
PythonでWebページからすべてのURLを抽出してみます。
今回WebページからすべてのURLを抽出するために、Beautiful Soup(bs4)モジュールと、requestsモジュールを使用します。この2つのモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要はありません。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■WebページからすべてのURLを抽出する
では、早速WebページからすべてのURLを抽出するスクリプトを書いていきます。
■コード
import requests
from bs4 import BeautifulSoup
#URLを指定
url = "https://laboratory.kazuuu.net/sitemaps/"
#GETリクエストを送信
reqs = requests.get(url)
#URLをテキスト化し、解析を行う。その後BeautifulSoupオブジェクトを作る
soup = BeautifulSoup(reqs.text, 'html.parser')
#空のurlsのリストを用意
urls = []
#全てのaタグをループ処理し、hrefで指定されたURLを出力する
for link in soup.find_all('a'):
print(link.get('href'))
Beautiful Soup(bs4)モジュールと、requestsモジュールを呼び出して、urlという変数を作成し、すべてのURLを抽出したいWebページのURLを指定します。今回は当サイトのサイトマップ(https://laboratory.kazuuu.net/sitemaps/)を指定しています。
指定後、reqsという変数を作成し、requests.get()で括弧内にURLを指定し、GETリクエストを送信します。
送信後、soupという変数を作成し、BeautifulSoup()で、GETリクエストを送信し、返ってきた結果で解析を行います。
解析したものの中から全てのaタグをループ処理し、hrefで指定されたURLを抽出し、urlsの空のリストに格納し、print関数で出力します。
■実行
今回のスクリプトを「extract_allurls.py」という名前で保存し、コマンドプロンプトから実行してみます。
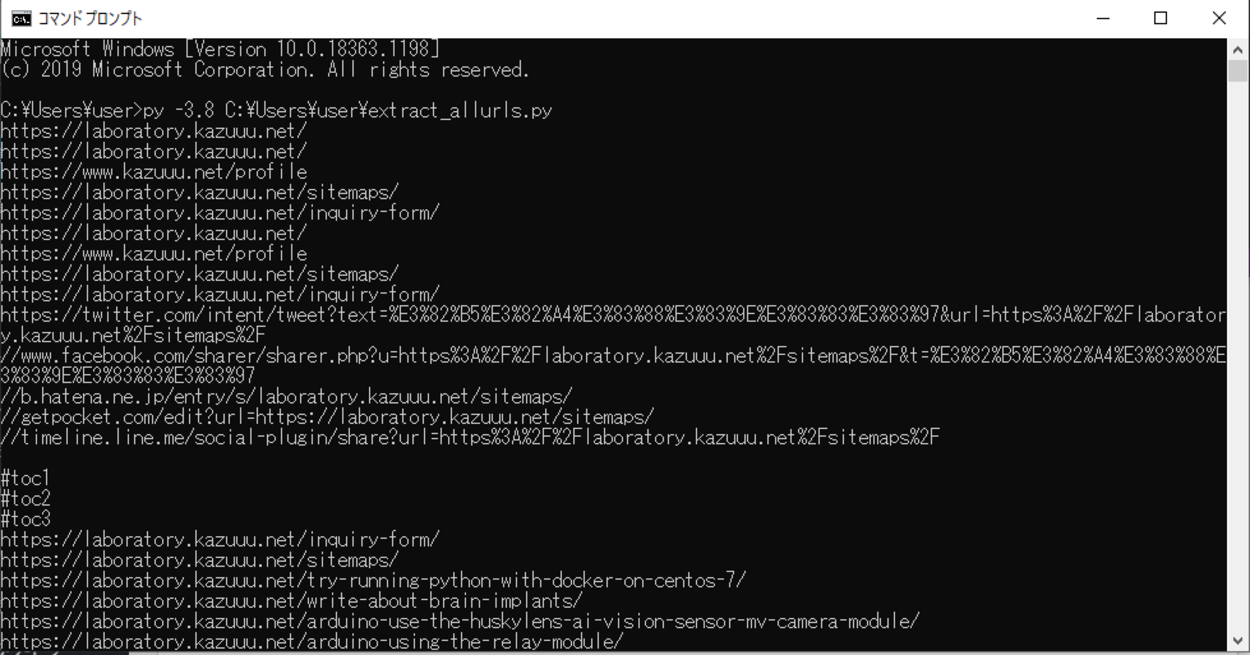
実行してみると、今回指定したサイトマップのページ内にある全てのURLが抽出され出力されることを確認できました。

コメント