
PythonでEasyOCRを使用し画像内のテキストと数字の検出してみます。
今回はEasyOCRライブラリを使用しますので、事前にPythonにインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■画像を用意する
画像内のテキストと数字を検出してみますので、まずは画像を用意します。

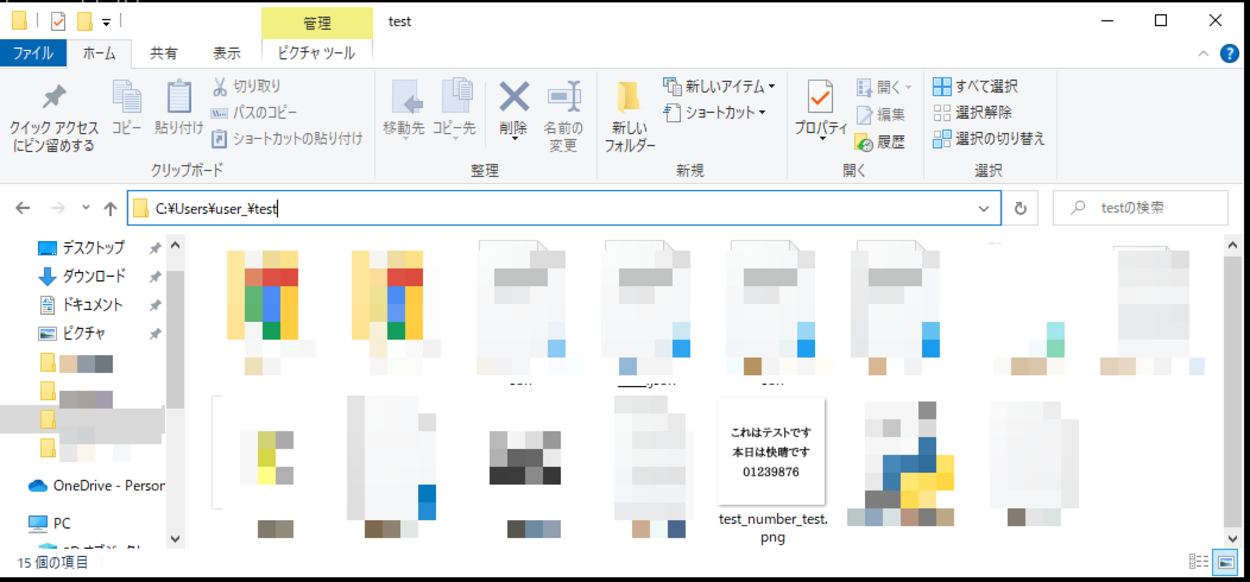
今回は「test_number_test.png」というPNG形式の画像を用意します。画像が置かれている場所は「C:\Users\user_\test(フォルダパス)」となります。
■EasyOCRを使用し画像内のテキストと数字の検出する
画像が用意できたので、EasyOCRを使用し画像内のテキストと数字の検出するスクリプトを書いていきます。
■コード
import easyocr reader = easyocr.Reader(['ja']) result = reader.readtext(r"C:\Users\user_\test\test_number_test.png",detail=0) print(result)
画像内のテキストと数字の検出するために、easyocrをimportで呼び出します。その後に、readerという変数を定義し、easyocr.Reader()でモデルをメモリにロードします。この際に、読み取りたい言語を引数,パラメータで渡します。今回は日本語を読み取りますので、「[‘ja’]」としています。
モデルをメモリにロード後、reader変数に格納。格納後、resultという変数を定義し、reader.readtext()でテキストと数字を検出しますので、画像を引数,パラメータとして渡します。括弧の第1の引数,パラメータに、画像が置かれている場所と、ファイル名を渡します。第2の引数,パラメータには、「detail=0」を渡し、簡単な出力のみを今回は行います。これで、画像内のテキストと数字が検出され、情報がresult変数に格納されます。
最後に、print()関数でresult変数の情報を出力します。
■実行・検証
このスクリプトを「e_ocr.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
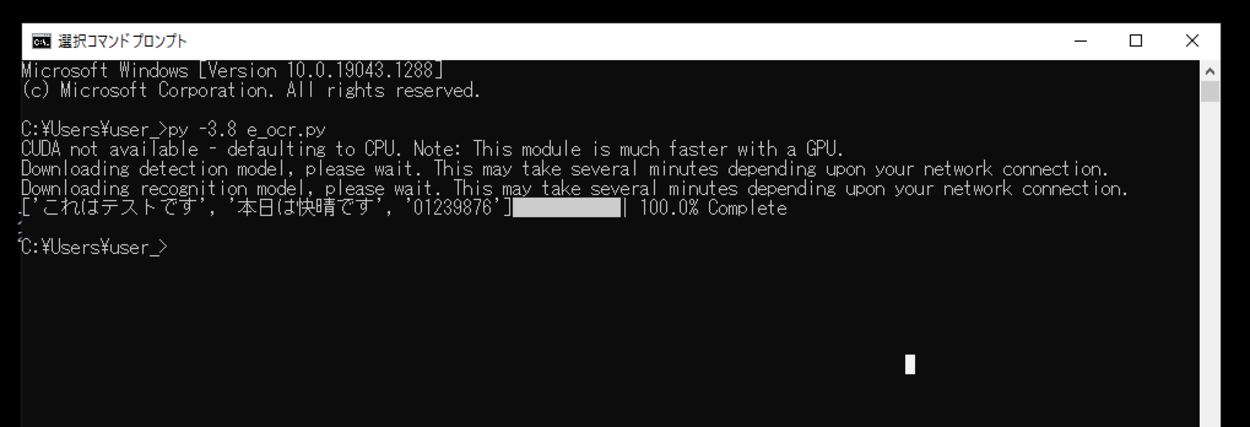
実行してみると、「CUDA not available – defaulting to CPU. Note: This module is much faster with a GPU.(CUDAは利用できません。デフォルトではCPUになります。注:このモジュールは、GPUを使用した方がはるかに高速です。)」と出力され、その後に「Downloading detection model, please wait. This may take several minutes depending upon your network connection.(検出モデルをダウンロード中です、お待ちください。お使いのネットワーク環境によっては、数分かかる場合があります。)」と出力され、テキストと数字を検出するためのモデルのダウンロードが開始され完了となります。さらに「(Downloading recognition model, please wait. This may take several minutes depending upon your network connection.(認識モデルをダウンロードしています、お待ちください。お使いのネットワーク環境によっては、数分かかる場合があります。)」と出力され、今後は認識モデルのダウンロードが開始され、完了となります。
完了後、今回用意した画像内のテキストと数字が検出され、print()関数で出力させることができました。

コメント