
PythonのRequestsとSQLAlchemyを使用し指定したURLのタイトルを取得しデータベースに書き込んでみます。
今回はRequests、BeautifulSoup、SQLAlchemyを用います。これらのライブラリ・モジュールが事前にインストールされているかを確認し実行する場合は実行してください。
■Python
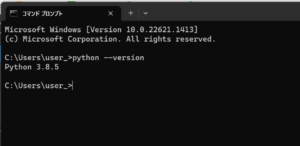
今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows11)
■RequestsとSQLAlchemyを使用し指定したURLのタイトルを取得しデータベースに書き込む
では、早速RequestsとSQLAlchemyを使用し指定したURLのタイトルを取得しデータベースに書き込むスクリプトを書いていきます。
■コード
import requests
from bs4 import BeautifulSoup
from sqlalchemy import create_engine, Column, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# URLからタイトルを抽出する関数
def extract_title(html):
soup = BeautifulSoup(html, 'html.parser')
title = soup.title.string
return title
# データベースモデル
Base = declarative_base()
class Title(Base):
__tablename__ = 'titles'
url = Column(String, primary_key=True)
title = Column(String)
# データベースの設定
engine = create_engine('')
Session = sessionmaker(bind=engine)
session = Session()
# データベースの初期化
Base.metadata.create_all(engine)
# URLからタイトルを取得してデータベースに保存する関数
def save_title(url):
response = requests.get(url)
title = extract_title(response.text)
existing_title = session.query(Title).filter_by(url=url).first()
if existing_title:
existing_title.title = title
else:
new_title = Title(url=url, title=title)
session.add(new_title)
session.commit()
# 使用例
save_title('https://www.yahoo.co.jp/')まず、extract_title(html)関数では、引数としてHTMLのテキストを受け取ります。BeautifulSoupを使用してHTMLをパースし、title要素の文字列を取得します。取得したタイトルを返します。
そして、Titleモデルでは、SQLAlchemyのBaseクラスを継承しています。’titles’という名前のテーブルを定義します。
urlとtitleの2つのカラムを持ち、urlカラムを主キーに設定します。
次にデータベースの設定を行います。create_engine関数を使用して、データベースに接続するためのエンジンを作成します。今回はオンラインDBサービスである「ElephantSQL(https://www.elephantsql.com/)」を用います。ElephantSQLは予め「test_db」という名前でインスタンスを作り、インスタンスのDetailsから「URL」の情報をコピーします。
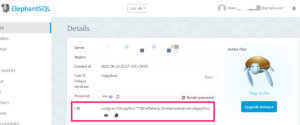
コピーするとURLは「postgres://dsppyfom:***@heffalump.db.elephantsql.com/dsppyfom」のようなものとなっていますが、「postgresql://dsppyfom:***@heffalump.db.elephantsql.com/dsppyfom」と先頭の部分を変更します。変更しないと「sqlalchemy.exc.NoSuchModuleError: Can’t load plugin: sqlalchemy.dialects:postgressql」というエラーが出力されます。
接続先のデータベースの情報を引数に指定します。sessionmakerを使用してセッションを作成し、エンジンにバインドします。sessionオブジェクトを作成します。
設定語、データベースの初期化します。Base.metadata.create_all(engine)を呼び出すことで、データベース内にモデルに対応するテーブルを作成します。
テーブルを作成後、save_title(url)関数を定義します。引数としてURLを受け取ります。requests.get(url)を使用して指定したURLからHTMLを取得します。取得したHTMLをextract_title関数に渡してタイトルを抽出します。session.query(Title).filter_by(url=url).first()を使用して、データベース内に同じURLのデータが既に存在するか確認します。存在する場合は、既存のタイトルを更新します。存在しない場合は、新しいデータとしてタイトルを追加します。変更をデータベースにコミットします。
最後に、save_title(‘https://www.yahoo.co.jp/’)で関数を呼び出します。使用例として「’https://www.yahoo.co.jp/’」のURLからタイトルを取得し、データベースに保存します。
■検証・実行
今回書いたスクリプトを「web_url.py」という名前でPythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
![]()
web_url.py:14: MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9) Base = declarative_base()
実行してみると「MovedIn20Warning」という警告は表示されましたがデータベースへの書き込みは完了しました。
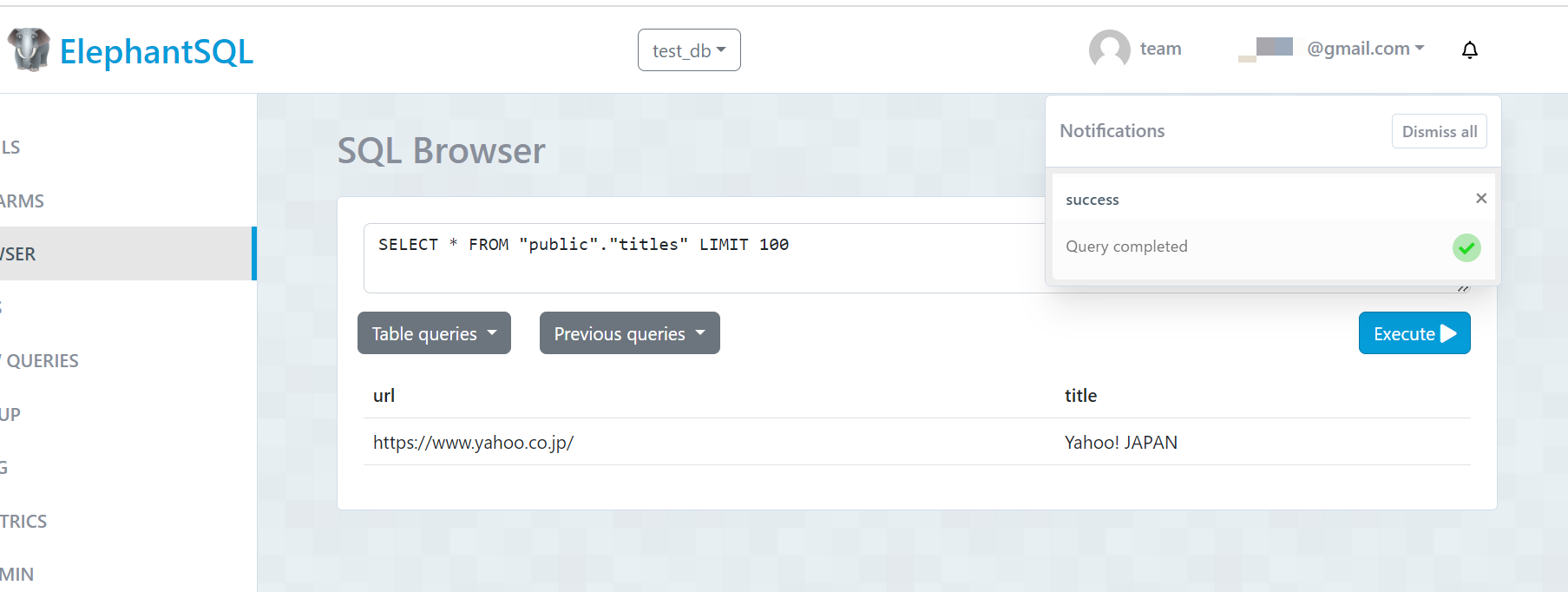
完了後、ElephantSQL上からテーブルを確認すると、テーブル内にデータが書き込まれていることが確認できました。
web_url.py:14: MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9) Base = declarative_base()
なお、上記の警告ですが、下記のように変更すると問題を解決できます。
■修正前
import requests from bs4 import BeautifulSoup from sqlalchemy import create_engine, Column, String from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base
■修正後
import requests from bs4 import BeautifulSoup from sqlalchemy import create_engine, Column, String from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import declarative_base

コメント