
PythonでSqlAlchemyを使用しデータベースからデータを取得してみます。
■Python
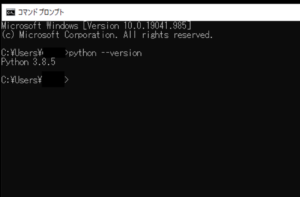
今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■仮想環境の構築
SqlAlchemyを使用しデータベースからデータを取得しますが、その前に仮想環境の構築を行い、インストールを行います。そのために、まずはWindows10のコマンドプロンプトを起動します。
C:\Users\user_>mkdir sql_data
起動後、上記のコマンドを入力し、Enterキーを押します。「mkdir」コマンドで「sql_data」ディレクトリを作成します。
C:\Users\user_>cd sql_data
作成後、上記のコマンドを入力し、Enterキーを押します。「cd」コマンドで「sql_data」ディレクトリ内に移動します。
C:\Users\user_\sql_data>py -3.8 -m venv .venv
移動後、上記のコマンドを入力し、Enterキーを押します。本来だと「python -m venv .venv」で仮想環境のディレクトリ「.venv」を作成しますが、今回はPythonのバージョンを指定しています。なお、今回仮想環境のディレクトリ名は「.venv」としていますが、ご自身で変更は可能です。
Enterキーを押すと、何も出力されませんが、これで仮想環境の作成が完了となります。
■仮想環境への切り替え
C:\Users\user_\sql_data>.venv\Scripts\activate.bat
完了後、上記のコマンドを入力し、Enterキーを押します。仮想環境のディレクトリ内に作成された activateスクリプトを実行し、仮想環境に入ります。
(.venv) C:\Users\user_\sql_data>
Enterキーを押すと、「(.venv)」と表示されます。これで仮想環境に入ることができました。
■SqlAlchemyのインストール
(.venv) C:\Users\user_\sql_data>pip install SQLAlchemy
仮想環境に入った後に、上記のコマンドを入力し、Enterキーを押します。これでpipを経由してSQLAlchemyをインストールします。
Collecting SQLAlchemy Downloading SQLAlchemy-1.4.39-cp38-cp38-win_amd64.whl (1.6 MB) |████████████████████████████████| 1.6 MB 819 kB/s Collecting greenlet!=0.4.17; python_version >= "3" and (platform_machine == "aarch64" or (platform_machine == "ppc64le" or (platform_machine == "x86_64" or (platform_machine == "amd64" or (platform_machine == "AMD64" or (platform_machine == "win32" or platform_machine == "WIN32")))))) Using cached greenlet-1.1.2-cp38-cp38-win_amd64.whl (101 kB) Installing collected packages: greenlet, SQLAlchemy Successfully installed SQLAlchemy-1.4.39 greenlet-1.1.2 WARNING: You are using pip version 20.1.1; however, version 22.2 is available. You should consider upgrading via the 'c:\users\user_\sql_data\.venv\scripts\python.exe -m pip install --upgrade pip' command.
Enterキーを押すと、インストールが開始され、「Successfully installed(正常にインストールされました)」と出力されます。これが出力されればインストールは完了となります。「WARNING:(警告)」が出力されていますが、エラーではないので、今回は一旦無視します。
■標準ライブラリのsqlite3を使用しデータベースの作成
SQLAlchemyをインストール後、Pythonの標準ライブラリのsqlite3を使用しデータベースの作成します。
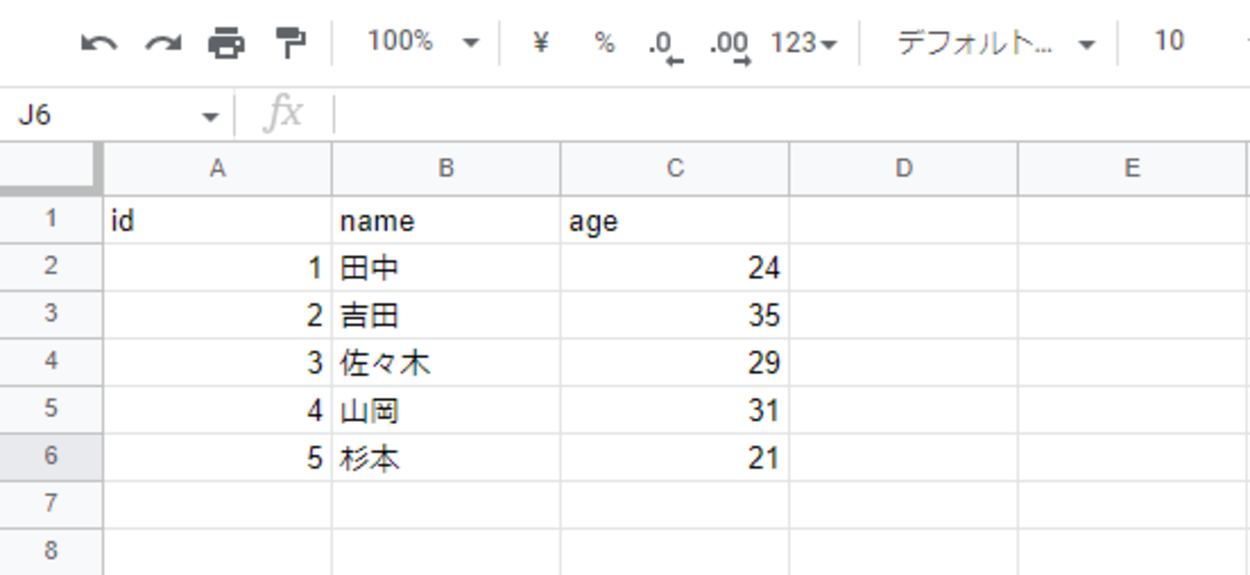
今回作成するデータベースは上記のようなイメージになります。作成するために「 C:\Users\user_\sql_data(フォルダパス)」内に「database_create.py」というスクリプトファイルを作成します。作成後、コードエディタを開きます。
■コード
import sqlite3
conn = sqlite3.connect("test_data.db")
cur = conn.cursor()
cur.execute(
'CREATE TABLE items(id INTEGER PRIMARY KEY AUTOINCREMENT, name STRING, age INTEGER)'
)
conn.close()開いた後に上記のコードを記述していきます。importでsqlite3モジュールを呼び出します。その後、conn変数を定義しその中でsqlite3.connect()を用います。括弧内には引数,パラメータとしてデータベースのファイルパス(位置)を渡しますが、今回は新規で作成しますので、新しいデータベースの名前である「test_data.db」のみを渡します。データベースが存在しない場合には自動的にデータベースを作成してくれます。これでデータベースとの接続がされます。
次にcur変数を定義しその中でconn.cursor() を用います。これでカーソルオブジェクトを作成します。カーソルオブジェクトは、SQLクエリ(データベースに尋ねる質問)を実行するための接続を確立するために使用されるオブジェクトです。
カーソルオブジェクトを作成後、cur.execute()を用います。括弧内の引数,パラメータとしてデータベース操作するクエリまたはコマンドを渡し実行します。この時にSQL文(操作する命令を送るための言語)が必要になります。今回はCREATE文を用いてデータベース内に「items」というTABLE(テーブル)を作成します。作成したTABLE(テーブル)内にはカラム(”列”に該当するもの)を作ります。今回作るカラムとしては「id」、「name」、「age」の3つのカラムになります。さらにこの3つのカラムにはそれぞれどのようなデータを格納するかも指定します。指定する場合はカラム名の後ろに指定します。今回は「id(INTEGER PRIMARY KEY AUTOINCREMENT)」、「name(STRING)」、「age(INTEGER)」と指定します。これデータベース内のテーブルの作成が完了となります。
最後にconn.close()を用いてデータベースとの接続を終了します。
■実行・検証
(.venv) C:\Users\user_\sql_data>python database_create.py
コードを記述後、スクリプトファイルを保存し、Windows10のコマンドプロンプトを起動し、仮想環境へ入り、スクリプトファイルを実行します。
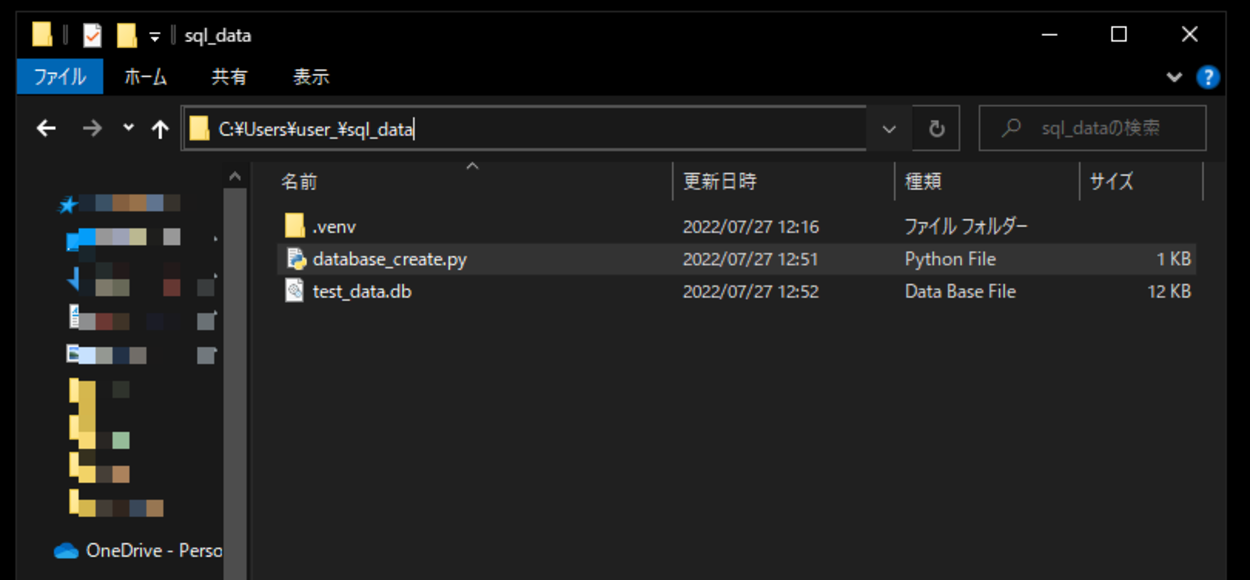
実行してみると、仮想環境下に「test_data.db」というデータベースが作成されたことが確認できました。
■データベース内のテーブルにデータ登録する
確認後、データベース内のテーブルにデータ登録してみますので、今度は「C:\Users\user_\sql_data(フォルダパス)」内に「table_insert.py」というスクリプトファイルを作成します。作成後、コードエディタを開きます。
■コード
import sqlite3
conn = sqlite3.connect("test_data.db")
cur = conn.cursor()
cur.execute('INSERT INTO items values(1, "田中", 24)')
cur.execute('INSERT INTO items values(2, "吉田", 35)')
cur.execute('INSERT INTO items values(3, "佐々木", 29)')
cur.execute('INSERT INTO items values(4, "山岡", 31)')
cur.execute('INSERT INTO items values(5, "杉本", 21)')
conn.commit()
conn.close()開いた後に上記のコードを記述していきます。先程と同じようにimportでsqlite3モジュールを呼び出し、sqlite3.connect()を用いて作成したデータベースとの接続を行います。接続後、conn.cursor() でカーソルオブジェクトを作成し、execute()でデータベース操作するクエリまたはコマンドを渡します。今回はデータベース内のテーブルに登録するデータを挿入するために、INSERT文を用います。INSERTの後にINTO(の中へ)と記述し、先程作成したテーブルの名前を指定し、その後にVALUES()と記述します。VALUES()の括弧内に、カラムに追加するデータ(値)を記述していきます。これでテーブルへのデータ登録は完了します。
完了後、conn.commit()を用います。これでデータベースに対して行った変更を確認し、データベースが更新され、変更が反映されます。逆にこれを用いないとデータベースは更新されず、変更は反映されません。
変更の反映後、conn.close()を用いてデータベースとの接続を閉じます。
■実行・検証
(.venv) C:\Users\user_\sql_data>python table_insert.py
コードを記述後、スクリプトファイルを保存し、Windows10のコマンドプロンプトを起動し、仮想環境へ入り、スクリプトファイルを実行します。
実行すると何も出力されませんが、データベース内のテーブルにデータが登録されます。
■SqlAlchemyを使用しデータベースからデータを取得する
登録後、いよいよここからが本題でSqlAlchemyを使用しデータベースからデータを取得してみます。取得するために、「C:\Users\user_\sql_data(フォルダパス)」内に「get_sql_data.py」というスクリプトファイルを作成します。作成後、コードエディタを開きます。
■コード
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C:\\Users\\user_\\sql_data\\test_data.db')
result = engine.execute('SELECT * FROM '
'"items"')
for data_value in result:
print(data_value)
開いた後に上記のコードを記述していきます。「from import」でsqlalchemyのcreate_engineを呼び出します。その後、engineという変数を定義し、その中でcreate_engine()を用います。括弧内の引数,パラメータとして、作成したデータベースを渡します。これでデータベースとの接続が行われます。なお、PythonでSQLAlchemyを使用しローカルに保存したSQLite3のdbファイルにパスを通す場合にはこちらを参照ください。
その後、resultという変数を定義し、その中でengine.execute()を用います。括弧内には引数,パラメータとしてデータベース操作するクエリまたはコマンドを渡します。今回はSELECT文を用います。「SELECT * FROM」と記述し、その後にデータベース内のテーブルの名前を指定します。これでテーブル内の全ての列のデータを取得できます。取得されたデータはresult変数に格納されます。
格納後、for文を用いて、result変数内から順番にテーブル内のデータを取り出し、取り出されたデータはdata_value変数へ格納され、その後data_value変数の情報をprint()で出力します。
■実行・検証
(.venv) C:\Users\user_\sql_data>python get_sql_data.py
コードを記述後、スクリプトファイルを保存し、Windows10のコマンドプロンプトを起動し、仮想環境へ入り、スクリプトファイルを実行します。

実行してみると、作成したデータベースのテーブル内からデータを取得し出力させることができました。

コメント