
RequestsとBeautifulSoupを使用しPythonでWebページのコンテンツを取得してみます。
なお、RequestsとBeautifulSoupモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python
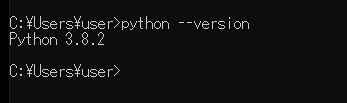
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■RequestsとBeautifulSoupモジュールを使用してWebページのコンテンツを取得する
では、早速RequestsとBeautifulSoupモジュールを使用してWebページのコンテンツを取得するスクリプトを書いていきます。
■コード
import requests
from bs4 import BeautifulSoup
getwebcontent = requests.get("https://laboratory.kazuuu.net/")
getwebcontent_soup= BeautifulSoup(getwebcontent.text, 'html.parser')
print(getwebcontent_soup.prettify())RequestsとBeautifulSoupモジュールをインポートで呼び出し、getwebcontentという変数を作成し、requests.get()で、Webページを取得します。今回は当サイトであるURL「https://laboratory.kazuuu.net/」を指定し、Webページを取得します。
次にgetwebcontent_soupという変数を作成し、BeautifulSoup()で第1のパラメーターでWebページのコンテンツを取得するために、解析を行うので、解析を行うWebページを指定します。第2のパラメーターで、「html.parser」と記述します。これはHTMLテキストを解析するものです。
最後にprint関数でWebページの解析を行った結果を出力します。
■実行
今回のスクリプトを「get_webcontent.py」という名前で保存し、コマンドプロンプトから実行してみます。
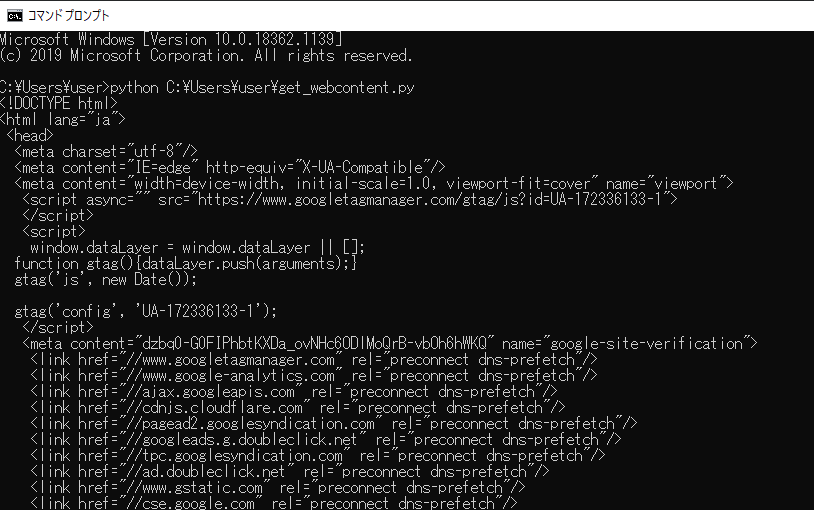
実行してみると、こちらで指定したWebページが解析されコンテンツが取得され、print関数で出力されることができました。
今回の解析したWebページはHTTPSプロトコルだったのですが、エラーが発生せずに、問題なく解析されました。

コメント