
Node.jsとPuppeteerを使ってWebサイトをスクレイピングしてみます。
なお、JavaScriptの実行にはNode.jsとnpm(Node Package Manager)を使用するので、コンピュータにNode.jsとnpmがインストールされている必要があります。
■PC環境
・Windows10、Administrator(管理者)アカウント
・node –version v14.15.0
・npm –version 6.14.8
■Web Scraperの設定
Web Scraperの設定のために、プロジェクト用のフォルダを作成しますので、Windows10の検索ボックスで「cmd」と入力し、コマンドプロンプトをクリックします。クリックすると、コマンドプロンプトが起動します。
C:\Users\Administrator>mkdir web-scraper
起動後、上記のコマンドを入力し、今回は「web-scraper」というフォルダを作成します。作成のために、エンターキーを押します。
C:\Users\Administrator>cd web-scraper
押した後に、上記のコマンドを入力し、「web-scraper」というフォルダ内に移動します。移動のためにエンターキーを押します。
押した後に、npm(node package manager)を使用し、パッケージをインストールします。その前に、プロジェクトの依存関係やメタデータを管理するpackages.jsonファイルを作成するために、npmを初期化します。
C:\Users\Administrator\web-scraper>npm init
初期化のために、上記のコマンドを入力し、エンターキーを押します。
This utility will walk you through creating a package.json file. It only covers the most common items, and tries to guess sensible defaults. See `npm help init` for definitive documentation on these fields and exactly what they do. Use `npm install ` afterwards to install a package and save it as a dependency in the package.json file. Press ^C at any time to quit. package name: (web-scraper)
エンターキーを押すと、上記のメッセージが表示されます。「package name: (web-scraper)」と表示されていますので、フォルダの名前である「web-scraper」と入力します。その後、エンターキーを押します。
version: (1.0.0)
エンターキーを押すと、バージョンが表示されていますので、エンターキーを押します。今回は1.0.0をインストールします。
description:
エンターキーを押すと、「description:(説明)」と表示されますので、今回は「a web scraper」を入力し、エンターキーを押します。
entry point: (index.js)
エンターキーを押すと、「entry point: (index.js)」と表示されていますので、エンターキーを押します。
test command:
エンターキーを押すと、「test command:」と表示されていますので、エンターキーを押します。
git repository:
エンターキーを押すと、「git repository:」と表示されていますので、エンターキーを押します。
keywords:
エンターキーを押すと、「keywords:」と表示されていますので、エンターキーを押します。
author:
エンターキーを押すと、「author:」と表示されていますので、エンターキーを押します。
license: (ISC)
エンターキーを押すと、「license: (ISC)」と表示されていますので、エンターキーを押します。
{
"name": "web-scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Is this OK? (yes)エンターキーを押すと、作成したpackages.jsonファイルの内容が表示されていますので、確認し、「y」と入力し、エンターキーを押します。
C:\Users\Administrator\web-scraper>npm install --save puppeteer
エンターキーを押した後に、npmを使用し、Puppeteerをインストールしますので、上記のコマンドを入力し、エンターキーを押します。
> puppeteer@8.0.0 install C:\Users\Administrator\web-scraper\node_modules\puppeteer > node install.js Downloading Chromium r856583 - 164.6 Mb [====================] 100% 0.0s Chromium (856583) downloaded to C:\Users\Administrator\web-scraper\node_modules\puppeteer\.local-chromium\win64-856583 npm notice created a lockfile as package-lock.json. You should commit this file. npm WARN web-scraper@1.0.0 No repository field. + puppeteer@8.0.0 added 54 packages from 73 contributors and audited 54 packages in 92.698s 8 packages are looking for funding run `npm fund` for details found 0 vulnerabilities
エンターキーを押すと、ダウンロードが開始され、インストールが始まります。しばらくすると、インストールが完了します。
インストール後、「C:\Users\Administrator\(フォルダパス)」の「web-scraper」のフォルダにあるpackage.jsonのファイルをコードエディタを開き、編集します。
■コード
{
"name": "web-scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^8.0.0"
}
}package.jsonのファイルの「”scripts”」の部分に「”start”: “node index.js”」と記述します。記述後、保存します。
npm ERR! missing script: start npm ERR! A complete log of this run can be found in: npm ERR! C:\Users\Administrator\AppData\Roaming\npm-cache\_logs\2021-04-08T01_28_15_781Z-debug.log
なお、この記述がない場合は、アプリケーションを実行した際に上記のエラーが発生します。
■jsファイルの作成
保存後、web scraperには、browser.js、index,js、pageController.js、pageScraper.jsという4つのjsファイルが必要ですので、「C:\Users\Administrator\(フォルダパス)」の「web-scraper」のフォルダ内に作成します。これを作成することで、web scraperのブラウザインスタンスを設定し、起動すると、自動的にChromiumを開き、Webスクレイピングできるようになります。
コードエディタを開き、下記のコードを記述し、jsファイルを作成していきます。作成後、ファイルを保存します。
■browser.js
const puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};■index.js
const browserObject = require('./browser');
const scraperController = require('./pageController');
//ブラウザを起動しブラウザインスタンスを作成
let browserInstance = browserObject.startBrowser();
// ブラウザのインスタンスをスクレーパーコントローラーに渡す
scraperController(browserInstance)■pageController.js
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)■pageScraper.js
const scraperObject = {
url: 'https://www.yahoo.co.jp/',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;なお、今回は自動でChromiumを開き、Webサイトへアクセスしますが、pageScraper.jsのファイルで「url: ‘https://www.yahoo.co.jp/’」と指定して、Yahoo!Japanへアクセスしてみます。
■今回のプログラムのファイル構造
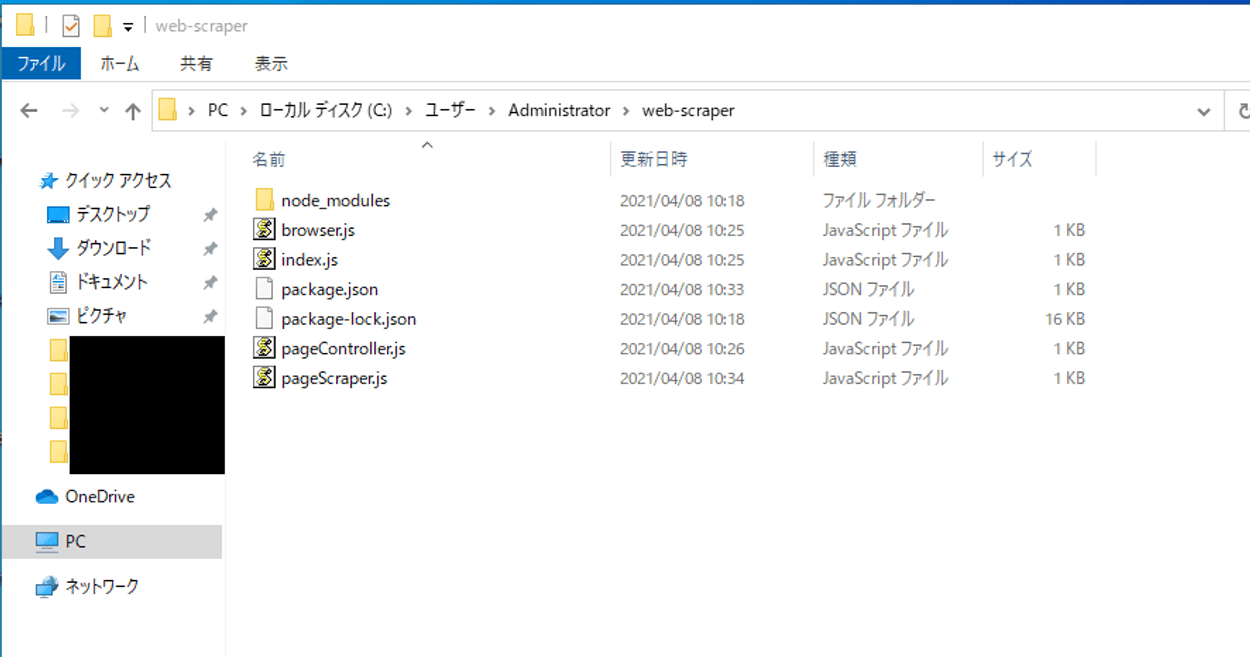
■Web scraperアプリケーションの実行
すべてのjsファイルの作成が完了後、Web scraperアプリケーションを実行してみます。
実行する場合は、Windows10の検索ボックスで「cmd」と入力し、コマンドプロンプトをクリックします。クリックすると、コマンドプロンプトが起動します。
C:\Users\Administrator\web-scraper>npm run start
起動後、上記のコマンドを入力し、アプリケーションを実行します。実行のため、エンターキーを押します。
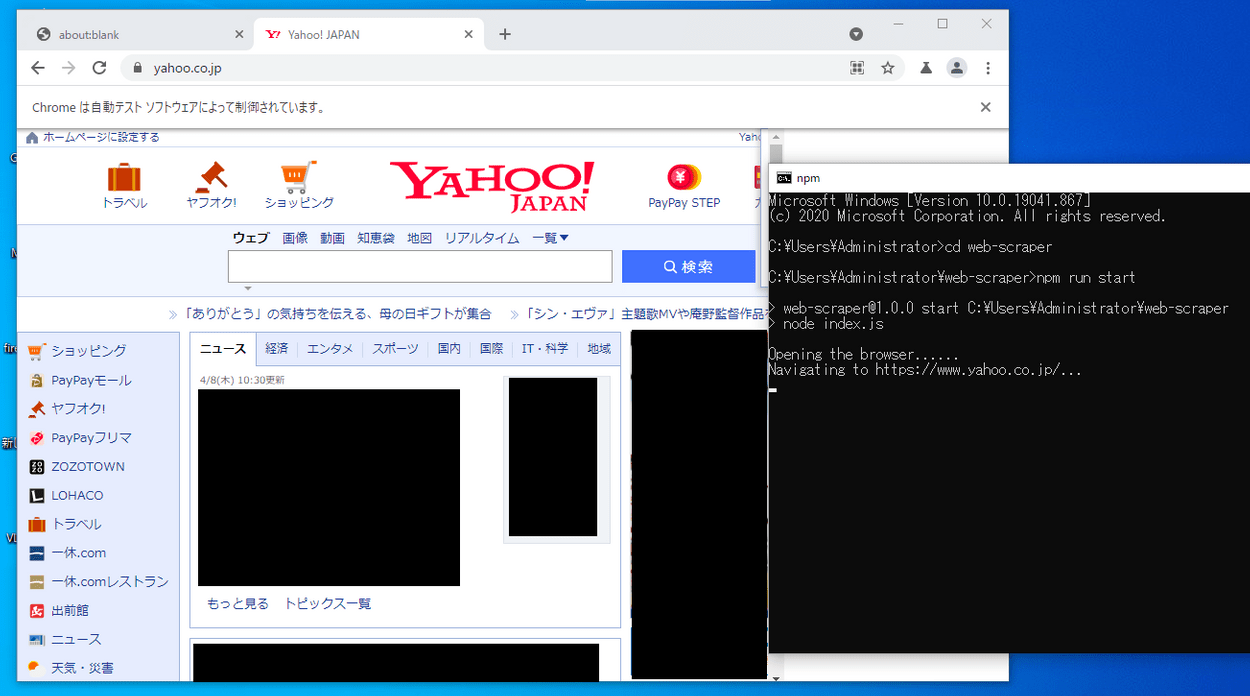
> web-scraper@1.0.0 start C:\Users\Administrator\web-scraper > node index.js Opening the browser...... Navigating to https://www.yahoo.co.jp/...
エンターキーを押すと、上記のメッセージが表示され、自動でChromiumを開きます。Chromiumには「Chromeは自動テストソフトウェアによって制御されています。」と表示されています。表示された状態で今回指定したYahoo!Japan(https://www.yahoo.co.jp/)にアクセスし、サイトが表示されることを確認できました。

コメント