
PyPDF2を使用し、PythonでPDFファイルの暗号化及び復号化を行ってみます。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■PyPDF2をインストールする
PyPDF2をインストールを行いますが、今回はpipを経由してインストールを行うので、まずWindowsのコマンドプロンプトを起動します。
pip install PyPDF2
起動後、上記のコマンドを入力し、Enterキーを押します。
なお、今回は、pythonランチャーを使用しており、Python Version 3.8.5にインストールを行うために、pipを使う場合にはコマンドでの切り替えを行います。
py -3.8 -m pip install PyPDF2
切り替えるために、上記のコマンドを入力し、Enterキーを押します。
Processing c:\users\user\appdata\local\pip\cache\wheels\b1\1a\8f\a4c34be976825a2f7948d0fa40907598d69834f8ab5889de11\pypdf2-1.26.0-py3-none-any.whl
Installing collected packages: PyPDF2
Successfully installed PyPDF2-1.26.0
Enterキーを押すと、インストールが開始されます。開始後「Successfully installed」と表示されれば、PyPDF2のインストールが正常に完了となります。
■PDFファイルを用意する
PyPDF2のインストールが完了しましたので、PDFファイルの暗号化及び復号化を行うため、PDFファイルを用意します。
今回は企画提案書のPDFファイル(sample.pdf)を用意しました。
ファイルが保存されている場所は「C:\Users\user\test(フォルダパス)」です。
■PyPDF2を使用し、PDFファイルの暗号化及び復号化
PDFファイルの用意ができましたので、PyPDF2を使用し、PDFファイルの暗号化及び復号化を行うスクリプトを書いていきます。
■暗号化
■コード
from PyPDF2 import PdfFileWriter, PdfFileReader
#PdfFileWriterオブジェクトを作成
out = PdfFileWriter()
#指定したPDFファイルをPdfFileReaderで開く
file = PdfFileReader(r"C:\Users\user\test\sample.pdf")
#PDFファイルのページ数を取得する
num = file.numPages
#PDFファイルの全ページを繰り返し、ファイル作成
#新しいファイルにページを追加する
for idx in range(num):
page = file.getPage(idx)
out.addPage(page)
#パスワードを設定
password = "password"
#入力したパスワードで新しいファイルを暗号化
out.encrypt(password)
#新しいPDFファイルを作成
#暗号化された情報をファイルに書き込み
with open("sample_pass.pdf","wb") as f:
out.write(f)PyPDF2モジュールのPdfFileWriterとPdfFileReaderを呼び出します。PdfFileWriterオブジェクトを作成し、fileという変数を作成し、今回用意したPDFファイルを指定し、PdfFileReaderで開きます。
開いた後に、numという変数を作成し、今回用意したPDFファイル内のページ数を取得し格納します。
取得後、PDFファイル内のページに対してfor文によるループ処理(繰り返し処理)を行います。
行った後にファイルを作成し、そのファイル内にループ処理(繰り返し処理)したページを追加します。
追加後、passwordという変数を作成し、その中にPDFファイルのパスワードを設定し格納します。
格納後、新しいPDFファイルを作成し、先ほど作成したファイル(暗号化された情報)をPDFファイルの中に書き込みます。
■実行
今回のスクリプトを「pdf_encryption.py」という名前で保存し、コマンドプロンプトから実行してみます。

実行してみると、Pythonのカレントディレクトリ(作業ディレクトリ)内に新しいPDFファイルが生成されて置かれていることが確認できました。
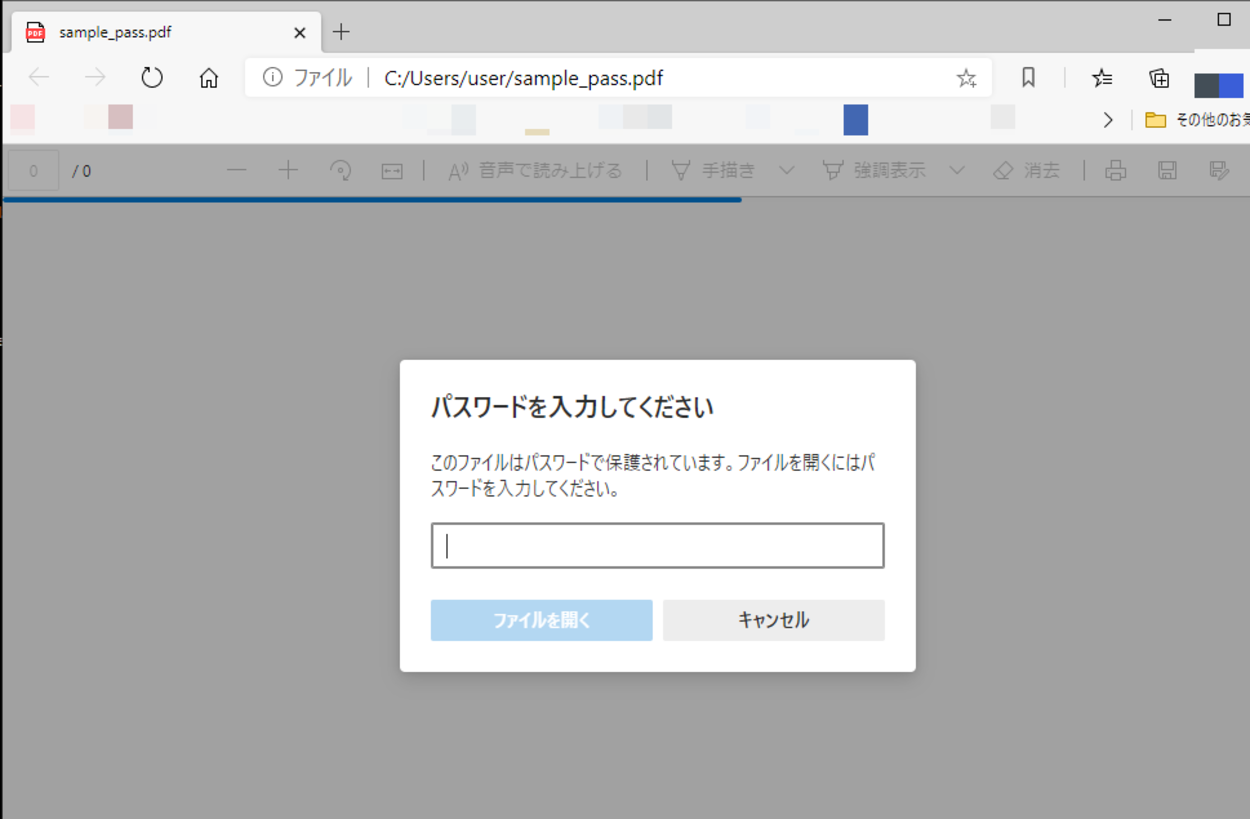
新しいPDFファイルを開いてみると、「パスワードを入力してください」というポップアップが表示され「
■暗号化されたPDFファイルを復号化する
次に今回暗号化されたPDFファイルを、復号化するスクリプトを書いていきます。
■復号化
■コード
from PyPDF2 import PdfFileWriter, PdfFileReader
#PdfFileWriterオブジェクトを作成
out = PdfFileWriter()
#暗号化されたPDFファイルを指定しPdfFileReaderで開く
file = PdfFileReader(r"C:\Users\user\test\sample_pass.pdf")
#PDFファイルに設定したパスワード
password = "password"
#暗号化されているかどうかを確認
if file.isEncrypted:
#パスワードで復号化
file.decrypt(password)
#PDFファイルの全ページを繰り返し、ファイル作成
#新しいファイルにページを追加する
for idx in range(file.numPages):
page =file.getPage(idx)
out.addPage(page)
#新しいPDFファイルを作成
#復号化された情報をファイルに書き込み
with open("sample_decryption.pdf","wb") as f:
out.write(f)
print("正常に復号化されました")
else:
print("既に復号化は行われています")PyPDF2モジュールのPdfFileWriterとPdfFileReaderを呼び出します。
PdfFileWriterオブジェクトを作成し、fileという変数を作成し、今回暗号化されたPDFファイルを指定し、PdfFileReaderで開きます。
開いた後にpasswordという変数を作成し、暗号化されたPDFファイルのパスワードを記述し格納します。
その後、指定した暗号化されたPDFファイルが暗号化されているかどうかを確認するために、if文による条件分岐を行います。
暗号化されていた場合は、file.decrypt()でパスワードで復号化し、PDFファイル内のページに対してfor文によるループ処理(繰り返し処理)を行います。
行った後にファイルを作成し、そのファイル内にループ処理(繰り返し処理)したページを追加します。
追加した後に、新しいPDFファイルを作成し、その中に復号化された情報をファイルに書き込みします。
■実行
このスクリプトを「pdf_decryption.py」という名前で保存し、コマンドプロンプトから実行してみます。

実行してみると、「正常に復号化されました」と出力され、Pythonのカレントディレクトリ(作業ディレクトリ)内に生成されたPDFファイルが置かれていることが確認できました。
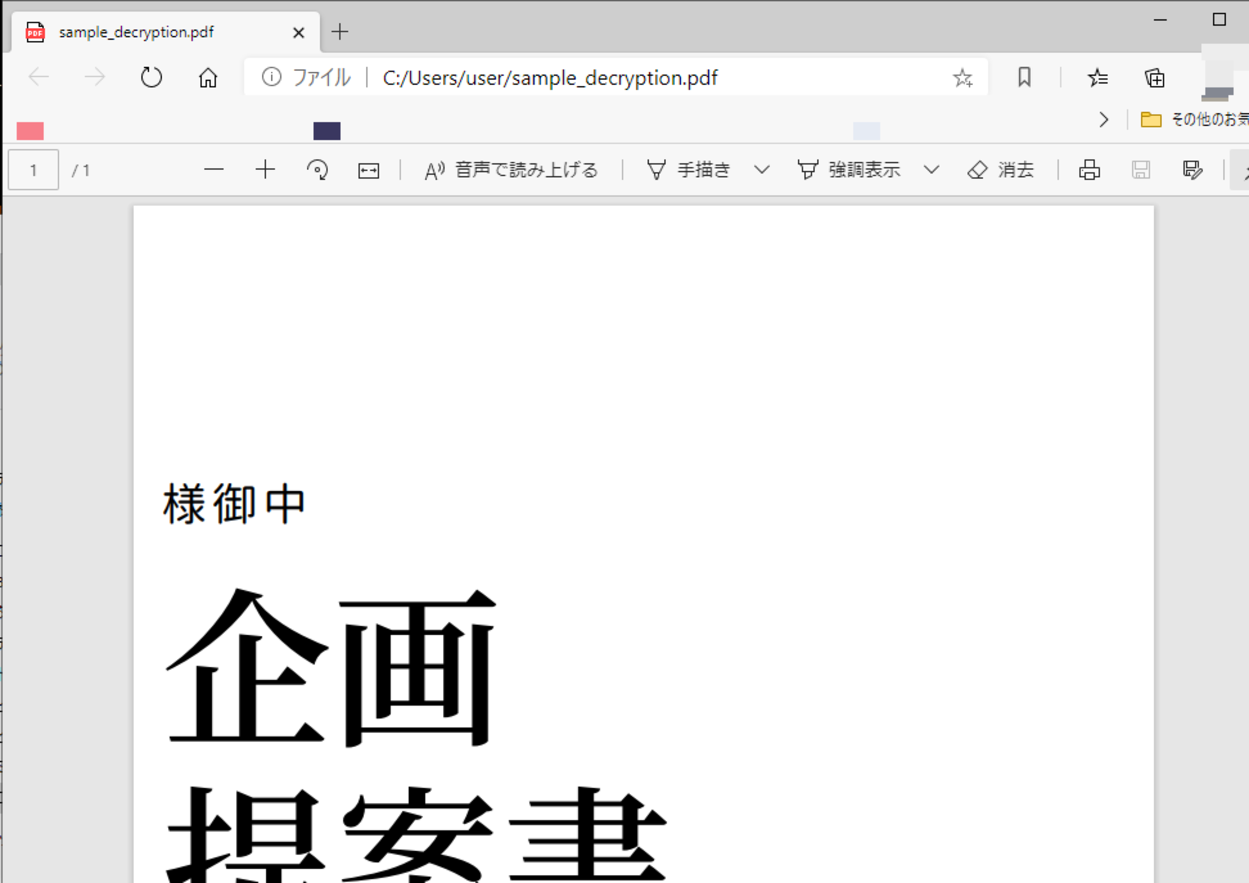
PDFファイルを開くと、暗号化されたPDFファイルの時とは異なり、パスワードの入力が求められず、ファイルの中身を確認することができました。

コメント