
PandasにおけるDataFrameの行をシャッフルしてみます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■DataFrameを作成する
DataFrameの行をシャッフルする前に、DataFrameを作成します。
■コード
import pandas as pd
data = {
'名前':['鈴木','山田','吉岡','松本','杉田'],
'出身':['山口','愛知','長崎','鹿児島','東京'],
'職業':['税理士','エンジニア','パイロット','運転手','弁護士']
}
df = pd.DataFrame(data)
print(df)インポートでPandasモジュールを呼び出します。dataという変数を作成し、その中に、今回は「名前」,「出身」,「職業」という3つの行を追加し格納します。
格納後、dfという変数を作成し、pd.DataFrame()と記述し、格納したdataを元にDataFrameを作成。作成後、dfという変数に格納します。
■実行
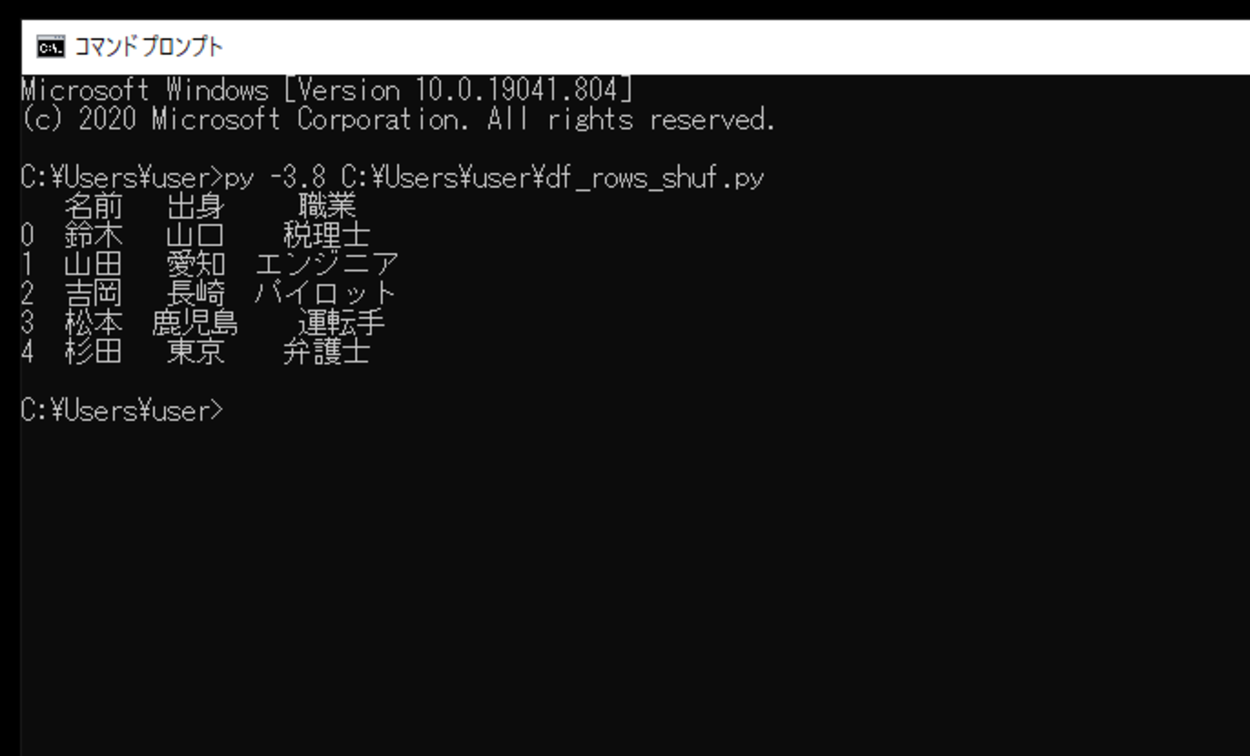
このスクリプトを実行すると、作成したDataFrameが出力されます。
■DataFrameの行をシャッフルする
DataFrameの用意ができましたので、DataFrameの行をシャッフルするスクリプトを書いていきます。
■コード
import pandas as pd
data = {
'名前':['鈴木','山田','吉岡','松本','杉田'],
'出身':['山口','愛知','長崎','鹿児島','東京'],
'職業':['税理士','エンジニア','パイロット','運転手','弁護士']
}
df = pd.DataFrame(data)
print(df)
df = df.sample(frac =1)
print(df)DataFrameの行をシャッフルする場合は、dfという変数を作成し、格納したdataを元にDataFrameを作成。その後に、dfという変数に対して、sample()を使用します。sample()は、リストからランダムに要素を抽出することができるものです。sample()の括弧内に「frac =1」と記述することで、DataFrame内の行をランダムに並び替えることができます。並び替えた後に、dfという変数に格納します。
格納後、print関数でdf変数の情報を出力します。
■実行
このスクリプトを「df_rows_shuf_2.py」という名前で保存し、コマンドプロンプトから実行してみます。
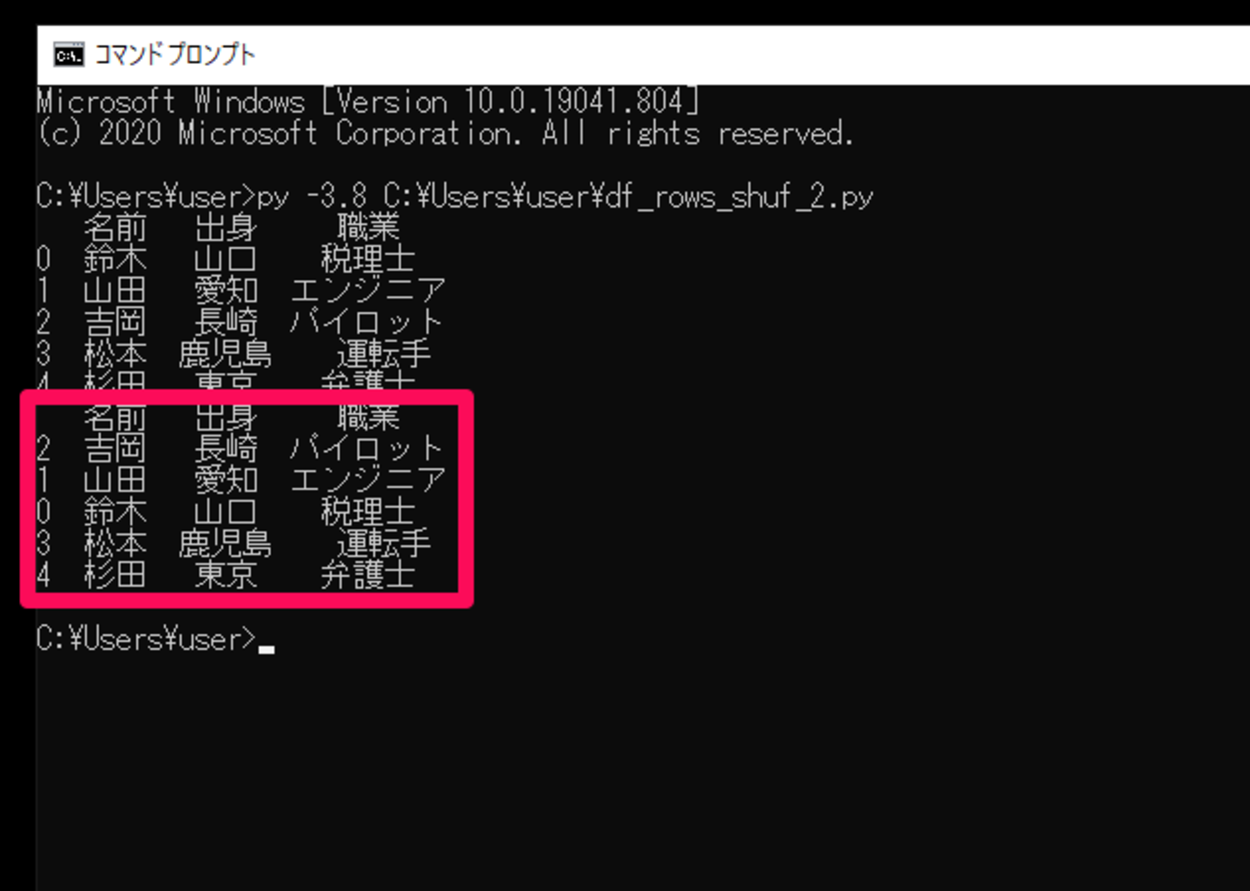
実行してみると、DataFrameの行がシャッフルされて出力されました。

コメント