
Pythonでsnscrapeを使用し、SNSをスクレイピングしてみます。
snscrapeは、個人のAPIキーを必要としないソーシャルネットワーキングサービス(SNS)のスクレーパーです。snscrapeで対応しているSNSは、Facebook,Instagram,Reddit,Telegram,Twitter,VKontakte,Weibo (Sina Weibo)です。
なお、snscrapeは、開発バージョンでのみ使用できるということを理解しておきましょう。
またsnscrapeを使用するには、Python3.8以降の環境が必要です。snscrapeをインストールすると、Pythonパッケージの依存関係が自動的にインストールされます。
snscrapeライブラリ・モジュール(https://github.com/JustAnotherArchivist/snscrape)を使用しますが、snscrapeライブラリ・モジュールは、Pythonの標準ライブラリではありませんので、事前のインストールが必要です。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■snscrapeをインストールする
それでは、Heliumをインストールするために、今回はpipを経由してインストールを行うので、まずWindowsのコマンドプロンプトを起動します。
pip install snscrape
起動後、上記のコマンドを入力し、Enterキーを押します。
なお、今回は、pythonランチャーを使用しており、Python Version 3.8.5にインストールを行うために、pipを使う場合にはコマンドでの切り替えを行います。
py -3.8 -m pip install snscrape
切り替えるために、上記のコマンドを入力し、Enterキーを押します。
Defaulting to user installation because normal site-packages is not writeable Collecting snscrape Downloading snscrape-0.3.4-py3-none-any.whl (35 kB) Collecting lxml Downloading lxml-4.6.3-cp38-cp38-win_amd64.whl (3.5 MB) |████████████████████████████████| 3.5 MB 1.7 MB/s Requirement already satisfied: beautifulsoup4 in c:\users\user_\appdata\roaming\python\python38\site-packages (from snscrape) (4.9.3) Requirement already satisfied: requests[socks] in c:\users\user_\appdata\roaming\python\python38\site-packages (from snscrape) (2.25.1) Requirement already satisfied: soupsieve>1.2; python_version >= "3.0" in c:\users\user_\appdata\roaming\python\python38\site-packages (from beautifulsoup4->snscrape) (2.2.1) Requirement already satisfied: chardet<5,>=3.0.2 in c:\users\user_\appdata\roaming\python\python38\site-packages (from requests[socks]->snscrape) (4.0.0) Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\users\user_\appdata\roaming\python\python38\site-packages (from requests[socks]->snscrape) (1.26.5) Requirement already satisfied: certifi>=2017.4.17 in c:\users\user_\appdata\roaming\python\python38\site-packages (from requests[socks]->snscrape) (2021.5.30) Requirement already satisfied: idna<3,>=2.5 in c:\users\user_\appdata\roaming\python\python38\site-packages (from requests[socks]->snscrape) (2.10) Collecting PySocks!=1.5.7,>=1.5.6; extra == "socks" Downloading PySocks-1.7.1-py3-none-any.whl (16 kB) Installing collected packages: lxml, snscrape, PySocks Successfully installed PySocks-1.7.1 lxml-4.6.3 snscrape-0.3.4
Enterキーを押すと、インストールが開始され、上記のように「Successfully installed」と表示されます。これが表示されれば、snscrapeが正常にインストールされたことになります。
なお、今回はsnscrapeのバージョン0.3.4をインストールしました。
■Twitterのツイートをスクレイピングする
インストール完了後、Twitterで特定のキーワードのツイートをスクレイピングするスクリプトを書いていきます。
■コード
import pandas as pd import snscrape.modules.twitter as sntwitter import itertools #ツイート検索するキーワード search = "大阪" #Twitterでスクレイピングを行い特定キーワードの情報を取得 scraped_tweets = sntwitter.TwitterSearchScraper(search).get_items() #最初の10ツイートだけを取得し格納 sliced_scraped_tweets = itertools.islice(scraped_tweets, 10) #データフレームに変換する df = pd.DataFrame(sliced_scraped_tweets) print(df)
sntwitter.TwitterSearchScraper()関数の括弧内に、引数,パラメータとして、search変数に格納した検索キーワードを渡します。Twitter検索でツイートをスクレイピングする。スクレイピングした情報をscraped_tweets変数に格納し、itertools.islice()関数を使用し、スクレイピングした情報をコピーし、Twitter検索結果の最初の10ツイートだけを、sliced_scraped_tweets変数に格納。
格納後、pd.DataFrame()関数を使用し、sliced_scraped_tweets変数内の情報を、データフレームに変換し、df変数に格納。
df変数をprint()関数で出力する。
■実行
このスクリプトを「twitter_scraping.py」という名前で保存し、コマンドプロンプトから実行してみます。
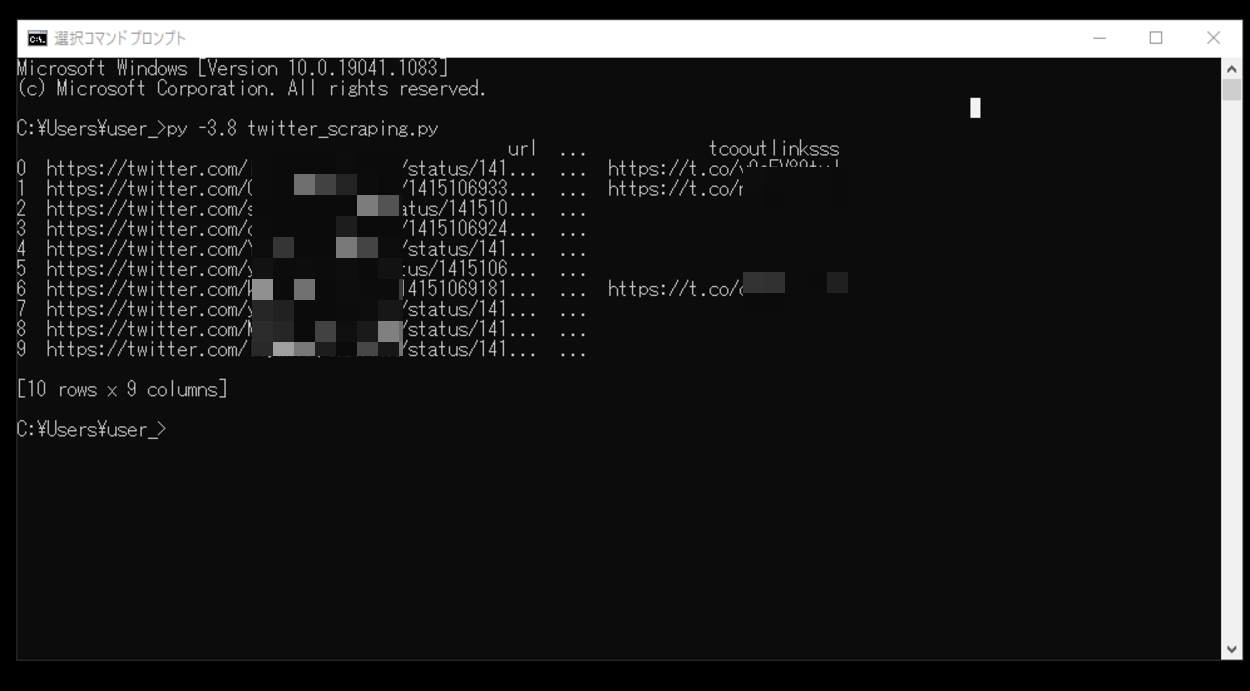
実行してみると、Twitterで特定のキーワードのツイートがスクレイピングされて、スクレイピングされた情報をデータフレームに変換し、出力させることができました。

コメント