
Pythonでwaybackpyを用いて指定したWebサイトで古いページを取得してみます。
今回は、waybackpyを用います。このライブラリ・モジュールはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■waybackpyを用いて指定したWebサイトで古いページを取得する
では、早速waybackpyを用いて指定したWebサイトで古いページを取得するスクリプトを書いていきます。
■コード
from waybackpy import WaybackMachineAvailabilityAPI url = "https://laboratory.kazuuu.net/" user_agent = "Mozilla/5.0 (Windows NT 5.1; rv:40.0) Gecko/20100101 Firefox/40.0" availability_api = WaybackMachineAvailabilityAPI(url, user_agent) print(availability_api.oldest())
「from import」でwaybackpyのWaybackMachineAvailabilityAPIを呼び出します。
その後、url変数を定義し、その中に古いページを取得したいWebサイトのURLを格納します。
格納後、user_agent変数を定義し、その中にユーザーエージェントを格納します。
さらにavailability_api変数を定義し、その中でWaybackMachineAvailabilityAPI()を用います。括弧内には、第1の引数,パラメータとしてurl変数を渡します。そして第2の引数,パラメータとしてuser_agent変数を渡します。これでAPIにWebサイトの情報が渡され、WaybackMachineAvailabilityAPI内の保存されている情報が返されます。
最後にavailability_api.oldest()を用いて、古いページを取得し、print()で出力します。
■実行・検証
このスクリプトを「web_old.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
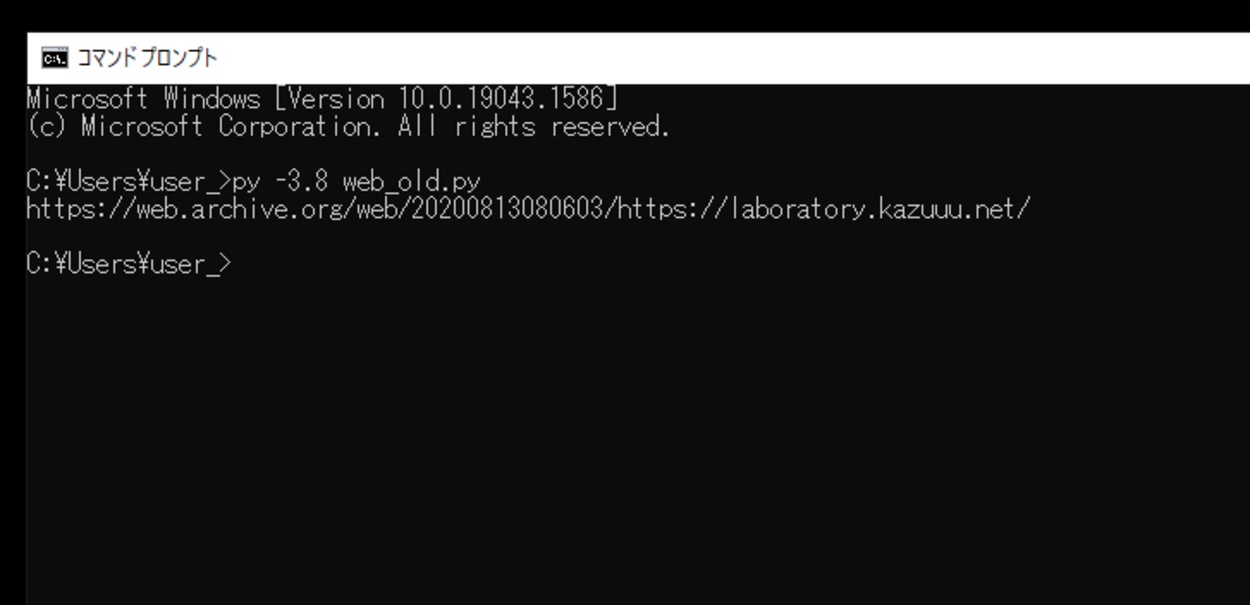
実行してみると、waybackpyを用いて「Wayback Machine – Internet Archive(http://web.archive.org/)」から今回指定したWebサイトの古いページを出力させることができました。

コメント