
Pythonでpandasを使用しクロス集計を行ってみます。
■Python
Google Colaboratory(Google Colab),Python3.7.10
■データセット(CSVファイル)を用意する
Pythonでpandasを使用しクロス集計を行ってみますので、まずはデータセット(CSVファイル)を用意します。

今回はGoogleスプレッドシートで、上記のCSV形式でデータセットを用意しました。ファイルの名前は「test.csv」とします。
■pandasを使用しクロス集計をする
データセットの用意ができましたので、pandasを使用しクロス集計を行ってみます。
■コード
from google.colab import drive
今回は「Googleドライブ」上に「Python」というフォルダを作成し、その中にtest.csvを移動させていますので、Google Colabへのマウントを行うために、上記のコードを記述します。
※注意
GoogleColaboratoryの「ファイル」からCSVファイルを「アップロード」を行った方が良い。”Googleドライブ”上からCSVファイルのアップロードを行うと、「gsheet」という形式のファイルに勝手に変換されてしまう。
■コード
drive.mount('/content/drive')さらにdriveへのマウントを行うために、上記のコードを記述します。
Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=***** Enter your authorization code:
記述後、コードを実行すると、上記のメッセージが出力されますので、「Go to this URL in a browser」のリンクをクリックし、Googleドライブの認証作業を行い、完了後、コードが発行されるので、コードをコピーし、「Enter your authorization code:」の入力欄に貼り付けます。その後、Enterキーを押します。押すと、「Mounted at /content/drive」と出力されます。これでマウントは完了となります。
■コード
import pandas as pd
df = pd.read_csv('drive/MyDrive/Python/test.csv')
crosstb = pd.crosstab(df['都道府県'], df['購入品'])
print(crosstb)マウント完了後、importでpandasモジュールを呼び出し、pd.read_csv()を用いて括弧内に今回用意したCSVファイルが置かれている場所(パス)を渡し、CSVを読み込みます。
その後、pd.crosstab()関数を用いてクロス集計を行うために、括弧内で集計するデータを指定します。今回は都道府県別の購入品の個数を集計する。クロス集計の結果はcrosstb変数に格納されます。
最後にprint()関数で結果を出力します。
■実行・検証
スクリプトを作成後、このスクリプトを実行してみます。
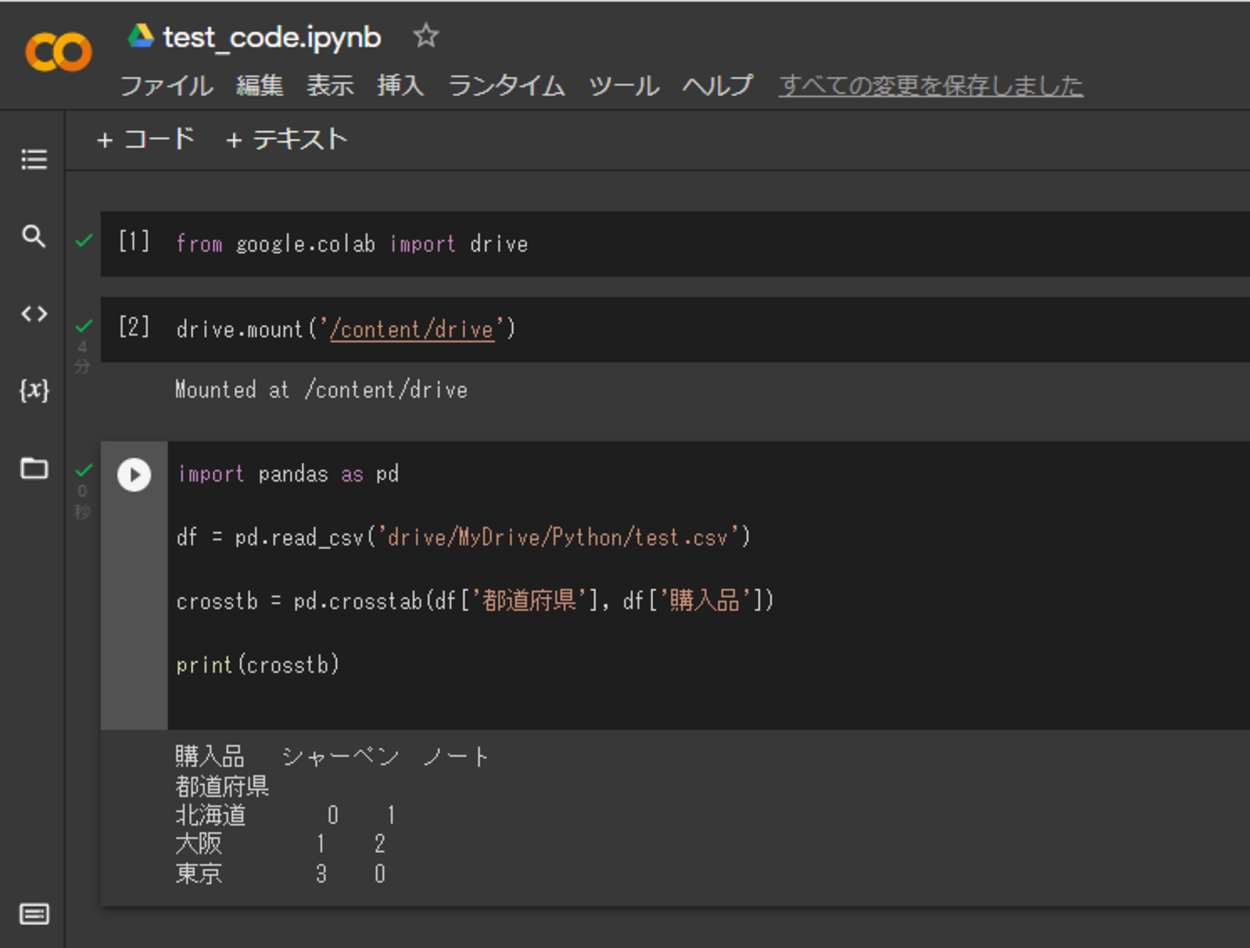
実行してみると、pandasモジュールを用いて、今回用意したデータセット(CSVファイル)を読み込み、データセット内のデータをpd.crosstab()関数を用いてクロス集計し、結果をprint()関数で出力させることができました。

コメント