
PythonのItertoolのgroupby()を用いてリスト内の隣接する同じ要素のサブリストを作ってみます。
Itertools.groupby()は、イテラブル(リストやタプルなどの繰り返し可能なオブジェクト)に存在する各要素のキーを計算し、連続するキーとグループを返すことができます。
■Python
Google Colaboratory(Google Colab),Python3.7.10
■Itertoolのgroupby()を用いてリスト内の隣接する同じ要素のサブリストを作る
では、早速Itertoolのgroupby()を用いてリスト内の隣接する同じ要素のサブリストを作ってみます。
■コード
import itertools list_test = ['田中','田中','吉田','吉田', '吉田','吉田','三澤','三澤','三澤','田中'] newlist = [list(b) for a,b in itertools.groupby(list_test)] print(newlist)
importでitertoolsを呼び出します。その後、今回はlist_testというリストを角括弧”[ ]”を使用し定義します。リスト内には要素(文字列)を格納します。
その後、newlistという変数を定義し、リスト内包表記を用いて、itertools.groupby()を用いてグループ化されたアイテムのキーを、aとbの変数で取り出し、list()を用いリストを作成します。list()の括弧内には、b変数を渡します。これで、リスト内の隣接する同じ要素のサブリストを作成し、newlist変数に格納します。
最後にprint()関数でnewlist変数内の情報を出力します。
■実行・検証
スクリプトを作成後、このスクリプトを実行してみます。
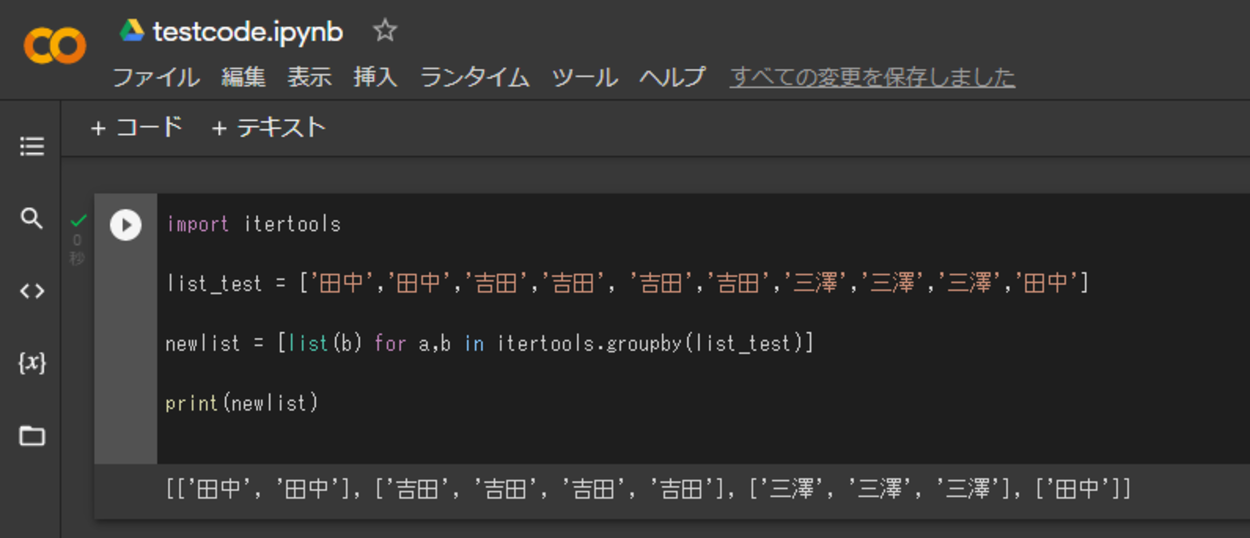
実行してみると、Itertoolのgroupby()を用いたことで、list_testというリスト内で隣接する同じ要素がグループ化され、グループ化されたものをリストとして作成し、リスト内のサブリストとしてprint()関数で出力させることができました。
■コード
import itertools list_test = ['田中','田中','吉田','吉田', '吉田','吉田','三澤','三澤','三澤','田中'] print(list(itertools.groupby(list_test))) #newlist = [list(b) for a,b in itertools.groupby(list_test)] #print(newlist)
出力後、itertools.groupby()を用いてグループ化されたアイテムのキーがどのように出力されるのか確認してみます。
■実行・検証
このコードを実行してみると、下記となります。
[('田中', <itertools._grouper object at 0x7f1eea5caed0>),
('吉田', <itertools._grouper object at 0x7f1eea5cac10>),
('三澤', <itertools._grouper object at 0x7f1eea5ca190>),
('田中', <itertools._grouper object at 0x7f1eea5caf50>)]リスト内で隣接する同じ要素がグループ化(田中,吉田,三澤)されていますが、隣接していない要素(隣接していない’田中’)は、別のグループとして認識されていることが確認できました。

コメント