
【Python初心者】Excel操作するOpenPyXLを使用することについて解説しています。(Windows10上)
OpenPyXLは、PythonでExcelの読み書きを行うためのモジュールです。モジュールは、部品的機能を集め、まとまったもの。
■Python
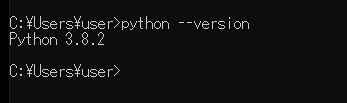
今回のPythonのバージョンは、「3.8.2」を使用しています。
■pipを経由してOpenPyXLをインストール
pip install openpyxl
Pythonにpipを経由して、OpenPyXLをインストールするので、コマンドプロンプトを上記のコードを記述し、ENTERキーを押す。
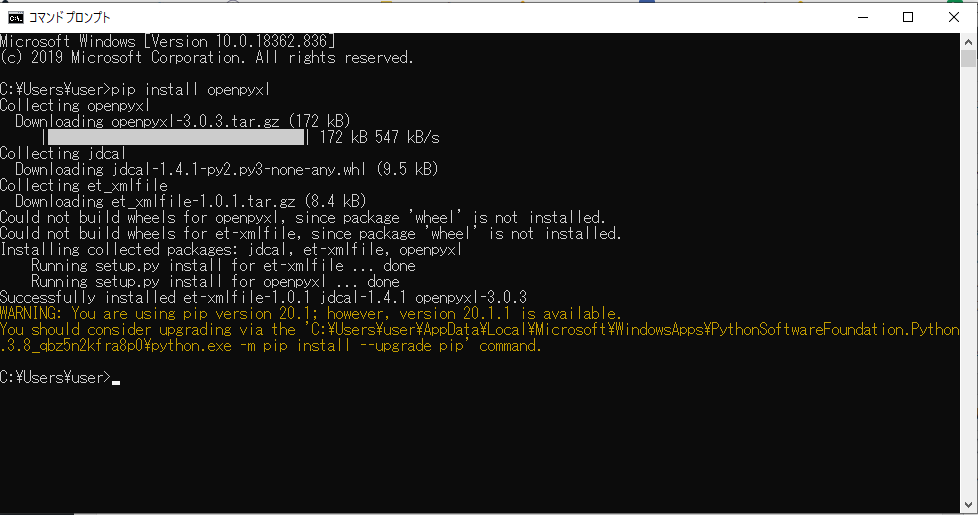
ENTERキーを押すと、OpenPyXLのモジュールが確認され、インストールが開始される。「Successfully installed et-xmlfile-1.0.1 jdcal-1.4.1 openpyxl-3.0.3(et-xmlfile-1.0.1 jdcal-1.4.1 openpyxl-3.0.3が正常にインストールされました)」と表示されると、インストール完了する。
WARNING: You are using pip version 20.1; however, version 20.1.1 is available.
You should consider upgrading via the ‘C:\Users\user\AppData\Local\Microsoft\WindowsApps\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\python.exe -m pip install –upgrade pip’ command.
上記のWARNINGが表示されているが、pipのバージョンのアップグレードができるので検討してくださいというもので、エラーではないので、インストールはこれで完了となる。
■サンプルのXLSXファイルを用意する
Excel操作するOpenPyXLを使ってみますので、サンプルでXLSXファイルを用意します。今回はGoogleスプレッドシートでXLSXファイルを作成します。
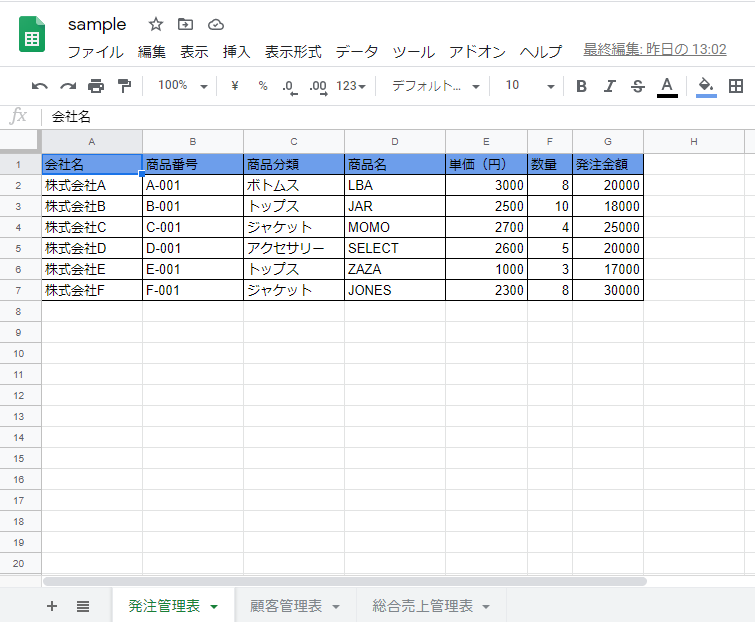
作成するXLSXファイルは上記のようなものを作成しました。これをXLSXファイルで保存。
■XLSXファイルを読み込むコードを書く
PythonにOpenPyXLをインストールしましたので、XLSXファイルを読み込むコードを書いていきます。参考にしたのはこちらです。
■コード
import openpyxl import pandas as pd import glob #patch import_file_path = r'C:\Users\user\pythonautomation\sample.xlsx' excel_sheet_name = '発注管理表' export_file_path = r'C:\Users\user\pythonautomation\output' df_order = pd.read_excel(import_file_path, sheet_name = excel_sheet_name) comany_name =df_order['会社名'].unique() for i in comany_name: print(i)
今回は、openpyxlのimport以外にも、データ解析を支援する機能を提供するpandas、引数に指定されたパターンにマッチするファイルパス名を取得できるglobもimportしています。
試しに、今回作成したXLSXファイルを読み込んで、XLSXファイルの「発注管理表」シートの「会社名」を先頭から順番に出力してみます。
なお、コードを書く際に、「Visual Studio Code」を使用して書いていたが、
import_file_path = r’C:\Users\user\pythonautomation\sample.xlsx’
上記のようなファイルの場所(パス)を指定する際に、「C:\Users\user\pythonautomation\sample.xlsx」のみだと、
(unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape (<unknown>, line 7)
上記のようなunicode errorが発生する。これを調べてみると、文字列リテラル中の\はエスケープに使われ、「C:\Users」という文字列の \U以下がエスケープシーケンスと見なされてしまうため、エラーが発生してしまう。そのため、「 r’C:\Users」のようにraw文字を使いエスケープは解釈されないようにする必要がある。
■実行
書いたコードを、「python-automation-excel-test.py」というファイル名で保存し、コマンドプロンプトから実行してみます。
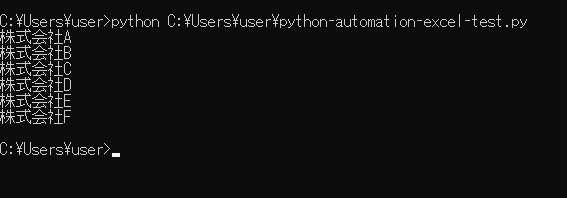
実行してみると、作成したXLSXファイルの中を読み込んで、「発注管理表」シートの「会社名」を先頭から順番に出力することができました。備考として、今回書いたコードを実行する際に、
ImportError: Missing optional dependency ‘xlrd’. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
上記のImportErrorが発生した。調べてみるとpandasをインストールし、XLSXファイルを読み込ませるためには、xlrdパッケージもインストールする必要があり、インストールし実行すると実行できた。
■作成したXLSXファイルの「発注管理表」シートに記載された会社名ごとにXLSXファイルを作成してみる。
作成したXLSXファイルの中を読み込んで、「発注管理表」シートの「会社名」を先頭から順番に出力することができましたので、次に「発注管理表」シートの「会社名」ごとにXLSXファイルを作成してみます。
■コード
import openpyxl import pandas as pd import glob #patch import_file_path = r'C:\Users\user\pythonautomation\sample.xlsx' excel_sheet_name = '発注管理表' export_file_path = r'C:\Users\user\pythonautomation\output' df_order = pd.read_excel(import_file_path, sheet_name = excel_sheet_name) comany_name =df_order['会社名'].unique() for i in comany_name: df_order_company = df_order[df_order['会社名'] == i] df_order_company.to_excel(export_file_path+'/'+i+'.xlsx')
「発注管理表」シートの「会社名」ごとのファイルを作成するので、for文とrange関数を組み合わせ、繰り返し処理を行います。そして、Excelを作成しますので、「to_excel」という記述をします。作成するExcelは「.xlsx」という形式を指定します。
■実行
このコードを、「python-automation-excel-test.py」というファイル名で保存し、コマンドプロンプトから実行してみます。
Traceback (most recent call last):
File “C:\Users\user\python-automation-excel-test.py”, line 20, in <module>
df_order_company.to_excel(export_file_path+’/’+i+’.xlsx’)
File “C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\pandas\core\generic.py”, line 2175, in to_excel
formatter.write(
File “C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\pandas\io\formats\excel.py”, line 738, in write
writer.save()
File “C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\pandas\io\excel\_openpyxl.py”, line 43, in save
return self.book.save(self.path)
File “C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\openpyxl\workbook\workbook.py”, line 392, in save
save_workbook(self, filename)
File “C:\Users\user\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0\LocalCache\local-packages\Python38\site-packages\openpyxl\writer\excel.py”, line 291, in save_workbook
archive = ZipFile(filename, ‘w’, ZIP_DEFLATED, allowZip64=True)
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.8_3.8.1008.0_x64__qbz5n2kfra8p0\lib\zipfile.py”, line 1250, in __init__
self.fp = io.open(file, filemode)
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\user\\pythonautomation\\output/株式会社A.xlsx’
実行してみると、上記のFileNotFoundErrorが発生する。調べてみると、「export_file_path = r’C:\Users\user\pythonautomation\output’ 」で、exportするファイルの場所(パス)を指定していたが、実際に「output」のフォルダを作成していなかったことに気がつく。
「output」のフォルダを作成し、再度プログラムを実行してみる。

実行してみると、今後はエラーは表示されないが、何も表示されません。何も表示されないが、exportする際に指定したファイルの場所(パス)を確認してみます。
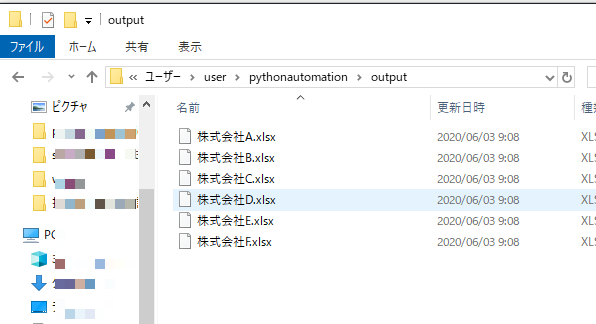
確認してみると、「発注管理表」シートの「会社名」ごとにXLSXファイルを作成されていることが確認できました。
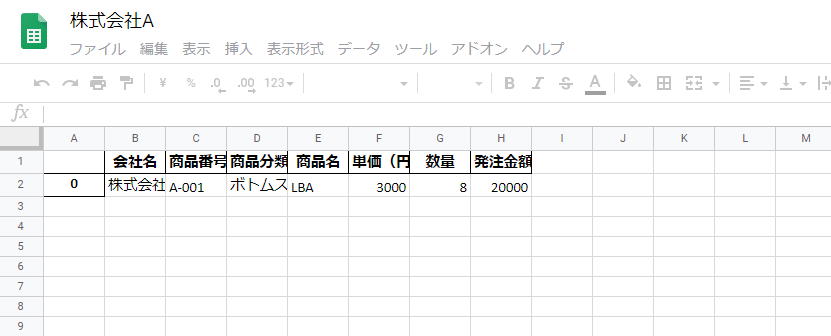
GoogleスプレッドシートでXLSXファイルの中身を確認してみると、会社ごとに商品番号などが出力されていることが確認できました。

コメント