
Pythonを使用してExcelファイルを変換したPDFファイルのテーブルデータを読み取り・抽出してみます。
PDFファイルのテーブルデータを読み取り・抽出してするためには、tabulaモジュールを事前にPythonにインストールしておく必要があります。
なお、tabulaモジュールを使う際は、Javaのインストール、Javaに必要な環境変数と設定を行う必要があります。これを行わないと「JavaNotFoundError: java command is not found from this Python process.Please ensure Java is installed and PATH is set for java」というエラーが発生します。
■Python
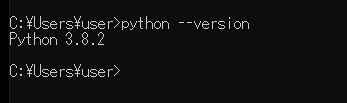
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■tabulaモジュールのインストール
tabulaモジュールのインストールをインストールするために、Windowsのコマンドプロンプトを起動します。
pip install tabula-py
起動後、上記のコマンドを入力し、Enterキーを押します。
Collecting tabula-py
Downloading tabula_py-2.2.0-py3-none-any.whl (11.7 MB)
|████████████████████████████████| 11.7 MB 6.4 MB/s
Collecting numpy
Downloading numpy-1.19.4-cp38-cp38-win_amd64.whl (13.0 MB)
|████████████████████████████████| 13.0 MB 3.2 MB/s
Collecting pandas>=0.25.3
Downloading pandas-1.1.4-cp38-cp38-win_amd64.whl (8.9 MB)
|████████████████████████████████| 8.9 MB 3.3 MB/s
Collecting distro
Downloading distro-1.5.0-py2.py3-none-any.whl (18 kB)
Collecting python-dateutil>=2.7.3
Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB)
|████████████████████████████████| 227 kB 3.3 MB/s
Collecting pytz>=2017.2
Downloading pytz-2020.4-py2.py3-none-any.whl (509 kB)
|████████████████████████████████| 509 kB 6.4 MB/s
Collecting six>=1.5
Downloading six-1.15.0-py2.py3-none-any.whl (10 kB)
Installing collected packages: numpy, six, python-dateutil, pytz, pandas, distro, tabula-py
Successfully installed distro-1.5.0 numpy-1.19.4 pandas-1.1.4 python-dateutil-2.8.1 pytz-2020.4 six-1.15.0 tabula-py-2.2.0
Enterキーを押すと、インストールが開始されます。しばらくすると「Successfully installed」と表示されますので、これが表示されれば、正常にインストールは完了となります。
■Excelファイルを変換したPDFファイルを用意する
インストールは完了しましたので、次にテーブルデータを読み取り・抽出するためのPDFファイルを用意します。
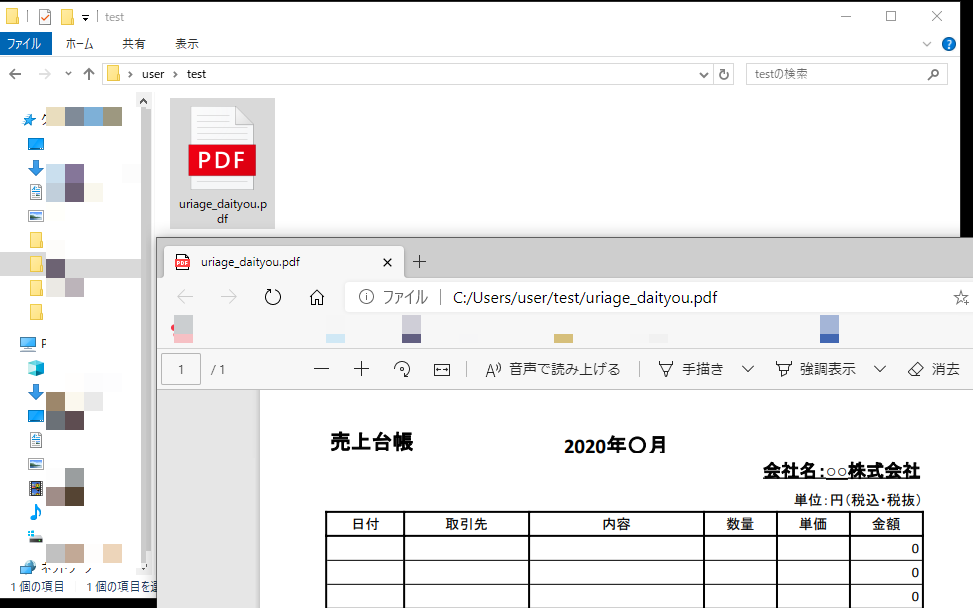
今回は、売上台帳のExcelファイルを変換したPDFファイルを用意しました。
保存場所は「C:\Users\user\test(フォルダパス)」となっています。
■tabulaモジュールを使用しPDFファイルのテーブルデータを読み取り・抽出する
PDFファイルが用意できましたので、tabulaモジュールを使用しPDFファイルのテーブルデータを読み取り・抽出するスクリプトを書いていきます。
■コード
import tabula file = r"C:\Users\user\test\uriage_daityou.pdf" tables = tabula.read_pdf(file, pages="all", multiple_tables=True) print(tables)
インポートでtabulaモジュールを呼び出して、fileという変数を作成し、中に今回用意したPDFファイルを指定します。
指定した後は、tablesという変数を作成し、tabula.read_pdf()で、第1の引数に今回用意したPDFファイルを指定し、第2の引数で「pages=”all”」と記述し、PDFファイルの全てのページを読み取ります。第3の引数で、multiple_tables(複数のテーブル)を「True」に設定します。
その後、読み取ったデータをprint関数で出力します。
■実行
今回の書いたスクリプトを「pdf_data_reading.py」というファイルで保存し、コマンドプロンプトから実行してみます。

実行してみると、今回用意したPDFファイルのテーブルデータが読み取り出力できることを確認できました。

コメント