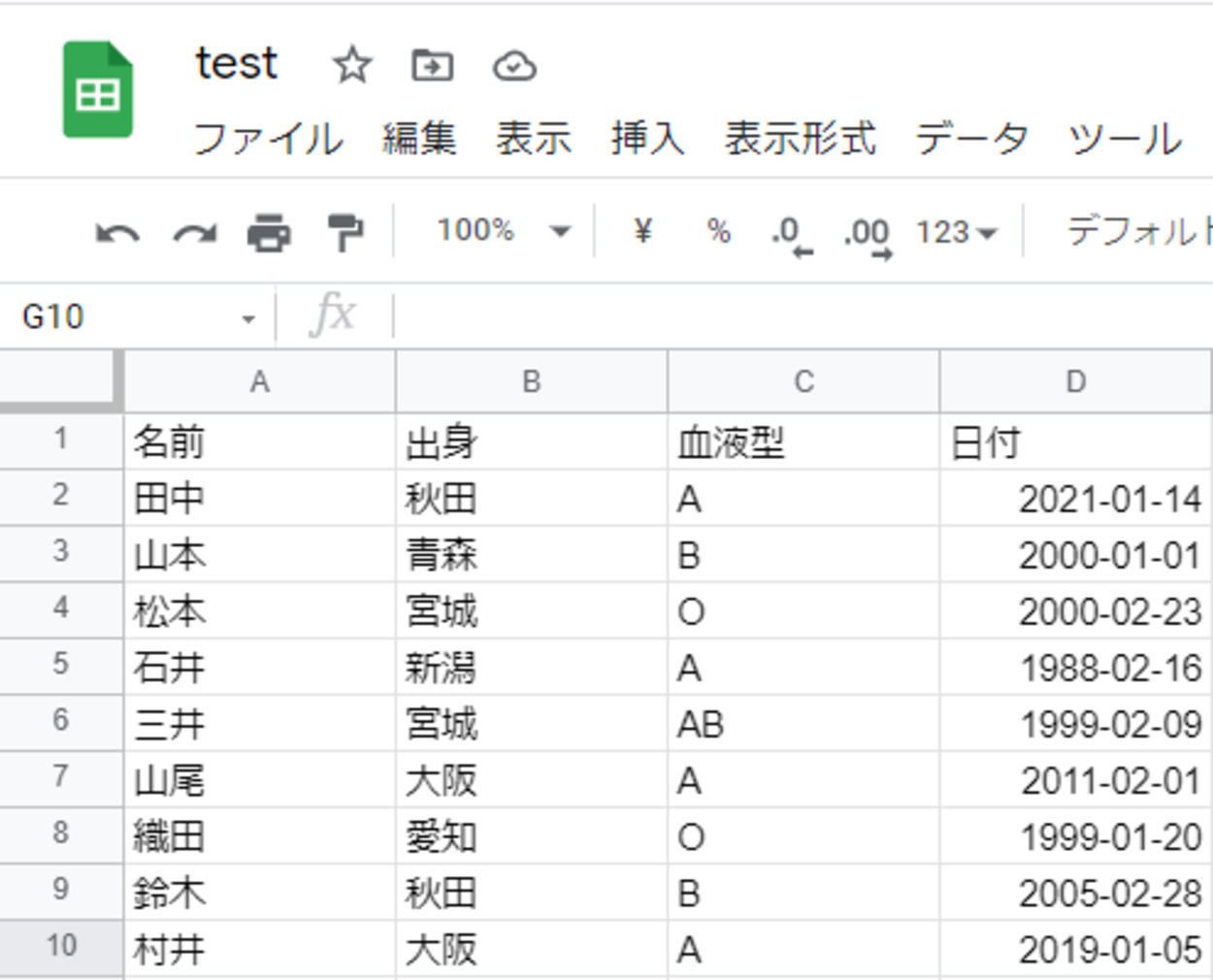
今回は、Googleスプレッドシートで、上記の内容のファイルを作成しました。このファイルを「test.xlsx」というxlsx形式のファイルで保存し、「C:\Users\user\test(フォルダパス)」に置きました。
■Pandasモジュールを使用し、Excelファイルをインポートして特定の列を発見する
Excelファイルの用意ができましたので、Excelファイルを用意Pandasモジュールを使用し、Excelファイルをインポートして特定の列を発見するスクリプトを書いていきます。
■コード
import pandas as pd df = pd.read_excel(r'C:\Users\user\test\test.xlsx') print(df[df['出身'] == '大阪'].head())
インポートでPandasモジュールを呼び出します。dfという変数を作成し、その中に、pd.read_excel()と記述し、今回用意したExcelファイルをdataframeとして読み込み、格納します。
格納後、dataframeとして読み込みExcelファイル内の列を指定し、さらにその列の中で特定の行を指定します。今回は、「出身」という列にある「大阪」という行を指定しています。
指定後、print関数と、head()を使用し、最上位の5つの値を出力してみます。
■実行
このスクリプトを「df_find_col.py」という名前で保存し、コマンドプロンプトから実行してみます。
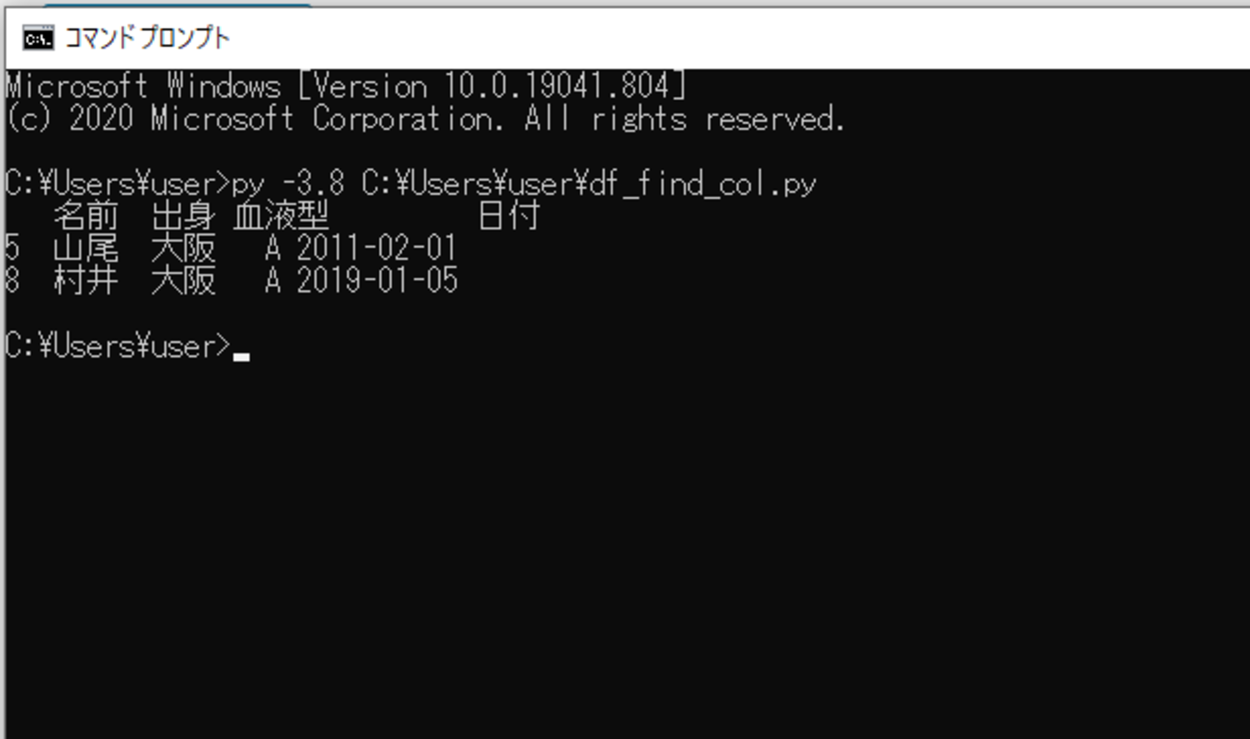
実行してみると、今回用意したExcelファイルの中から指定した列を見つけ出し出力させることができました。

コメント