
PythonでMicrosoft Word文書を読み取ってみます。
Microsoft Word文書を読み取るためには、python-docxモジュールが必要となりますので、事前にインストールしておく必要があります。
■Python
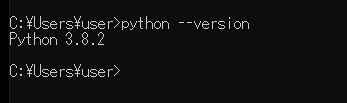
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■テストでMicrosoft Wordファイル(.docxファイル)を用意する
それでは、PythonでMicrosoft Word文書を読み取っていきたいと思いますので、まずはテスト用のMicrosoft Wordファイル(.docxファイル)を用意します。
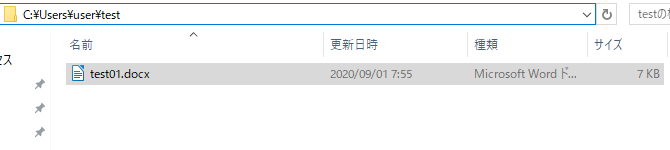
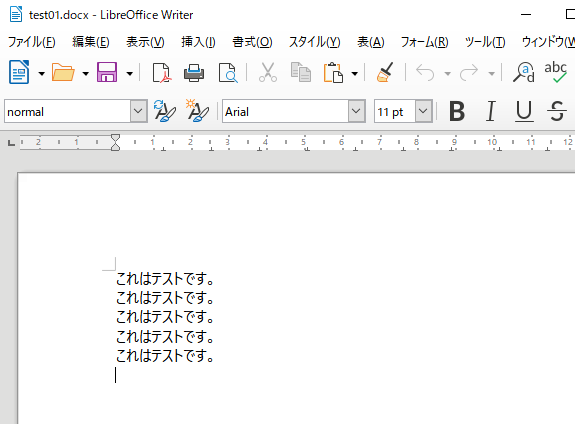
今回は「test01.docx」という上記のMicrosoft Wordファイル(.docxファイル)を用意しました。ファイルの保存先は「C:\Users\user\test(フォルダパス)」となります。
■python-docxモジュールを使ってMicrosoft Wordファイル(.docxファイル)を読み取る
Microsoft Wordファイル(.docxファイル)が用意できましたので、python-docxモジュールを使ってMicrosoft Wordファイル(.docxファイル)を読み取るスクリプトを書いていきます。
■コード
import docx
doc = docx.Document(r'C:\Users\user\test\test01.docx')
txt = []
for para in doc.paragraphs:
txt.append(para.text)
print(txt)python-docxモジュール(docx)をインポートして、docx.Document()で今回用意したMicrosoft Wordファイル(.docxファイル)を指定して開きます。
txt変数で、Microsoft Wordファイル内の各段落の文書を格納します。
そして、Microsoft Wordファイル内の各段落を通過し、各段落ごとの文書を追加するfor文によるループ処理を作成し、文書のすべての取得します。
取得後、append()で取得した文書のすべてをtxtに格納して結合します。
■実行
今回書いたスクリプトを、「docx-read.py」という名前で保存し、コマンドプロンプトから実行してみます。
![]()
実行してみると、今回用意したMicrosoft Wordファイル(.docxファイル)の中身が取得されて出力されたことを確認できました。

コメント