
urllib.parseのurlparseを用いて与えられたURLを解析しその情報を返してみます。
なお、今回はurllib.parseを用います。 このライブラリ・モジュールはPythonの標準ライブラリの一部です。urllib.parseモジュールはPythonのバージョン2.7以上で利用可能であり、URLの解析、構築、エンコード、デコードなどの機能を提供しています。
■Python
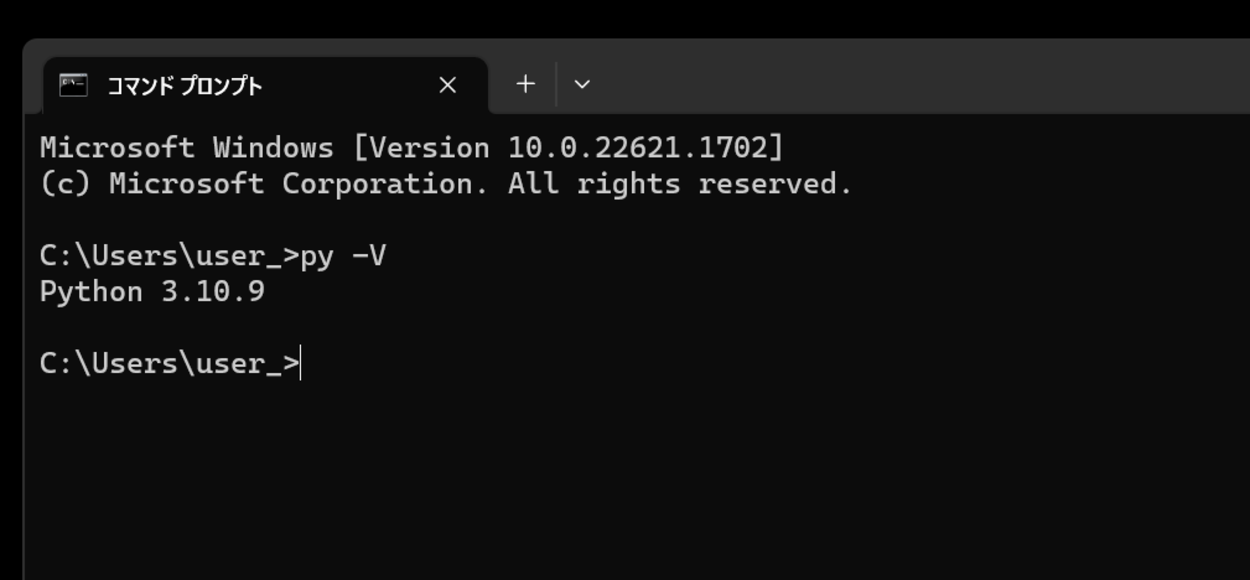
今回のPythonのバージョンは、「3.10.9」を使用しています。(Windows11)(pythonランチャーでの確認)
■urllib.parseのurlparseを用いて与えられたURLを解析しその情報を返す
では、urllib.parseのurlparseを用いて与えられたURLを解析しその情報を返すスクリプトを書いていきます。
■コード
from urllib.parse import urlparse URL = 'https://en.wikipedia.org/wiki/Python_(programming_language)' parsed_url = urlparse(URL) print(parsed_url)
まずはurllib.parse モジュールのurlparse関数をインポートします。次に、解析したいURLをURLという変数を定義し格納します。今回はWikipediaのPythonプログラミング言語のページに対するURLを使っています。
parsed_urlという変数を定義し、その中でurlparse(URL) を呼び出すことで、与えられたURLを解析します。解析結果は ParseResult オブジェクトとして返され変数内に格納されます。このオブジェクトはURLの様々な部分(スキーム、ネットロケーション、パス、パラメータ、クエリ、フラグメント)を属性として持ちます。
最後に、parsed_url内の情報を出力します。これにより、URLがスキーム、ネットロケーション、パス、パラメータ、クエリ、フラグメントに分割された結果が表示されます。
■実行・検証
このスクリプトを「url_p.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
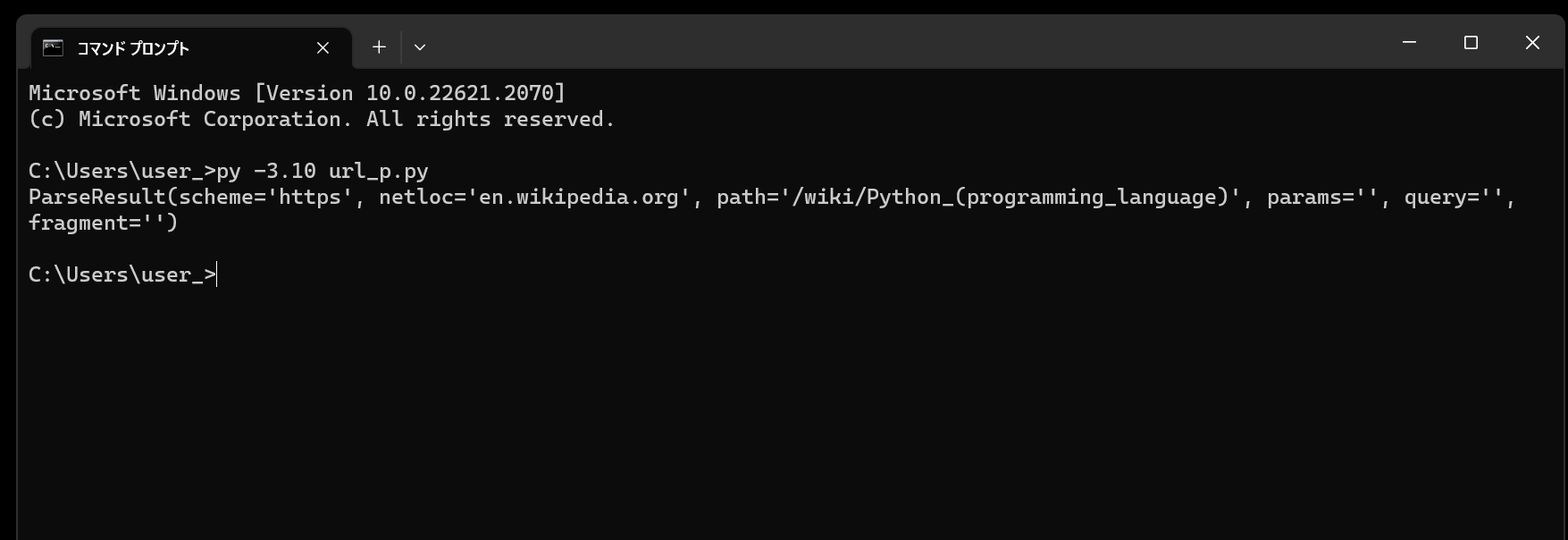
実行してみると、今回指定したURLがスキーム、ネットロケーション、パス、パラメータ、クエリ、フラグメントに分割された結果が表示されることを確認できました。

コメント