
Pdfminerを使用しPythonでPDFファイルからテキストを抽出してみます。
Pdfminerモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■PDFファイルを用意する
PythonでPDFファイルからテキストを抽出してみますが、その前にテキストを抽出するPDFファイルを用意します。
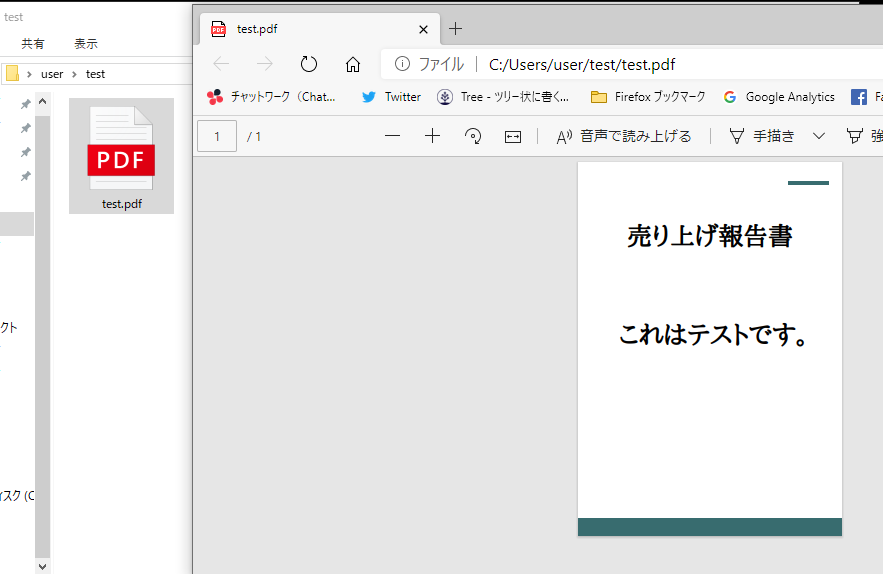
今回用意したのは、「test.pdf」という仮の売り上げ報告書のPDFファイルです。
保存されている場所は「C:\Users\user\test(フォルダパス)」です。
■Pdfminerを使用しPDFファイルからテキストを抽出する
PDFファイルが用意できましたので、Pdfminerモジュールを使用しPDFファイルからテキストを抽出するスクリプトを書いていきます。
■コード
from pdfminer.high_level import extract_text text = extract_text(r"C:\Users\user\test\test.pdf") print(text)
pdfminerのhigh_levelモジュールからextract_textメソッドをインポートします。high_levelモジュールは、PDFファイルからテキストをスクレイピングするための高レベルの関数です。
textという変数を作成し、extract_text()で今回用意したPDFファイルを指定し、テキストを抽出します。
抽出されたテキストをprint関数で出力してみます。
■実行
今回書いたスクリプトを「extract-text-from-pdf.py」という名前で保存し、コマンドプロンプトから実行してみます。

実行してみると、今回用意したPDFファイル内のテキストが抽出されて出力されました。PDFファイル内のテキストが日本語であっても抽出されます。
■パスワードで保護されたPDFファイルからテキストを抽出する

PDFファイル内のテキストを抽出することができましたが、次にパスワードで保護されたPDFファイルからテキストを抽出してみます。
■コード
from pdfminer.high_level import extract_text text = extract_text(r"C:\Users\user\test\test-password.pdf", password = "パスワード") print(text)
パスワードで保護されたPDFファイル内のテキストを抽出する場合は、extract_text()にパスワードで保護されたPDFファイルを指定し、「password = “パスワード”」を記述します。
■実行
「extract-text-from-pdf.py」のスクリプトを変更し、コマンドプロンプトから実行してみます。
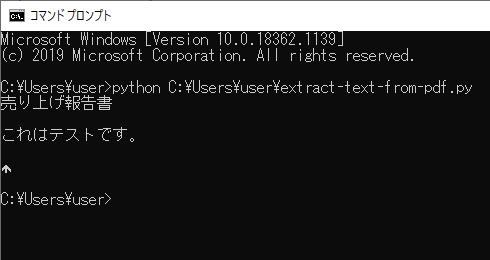
実行してみると、パスワードで保護されたPDFファイル内のテキストが抽出されて出力されることが確認できました。

コメント