
Beautiful Soup 4でHTMLを解析しfind_allメソッドで指定した情報を抽出する
(Windows10上)
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■beautifulsoup4のインストール
pip install beautifulsoup4
Windows10で、コマンドプロンプトからpip(パッケージ管理ツール)を使い、beautifulsoup4をインストール。
なお、運営者はpythonランチャーを使用しており、Python Version 3.8.5にインストールを行うために、pipを使う場合にはコマンドでの切り替えます。
py -3.8 -m pip install beautifulsoup4
切り替えるために、上記のコマンドを入力し、Enterキーを押します。
Enterキーを押すと、インストールが開始され、「Successfully installed」と表示されます。これが表示されれば、正常にbeautifulsoup4のインストールは完了となります。
■コード
from bs4 import BeautifulSoup #BeautifulSoupはHTMLから狙ったデータを抽出するため
from urllib import request #urllibはURLを取得する。
url = 'https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%8A%E3%83%81%E3%83%A5%E3%83%A9%E3%83%AB'
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
toctext = soup.find_all('span', class_='toctext')
print(toctext)
今回は、テストとして、ウィキペディアの海外ドラマ「スーパーナチュラル」ページ(https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%8A%E3%83%81%E3%83%A5%E3%83%A9%E3%83%AB)から、find_allメソッドで指定した情報を抽出してみる。テストとして選んだのは、この海外ドラマが好きだからだ。
抽出するのは「目次」の項目全てである。まず、ウィキペディアの海外ドラマ「スーパーナチュラル」ページのソースを確認してみる。

確認すると、目次の項目は、
<span class="toctext">概要</span> <span class="toctext">あらすじ</span>
上記のようなspan要素、class属性が組み合わせている。なので、find_allメソッドでclass属性が「toctext」であるspan要素を抜き出すコードを書いてみる。
soup.find_all('span', class_='toctext')書いたコードをWindows10で、コマンドプロンプトから実行してみる。
■実行結果
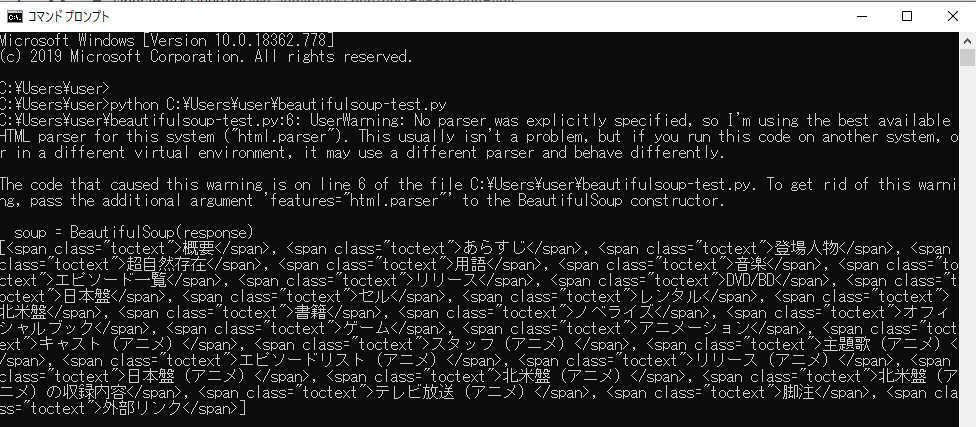
ウィキペディアのページ上からclass属性が「toctext」であるspan要素を検索し、情報が抽出された。
■疑問点
情報が抽出されたのだが、
UserWarning: No parser was explicitly specified, so I’m using the best available HTML parser for this system (“html.parser”). This usually isn’t a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently. The code that caused this warning is on line 6 of the file C:\Users\user\beautifulsoup-test.py. To get rid of this warning, pass the additional argument ‘features=”html.parser”‘ to the BeautifulSoup constructor.
上記のようなUserWarningが表示された。調べてみると、「Beautiful Soup 4.x では parser を明示指定しよう」という内容を投稿されている方がおり、どうやらBeautiful Soup 4.4.xではparserを明示指定しないと、自動選択され、UserWarningが表示されるようだ。自動選択では依存してしまうと環境によって動作が変わるので、parserを明示指定した方が良い。
■今回参考したページ
URL:https://www.atmarkit.co.jp/ait/articles/1910/18/news015.html
URL:https://gammasoft.jp/blog/difference-find-and-select-in-beautiful-soup-of-python/
■今後やりたいこと
Pythonでスクレイピングした情報をCSVに保存するまでをやってみたい。

コメント