
Pythonでhtml5libとrequestsを用いてWebサイトのテキストコンテンツの抽出してみます。
今回はhtml5libとrequestsモジュールを用います。このライブラリはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■今回の環境(Python)
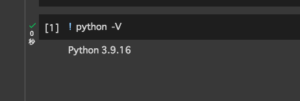
Google Colaboratory(Google Colab),記事作成時点ではPython 3.9.16が用いられる。(事前にhtml5libとrequestsモジュールはインストール済み。)
■html5libとrequestsを用いてWebサイトのテキストコンテンツの抽出する
では、早速html5libとrequestsを用いてWebサイトのテキストコンテンツの抽出するスクリプトを書いていきます。
■コード
import html5lib
import requests
# Fetch the HTML document
response = requests.get('https://www.yahoo.co.jp/')
html = response.text
# Parse the HTML document
tree = html5lib.parse(html, namespaceHTMLElements=False)
# Extract all text content
text_content = []
for element in tree.iter():
if element.text and element.text.strip():
text_content.append(element.text.strip())
# Print the text content
print(text_content)今回はimportでhtml5libとrequestsを呼び出します。その後、responseという変数を定義し、その中でrequestsモジュールに対し(.)ドット演算子を用いてget()メソッドを呼び出します。括弧内には引数,パラメータとして、HTTP GET リクエストを送信するURLを渡します。今回の場合は「Yahoo!Japan(https://www.yahoo.co.jp/)」とします。これでHTTP GET リクエストを 指定したURLに送信し、サーバーの応答を返します。
次にhtmlという変数を定義し、サーバーの応答を返します。応答を使用し、Webサイトから情報を抽出しますので、response変数に対し(.)ドット演算子を用いて情報(text)をhtml変数に格納します。
格納後、treeという変数を定義し、その中でhtml5libモジュールに対し(.)ドット演算子を用いてparse()メソッドを呼び出します。括弧内には第1の引数,パラメータとして、解析する HTML ドキュメントを含む文字列であるhtml変数を渡します。第2の引数,パラメータとして「namespaceHTMLElements=False」とします。これで要素と属性の名前に既定の XML 名前空間が使用されます。これでhtml変数で表されるHTMLドキュメントを解析することができます。なお、parse()メソッドでは、解析ツリーを返します。
次にtext_contentという空のリストを角括弧”[ ]”を用いて定義します。定義後、for文を用いてHTMLドキュメントを表すhtml 5 lib解析ツリーオブジェクトであるtreeに対し(.)ドット演算子を用いてiter()を使用します。このメソッドは、解析ツリー内のすべての要素に対するイテレータを返すメソッドです(html 5 libライブラリによって提供)。よって、ツリー内の各要素をfor文で繰り返し処理し、element変数に格納していきます。
格納後、for文内でif文を用いて、要素のtext属性が存在し、空でないかどうかをチェック(if element.text and element.text.strip())。テキストコンテンツが存在する場合、strip ()メソッドが呼び出されて先頭または末尾の空白文字が削除され、生成されたテキストはappend () メソッドを使用してtext_contentに格納されます。
格納後、最後にprint()でtext_content内の情報を出力します。
■実行・検証
このコード(セル)を保存し、Google Colaboratory上で、セルを実行してみます。
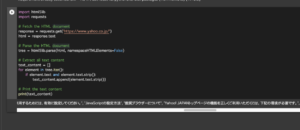
実行してみると、html5libとrequestsを用いて、今回指定したWebサイト(Yahoo!Japan)のテキストコンテンツを抽出。抽出後、テキストコンテンツを出力することができました。

コメント